
This is documentation for the next version of Grafana documentation. For the latest stable release, go to the latest version.
Query and transform data
Grafana supports many types of data sources. Data source queries return data that Grafana can transform and visualize. Each data source uses its own query language, and data source plugins each implement a query-building user interface called a query editor.
About queries
Grafana panels communicate with data sources via queries, which retrieve data for the visualization. A query is a question written in the query language used by the data source.
You can configure query frequency and data collection limits in the panel’s data source options. Grafana supports up to 26 queries per panel.
Important: You must be familiar with a data source’s query language. For more information, refer to Data sources.
Query editors
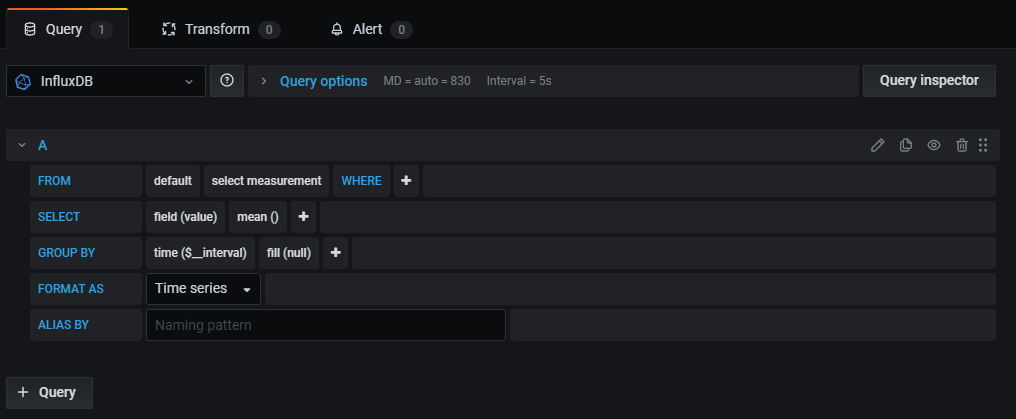
Each data source’s query editor provides a customized user interface that helps you write queries that take advantage of its unique capabilities.
Because of the differences between query languages, each data source query editor looks and functions differently. Depending on your data source, the query editor might provide auto-completion features, metric names, variable suggestions, or a visual query-building interface.
For example, this video demonstrates the visual Prometheus query builder:
There’s supposed to be a video here, but for some reason there isn’t. Either we entered the id wrong (oops!), or Vimeo is down. If it’s the latter, we’d expect they’ll be back up and running soon. In the meantime, check out our blog!
There’s supposed to be a video here, but for some reason there isn’t. Either we entered the id wrong (oops!), or Vimeo is down. If it’s the latter, we’d expect they’ll be back up and running soon. In the meantime, check out our blog!
For details on a specific data source’s unique query editor features, refer to its documentation:
- For data sources included with Grafana, refer to Built-in core data sources, which links to each core data source’s documentation.
- For data sources installed as plugins, refer to its own documentation.
- Data source plugins in Grafana’s plugin catalog link to or include their documentation in their catalog listings. For details about the plugin catalog, refer to Plugin management.
- For links to Grafana Enterprise data source plugin documentation, refer to the Enterprise plugins index.
Query syntax
Each data source uses a different query languages to request data. For details on a specific data source’s unique query language, refer to its documentation.
PostgreSQL example:
SELECT hostname FROM host WHERE region IN($region)PromQL example:
query_result(max_over_time(<metric>[${__range_s}s]) != <state>)Special data sources
Grafana also includes three special data sources: Grafana, Mixed, and Dashboard. For details, refer to Data sources
Navigate the Query tab
A panel’s Query tab consists of the following elements:
- Data source selector: Selects the data source to query. For more information about data sources, refer to Data sources.
- Query options: Sets maximum data retrieval parameters and query execution time intervals.
- Query inspector button: Opens the query inspector panel, where you can view and optimize your query.
- Query editor list: Lists the queries you’ve written.
- Expressions: Uses the expression builder to create alert expressions. For more information about expressions, refer to Use expressions to manipulate data.
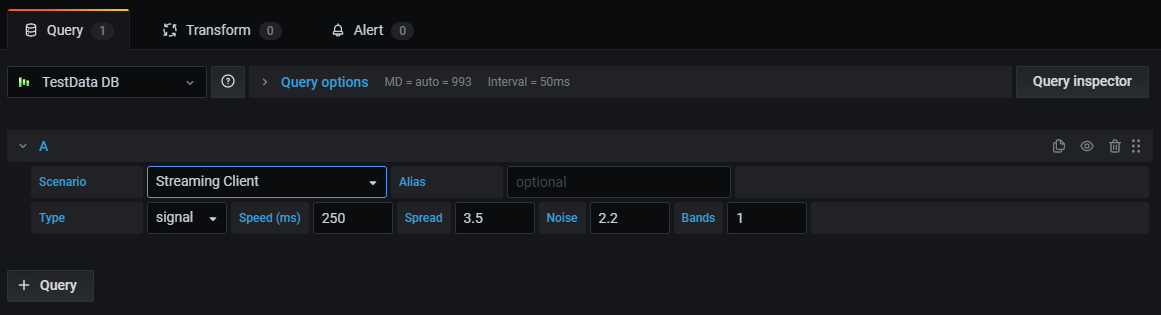
Add a query
A query returns data that Grafana visualizes in dashboard panels. When you create a panel, Grafana automatically selects the default data source.
To add a query:
Edit the panel to which you’re adding a query.
Click the Query tab.
Click the Data source drop-down menu and select a data source.
If you’re creating a new dashboard, you’ll be prompted to select a data source when you add the first panel.
Click Query options to configure the maximum number of data points you need. For more information about query options, refer to Query options.
Write the query using the query editor.
Click Apply.
Grafana queries the data source and visualizes the data.
Manage queries
Grafana organizes queries in collapsible query rows. Each query row contains a query editor and is identified with a letter (A, B, C, and so on).
You can:
| Icon | Description |
|---|---|
 | Toggles query editor help. If supported by the data source, click this icon to display information on how to use the query editor or provide quick access to common queries. |
| Copies a query. Duplicating queries is useful when working with multiple complex queries that are similar and you want to either experiment with different variants or do minor alterations. | |
| Hides a query. Grafana does not send hidden queries to the data source. | |
| Removes a query. Removing a query permanently deletes it, but sometimes you can recover deleted queries by reverting to previously saved versions of the panel. | |
| Reorders queries. Change the order of queries by clicking and holding the drag icon, then drag queries where desired. The order of results reflects the order of the queries, so you can often adjust your visual results based on query order. |
Query options
Click Query options next to the data source selector to see settings for the selected data source. Changes you make here affect only queries made in this panel.
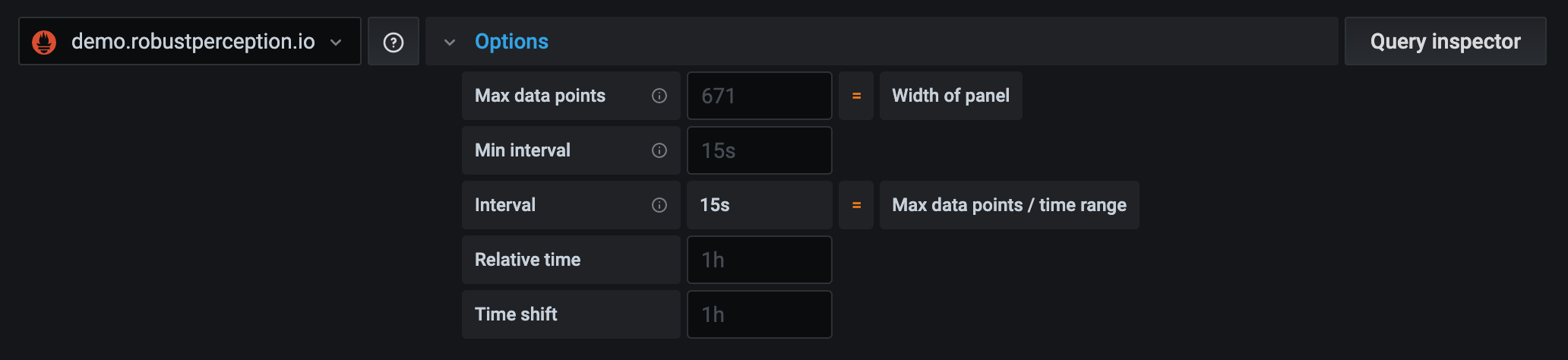
Grafana sets defaults that are shown in dark gray text. Changes are displayed in white text. To return a field to the default setting, delete the white text from the field.
Panel data source query options include:
Max data points: If the data source supports it, this sets the maximum number of data points for each series returned. If the query returns more data points than the max data points setting, then the data source reduces the number of points returned by aggregating them together by average, max, or another function.
You can limit the number of points to improve query performance or smooth the visualized line. The default value is the width (or number of pixels) of the graph, because you can only visualize as many data points as the graph panel has room to display.
With streaming data, Grafana uses the max data points value for the rolling buffer. Streaming is a continuous flow of data, and buffering divides the stream into chunks. For example, Loki streams data in its live tailing mode.
Min interval: Sets a minimum limit for the automatically calculated interval, which is typically the minimum scrape interval. If a data point is saved every 15 seconds, you don’t benefit from having an interval lower than that. You can also set this to a higher minimum than the scrape interval to retrieve queries that are more coarse-grained and well-functioning.
Note
The Min interval corresponds to the min step in Prometheus. Changing the Prometheus interval can change the start and end of the query range because Prometheus aligns the range to the interval. Refer to Min step for more details.
Interval: Sets a time span that you can use when aggregating or grouping data points by time.
Grafana automatically calculates an appropriate interval that you can use as a variable in templated queries. The variable is measured in either seconds (
$__interval) or milliseconds ($__interval_ms).Intervals are typically used in aggregation functions like sum or average. For example, this is a Prometheus query that uses the interval variable:
rate(http_requests_total[$__interval]).This automatic interval is calculated based on the width of the graph. As the user zooms out on a visualization, the interval grows, resulting in a more coarse-grained aggregation. Likewise, if the user zooms in, the interval decreases, resulting in a more fine-grained aggregation.
For more information, refer to Global variables.
Relative time: Overrides the relative time range for individual panels, which causes them to be different than what is selected in the dashboard time picker in the top-right corner of the dashboard. You can use this to show metrics from different time periods or days on the same dashboard.
Note: Panel time overrides have no effect when the dashboard’s time range is absolute.
With Grafana Play, you can explore and see how it works, learning from practical examples to accelerate your development. This feature can be seen on Time range override.
Time shift: Overrides the time range for individual panels by shifting its start and end relative to the time picker. For example, you can shift the time range for the panel to be two hours earlier than the dashboard time picker.
Note: Panel time overrides have no effect when the dashboard’s time range is absolute.
Cache timeout: (Visible only if available in the data source) Overrides the default cache timeout if your time series store has a query cache. Specify this value as a numeric value in seconds.
Was this page helpful?
Related resources from Grafana Labs


