
Prometheus ingestion errors
There are a few places to look for problems and errors when sending metrics to Grafana Cloud.
- The Grafana Cloud Billing and Usage dashboard available by default and shows ingest errors.
- The Grafana Cloud Metrics Ingestion dashboard is also available by default and shows ingestion errors for samples, exemplars, and metadata. This is our recommend approach for debugging ingestion errors.
- Both Prometheus and Grafana Alloy log errors, and have metrics you can look out for. We recommend starting with the Grafana Cloud Metrics Ingestion dashboard because certain ingestion errors aren’t written in the Prometheus and Grafana Alloy logs.
Problems and solutions are described below.
Billing and Usage dashboard
The bottom-right graph shows Discarded Samples aggregated by reason.
It queries the metric grafanacloud_instance_samples_discarded from the grafanacloud-usage data source.
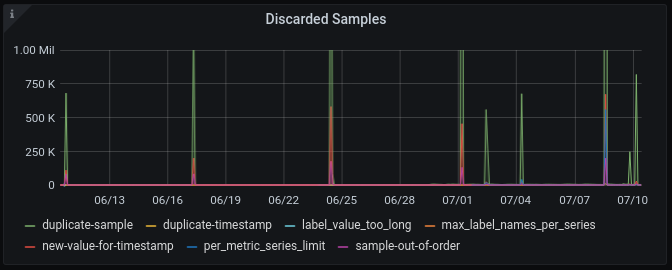
This graph can help you detect problems, but sometimes you need to investigate further to locate the source of an issue. For example, the dashboard doesn’t show series reporting 0 discarded samples. To learn more about the reasons for discarded samples, refer to Ingest problems.
If you are hitting rate limits or number limits, contact Grafana Labs support.
Refer to Usage monitoring for more information about the Grafana Cloud Billing/Usage dashboard.
Metrics Ingestion dashboard
The Metrics Ingestion dashboard shows you the rate of successful sample ingestion as well as the rate of samples discarded due to ingestion failures. It also surfaces error messages to help you understand which samples are failing to be ingested and why.
It uses following metrics from the grafanacloud-usage data source:
- Ingested samples:
grafanacloud_instance_samples_per_second - Discarded samples:
grafanacloud_instance_samples_discarded_per_second - Ingested exemplars:
grafanacloud_instance_exemplars_per_second - Discarded exemplars:
grafanacloud_instance_exemplars_discarded_per_second - Ingested metadata:
grafanacloud_instance_metadata_per_second - Discarded metadata:
grafanacloud_instance_metadata_discarded_per_second
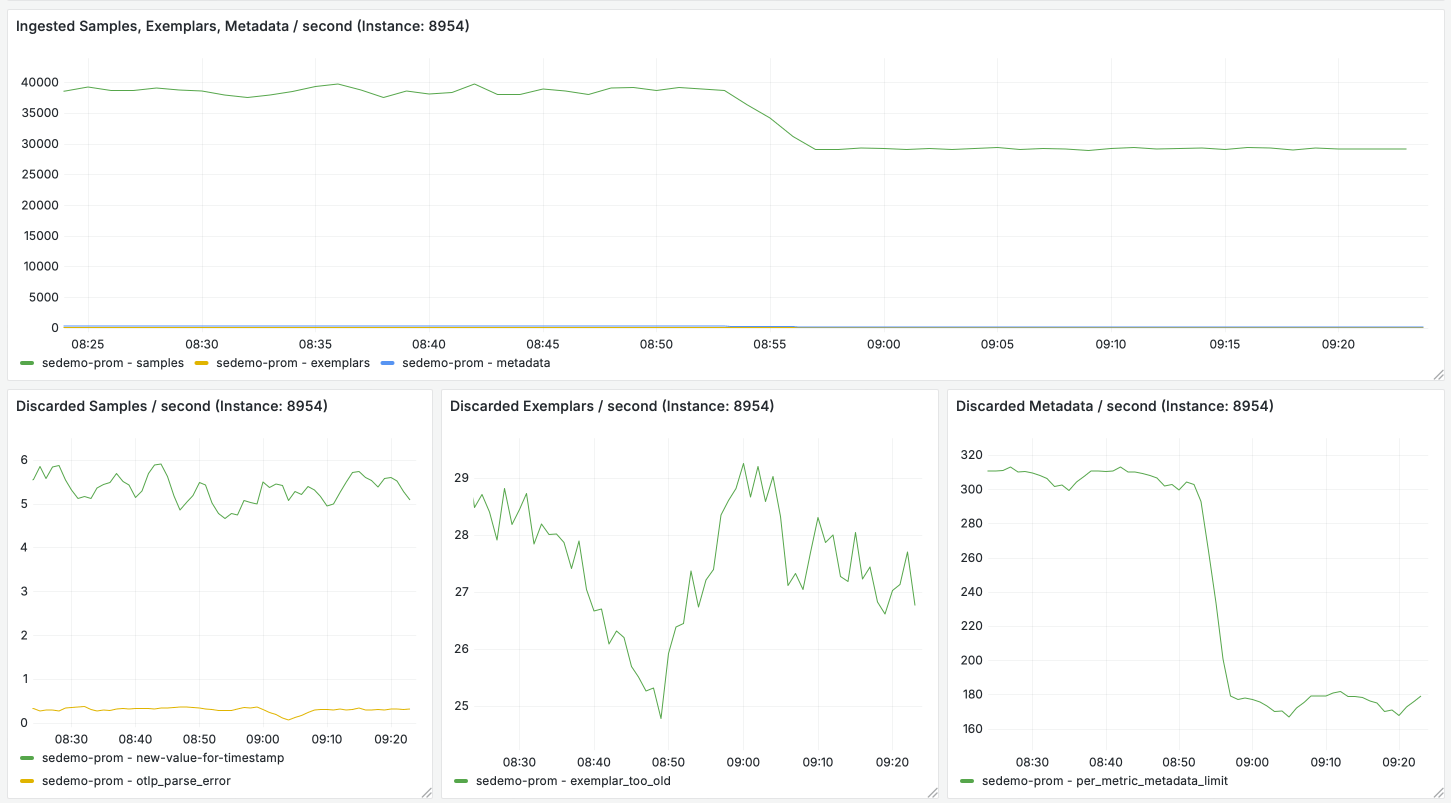
The Ingestion Error Details panel shows error messages for failed ingestion, split by selected Hosted Metrics instance.
You can set up Grafana-managed alerts to query these metrics from the grafanacloud-usage and send yourself a notification when discard rate exceeds acceptable levels.
Alerting on the condition below notifies you if some of your samples are being discarded because you’ve exceeded the number of active time series allowed in your Hosted Metrics instance.
grafanacloud_instance_samples_discarded_per_second{reason="per_user_series_limit"} > 0If you are using Adaptive Metrics, you may also want to alert on the following condition. This notifies you that some of your samples are being discarded because you’re sending too many samples to Adaptive Metrics for aggregation.
grafanacloud_instance_samples_discarded_per_second{reason=~"aggregator-too-many-raw-series|aggregator-too-many-aggregated-series"} > 0Grafana Cloud automatically scales up in response to increases in your traffic, but this scaling happens gradually. If you’re seeing a high volume of samples continue to be discarded due to the per_user_series_limit, aggregator-too-many-raw-series, and aggregator-too-many-aggregated-series reasons please contact Support.
Prometheus internal metrics
Prometheus exposes internal metrics on its /metrics endpoint on port 9090 by default.
Make sure to configure Prometheus to monitor itself.
For more information, refer to Configuring Prometheus to monitor itself.
The metrics to look and configure alerts for are:
There are also some metrics from the go-conntrack library for monitoring HTTP connections.
Prometheus logs
There are small logs recording remote_write activity in Prometheus logs.
Prometheus logs requests with failed authentication, but exposes other problems through internal metrics.
Ingest problems
You may face some issues when sending metrics to Grafana Cloud. For example, hitting some limits or getting failed authentication errors. This section explains the most common errors you may encounter and how to fix them.
Per-user series limit
The default active series limit per user is 150k. This is mostly to protect the cloud platform against misconfigured clients. If you receive an email notification that you have reached your account limit and you need a limit increase, contact support.
Max label names per series
You may set up to 40 label names per series. However, Grafana Labs recommends setting fewer than 30 to prevent performance problems.
Greater than max sample age
Grafana Cloud rejects samples older than one hour with an “out of bounds” error.
Rate limited
There is a soft cap at 25,000 data points per seconds. This is mostly to protect the cloud platform against misconfigured clients. Grafana Labs support can increase this limit.
Failed authentication
This error doesn’t show up on the Discarded Samples graph,
but you can detect it by monitoring Prometheus logs or the internal metric prometheus_remote_storage_failed_samples_total.
The following is a sample Prometheus client error log message for an invalid token.
Ensure you have the correct scope, metrics:write, and a realm for the stack you want to write metrics to:
ts=2020-06-30T17:25:45.255Z caller=dedupe.go:112 component=remote level=error remote_name=c78ed9 url=https://prometheus-us-central1.grafana.net/api/prom/push msg="non-recoverable error" count=100 err="server returned HTTP status 401 Unauthorized: {\"status\": \"error\", \"error\": \"Invalid token\"}"Slow requests
Grafana Cloud enforces a maximum time allowed to receive the HTTP request body. This timeout is enforced for any request, including Prometheus requests to write metrics to Grafana Cloud, and is used to protect the system from abuse. The default timeout is long enough to give clients the time to send the request, and it shouldn’t be reached in normal conditions.
In the event a client is very slow sending the HTTP request body, or it hangs while sending the request, and the timeout is reached, Grafana Cloud returns the custom HTTP status code 598.
Was this page helpful?
Related resources from Grafana Labs


