
This is documentation for the next version of Grafana Tempo documentation. For the latest stable release, go to the latest version.
TraceQL metrics functions
Caution
TraceQL metrics is an public preview feature. Grafana Labs offers limited support, and breaking changes might occur prior to the feature being made generally available TraceQL metrics are enabled by default in Grafana Cloud.
TraceQL metrics query functions are aggregate operators that can be appended to any TraceQL span selector to compute time-series metrics directly from trace data. You can answer questions about system behavior by aggregating trace data on-the-fly.
Available functions
TraceQL supports rate, count_over_time, sum_over_time, min_over_time, avg_over_time, quantile_over_time,
histogram_over_time, and compare functions. These methods can be appended to any TraceQL query to calculate and
return the desired metrics like:
{} | rate()Note that topk and bottomk are also supported to only return a subset of series. These can only be added
after a metrics query like:
{} | rate() by (resource.service.name) | topk(10)You can also apply comparison operators to metrics results to keep only data points that meet a given threshold. These can be added after a metrics query like:
{} | rate() by (resource.service.name) > 10These functions can be added as an operator at the end of any TraceQL query.
Group results with by()
You can use the optional by() clause with metrics functions in TraceQL metrics queries to group aggregated results by specified span attributes like service name, endpoint, or status.
Without by(), you get a single aggregated value across all matching spans.
{ span:status = error } | rate()With by(), you get separate time series for each unique combination of the grouped attributes.
{ span:status = error } | rate() by(resource.service.name)The rate function
The rate function calculates the number of matching spans per second that match the given span selectors.
The following query shows the rate of errors by service and span name. This is a TraceQL specific way of gathering rate metrics that would otherwise be generated by the span metrics processor.
For example, this query:
{ span:status = error } | rate() by (resource.service.name, span:name)Is an equivalent to using span-generated metrics and running the query.
This example calculates the rate of the erroring spans coming from the service foo.
Rate is a spans/sec quantity.
{ resource.service.name = "foo" && span:status = error } | rate()Combined with the by() operator, this can be even more powerful.
{ resource.service.name = "foo" && span:status = error } | rate() by (span.http.route)This example still rates the erroring spans in the service foo but the metrics are broken
down by HTTP route.
This might let you determine that /api/sad had a higher rate of erroring
spans than /api/happy, for example.
The count_over_time function
The count_over_time() function counts the number of matching spans per time interval.
The time interval that the count is computed over is set by the step parameter.
The step parameter
The step parameter defines the granularity of the returned time-series.
For example, step=15s returns a data point every 15s within the time range.
By default, step automatically chooses a dynamic value based on the query start time and end time.
Any value used for step needs to include a duration value, such as 30s for seconds or 1m for minutes.
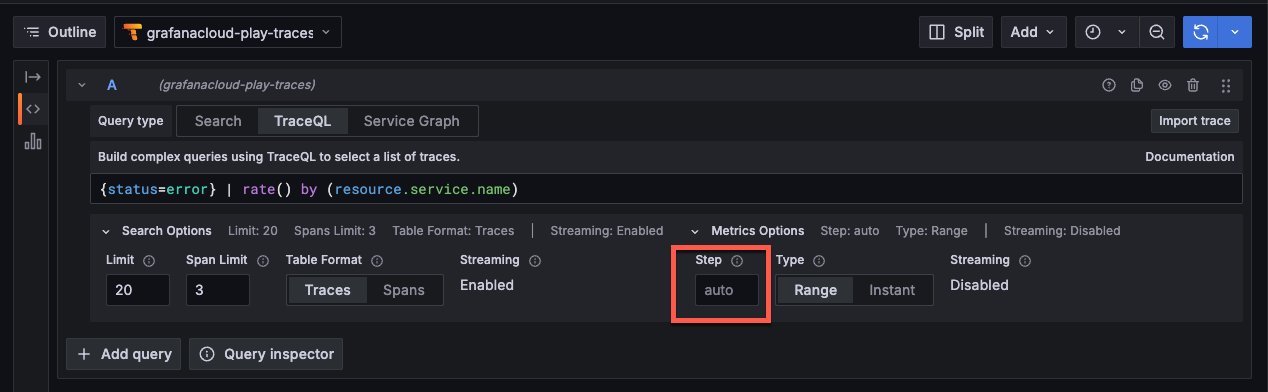
You can configure this parameter using Grafana Explore or using the Tempo API.
To check or change the step value using Grafana Explore:
- Select your Tempo data source.
- Select either the Search or TraceQL query type tab.
- Expand the Metrics options to view the Step value.
This example counts the number of spans with name "GET /:endpoint" broken down by status code. You might see that
there are 10 "GET /:endpoint" spans with status code 200 and 15 "GET /:endpoint" spans with status code 400.
{ span:name = "GET /:endpoint" } | count_over_time() by (span.http.status_code)Over-time functions
The over-time functions let you aggregate numerical values across matching spans per time interval.
The time interval that these functions compute over is set by the step parameter.
For more information, refer to the
step API parameter.
These functions accept the numerical field that you want to aggregate on.
The sum_over_time function
The sum_over_time() function lets you aggregate numerical values by computing the sum value of them.
The time interval that the sum is computed over is set by the step parameter.
The min_over_time function
The min_over_time() function lets you aggregate numerical attributes by calculating their minimum value.
For example, you could choose to calculate the minimum duration of a group of spans, or you could choose to calculate
the minimum value of a custom attribute you’ve attached to your spans, like span.shopping.cart.entries.
The time interval that the minimum is computed over is set by the step parameter.
This example computes the minimum duration for each http.target of all spans named "GET /:endpoint".
Any numerical attribute on the span is fair game.
{ span:name = "GET /:endpoint" } | min_over_time(span:duration) by (span.http.target)This example computes the minimum status code value of all spans named "GET /:endpoint".
{ span:name = "GET /:endpoint" } | min_over_time(span.http.status_code)The max_over_time function
The max_over_time() function lets you aggregate numerical values by computing the maximum value of them, such as the all
important span duration.
The time interval that the maximum is computed over is set by the step parameter.
This example computes the maximum duration for each http.target of all spans named "GET /:endpoint".
{ span:name = "GET /:endpoint" } | max_over_time(span:duration) by (span.http.target){ span:name = "GET /:endpoint" } | max_over_time(span.http.response.size)The avg_over_time function
The avg_over_time() function lets you aggregate numerical values by computing the average value of them, such as the all
important span duration.
The time interval that the average is computed over is set by the step parameter.
This example computes the average duration for each http.status_code of all spans named "GET /:endpoint".
{ span:name = "GET /:endpoint" } | avg_over_time(span:duration) by (span.http.status_code){ span:name = "GET /:endpoint" } | avg_over_time(span.http.response.size)The quantile_over_time function
The quantile_over_time() function lets you aggregate numerical values, such as the all important span duration, by computing quantiles over time.
You can specify multiple quantiles in the same query.
The example below computes the 99th, 90th, and 50th percentile of the duration attribute on all spans with name
GET /:endpoint.
{ span:name = "GET /:endpoint" } | quantile_over_time(span:duration, .99, .9, .5)You can group by any span or resource attribute.
{ span:name = "GET /:endpoint" } | quantile_over_time(span:duration, .99) by (span.http.target)Quantiles aren’t limited to span duration.
Any numerical attribute on the span is fair game.
To demonstrate this flexibility, consider this nonsensical quantile on span.http.status_code:
{ span:name = "GET /:endpoint" } | quantile_over_time(span.http.status_code, .99, .9, .5)This computes the 99th, 90th, and 50th percentile of the values of the status_code attribute for all spans named
GET /:endpoint.
This is unlikely to tell you anything useful (what does a median status code of 347 mean?), but it works.
As a further example, imagine a custom attribute like span.temperature.
You could use a similar query to know what the 50th percentile and 95th percentile temperatures were across all your
spans.
The histogram_over_time function
The histogram_over_time() function lets you evaluate frequency distribution over time for numerical values, such as span duration.
This function groups values into buckets and shows how frequently values fall into each bucket over time.
This example evaluates the frequency distribution of span duration, grouped by HTTP target:
{ } | histogram_over_time(span:duration) by (span.http.target)Multi-stage metrics queries
Multi-stage metrics queries are queries that turn your spans into metrics and then perform additional operations on those metrics.
The topk function
The topk function lets you aggregate and process TraceQL metrics by returning only the top k results.
This function is similar to its equivalent PromQL function.
When a query response is larger than the maximum, you can use topk to return only the specified number
from 1 through k of the top results.
For example:
{ resource.service.name = "foo" } | rate() by (span.http.url) | topk(10)The first part, { resource.service.name = "foo" }, takes all spans in the service foo.
The spans are rated by the URL, for example, the most active endpoints on a service.
Adding topk(10) returns the top 10 most common instead of the entire list.
In TraceQL, topk works similar to how it functions in PromQL.
The topk function is evaluated at each data point.
If you do a topk of 10, you might get a 20 series. For example, on this data point, the top 10 are A through J.
On the next data point, A through I might still be the top 9, but J might have fallen off for K.
Because it’s evaluated at each data point, you’ll get the top series for each data point.
The bottomk function
The bottomk function lets you aggregate and process TraceQL metrics by returning only the bottom k results.
This function is similar to its equivalent PromQL function.
When a query response is larger than the maximum, you can use bottomk to return only the specified number
from 1 through k of the bottom results.
For example:
{ resource.service.name = "foo" } | rate() by (span.http.url) | bottomk(10)The first part, { resource.service.name = "foo" }, takes all spans in the service foo.
The spans are rated by the URL, for example, the least active endpoints on a service.
Adding bottomk(10) returns the bottom 10 least common instead of the entire list.
In TraceQL, bottomk works similar to how it functions in PromQL.
The bottomk function is evaluated at each data point.
If you do a bottomk of 10, you might get a 20 series. For example, on this data point, the bottom 10 are A through J.
On the next data point, A through I might still be the bottom 9, but J might have fallen off for K.
Because it’s evaluated at each data point, you’ll get the bottom series for each data point.
Comparison operators
You can apply comparison operators to the results of any metrics query to keep only the data points that meet a given condition. This lets you filter out noise and focus on the values that matter, for example, only showing series where the rate exceeds a threshold.
The supported comparison operators are >, >=, <, <=, =, and !=.
You can compare against integers, floats, and durations, for example, 1s or 500ms.
Note
Comparison operators aren’t supported with the
compare()function.
Data points that don’t match the condition are removed from the results. If all data points in a series are removed, the entire series is dropped.
For example, this query computes the rate of all spans grouped by service, and then keeps only services where the rate exceeds 10 spans per second:
{} | rate() by (resource.service.name) > 10You can use duration values to filter on time-based metrics. This example finds endpoints where the average span duration is greater than one second:
{ span:name = "GET /:endpoint" } | avg_over_time(span:duration) > 1sTo exclude zero values from your results:
{} | count_over_time() by (name) != 0Combining with topk and bottomk
Comparison operators can be combined with topk and bottomk in any order.
Each operation is applied in sequence from left to right.
For example, you can first select the top 5 series and then filter to only those above a threshold:
{} | rate() by (span.http.url) | topk(5) > 10Or filter first, then select the top results from what remains:
{} | rate() by (span.http.url) > 0 | topk(5)Sampling hints work alongside comparison operators:
{} | count_over_time() by (name) | topk(10) >= 5 with(sample=0.1)Data sampling
TraceQL metrics queries support sampling to optimize performance and control sampling behavior. There are three sampling methods available:
- Dynamic sampling using
with(sample=true), which automatically determines the optimal sampling strategy and amount based on query characteristics. - Fixed sampling using
with(sample=0.xx) - Fixed span sampling using
with(span_sample=0.xx), which selects the specified percentage of spans. - Fixed trace sampling using
with(trace_sample=0.xx), which selects complete traces for analysis.
Refer to the TraceQL metrics sampling documentation for more information.
Note
Sampling hints only work with TraceQL metrics queries (those using functions like
rate(),count_over_time(), etc.).
Dynamic sampling: with(sample=true)
Automatically determines optimal sampling strategy based on query selectivity and data volume.
{ resource.service.name="frontend" } | rate() with(sample=true)Fixed span sampling: with(span_sample=0.xx)
Samples a fixed percentage of spans for span-level aggregations.
{ span:status=error } | count_over_time() with(span_sample=0.1)Fixed trace sampling: with(trace_sample=0.xx)
Samples a fixed percentage of traces for trace-level aggregations.
{ } | count() by (resource.service.name) with(trace_sample=0.05)The compare function
Note
This function is primarily used to drive the Comparison tab in Traces Drilldown.
The compare function splits a set of spans into two groups: a selection and a baseline.
It returns time-series for all attributes found on the spans to highlight the differences between the two groups.
This powerful function is best understood by using the Comparison tab in Traces Drilldown. You can also under this function by looking at example outputs below.
The function is used like other metrics functions: when it’s placed after any trace query, it converts the query into a
metrics query:
...any spanset pipeline... | compare({subset filters}, <topN>, <start timestamp>, <end timestamp>)
Example:
{ resource.service.name="a" && span.http.path="/myapi" } | compare({span:status=error})This function is generally run as an instant query. An instant query gives a single value at the end of the selected time range. Instant queries are quicker to execute and it often easier to understand their results The returns may exceed gRPC payloads when run as a range query.
Parameters
The compare function has four parameters:
Required. The first parameter is a spanset filter for choosing the subset of spans. This filter is executed against the incoming spans. If it matches, then the span is considered to be part of the selection. Otherwise, it is part of the baseline. Common filters are expected to be things like
{span:status=error}(what is different about errors?) or{span:duration>1s}(what is different about slow spans?)Optional. The second parameter is the top
Nvalues to return per attribute. If an attribute exceeds this limit in either the selection group or baseline group, then only the topNvalues (based on frequency) are returned, and an error indicator for the attribute is included output (see below). Defaults to10.Optional. Start and End timestamps in Unix nanoseconds, which can be used to constrain the selection window by time, in addition to the filter. For example, the overall query could cover the past hour, and the selection window only a 5 minute time period in which there was an anomaly. These timestamps must both be given, or neither.
Output
The outputs are flat time-series for each attribute/value found in the spans.
Each series has a label __meta_type which denotes which group it is in, either selection or baseline.
Example output series:
{ __meta_type="baseline", resource.cluster="prod" } 123
{ __meta_type="baseline", resource.cluster="qa" } 124
{ __meta_type="selection", resource.cluster="prod" } 456 <--- significant difference detected
{ __meta_type="selection", resource.cluster="qa" } 125
{ __meta_type="selection", resource.cluster="dev"} 126 <--- cluster=dev was found in the highlighted spans but not in the baselineWhen an attribute reaches the topN limit, there will also be present an error indicator.
This example means the attribute resource.cluster had too many values.
{ __meta_error="__too_many_values__", resource.cluster=<nil> }
