
How to use OpenTelemetry and Grafana Alloy to convert delta to cumulative at scale
Migrating from other vendors becomes a lot easier with OpenTelemetry and Grafana Alloy, our distribution of the OpenTelemetry Collector.
But when you come from platforms that use different temporalities, such as Datadog or Dynatrace, you face a challenge integrating with a Prometheus-like ecosystem such as Grafana Cloud: Your metrics still mean the same as before, but they just don’t look right.
That’s because delta samples, which are used in other some non-Prometheus-based observability tools, report a relative change to a measurement, such as +3, -7, etc.
Conversely, cumulative sampling, which is used in Prometheus, represents the exact same information, but it does so as an “absolute” value in relation to an arbitrary aggregation period, giving samples like 10, 4.
Consider the following example time series (or stream, in OTel language):
Time | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
Cumulative | 12 | 14 | 14 | 17 | 10 | 4 | 13 | 18 | 22 | 24 |
Delta | +12 | +2 | +0 | +3 | -7 | -6 | +9 | +5 | +4 | +2 |
We covered this topic on the Grafana Labs blog in more detail before, and I also spoke about it during OTel Community Day 2024:

Luckily, Alloy (and the OpenTelemetry Collector) recently got a whole lot better at handling this scenario!
That’s because the team at Grafana Labs contributed the deltatocumulative processor upstream, adding the missing piece to send delta samples to cumulative backends such as Prometheus or Grafana Cloud.
Converting delta metrics
The underlying math to convert a stream of delta samples to their cumulative equivalent is not overly complex.
Consider the following simplified algorithm:

When processing a metrics write request, it iterates the sample list. For each delta increase or decrease it adds that amount to the last value of that stream (or zero if this is the first sample ever seen).
The result is now a proper cumulative sample, because it’s accumulated (added up) over time. Those values are stored in the processor for the next aggregation and also passed onto the next consumer in the metrics pipeline.
(There is a little more timestamp and edge-case handling involved to do this properly all the time, but this captures the basic idea.)
The role of statefulness
Unfortunately, however, the above operation comes with a big caveat: It’s stateful.
See the Processor state the algorithm keeps interacting with? This state is what the collector has to keep in memory. And because this must be done per-series specifically, every sample of a certain time series must always be sent to the exact same collector instance as the last sample was.
Not exactly scaling-friendly, right?
Incorporating load balancing
Luckily, there is another component for this exact kind of requirement: The loadbalancing exporter.
It recently gained support for streamID-based routing, which does exactly what we need: it always sends samples of the same time series to a fixed collector endpoint.
To leverage that, we setup a two-layer collector deployment:

For brevity, the following sections only include the most important parts. You can find the full configuration on GitHub:
sh0rez/deltatocumulative-scaling
Using containers
I’m using Docker Compose to create the containers in our deployment above, but this can be done using any system, including Kubernetes:
services:
# application generating delta metrics, writes to router using OTLP
app:
build: ./deltagen
environment:
OTEL_EXPORTER_OTLP_ENDPOINT: http://router:4318
OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE: delta
scale: 4
# stateless collector, routing incoming metrics to workers based on stream-id
router:
image: otel/opentelemetry-collector-contrib:0.112.0
volumes:
- ./loadbal.yml:/etc/otelcol-contrib/config.yaml
scale: 1
# stateful collector, converting from delta to cumulative and remote_writing to prometheus
worker:
image: otel/opentelemetry-collector-contrib:0.112.0
volumes:
- ./worker.yml:/etc/otelcol-contrib/config.yaml
scale: 2
This gives us several instances of an app that generates metrics, a single load-balancer, and two workers.
Docker Compose also automatically sets up the Docker DNS server, such that nslookup router returns the IPs of both instances.
Configuration: load balancer
Our application sends metrics using OTLP, but any other receiver works:
receivers:
otlp:
protocols:
http:
endpoint: 0.0.0.0:4318
Next, the loadbalancing exporter is configured to do sticky routing on a per-series basis:
exporters:
loadbalancing:
routing_key: streamID # load-balance on a per-stream basis
resolver:
dns:
hostname: worker # send to a stable worker of the pool
protocol:
otlp:
tls:
insecure: true # for testing, properly configure TLS in production
This uses the dns resolver, which discovers worker instances by doing a DNS A lookup on the hostname worker.
Docker Compose configures the built-in Docker DNS server so that it always returns all instance IPs when querying for the service name. The same can be achieved in Kubernetes by using a headless Service.
Configuration: worker
The workers receive samples from a router in OTLP gRPC, convert them to cumulative, and forward them to some backend supported by the collector (e.g., Grafana Cloud).
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
The deltatocumulative processor works out-of-the-box. See its documentation for additional configuration options.
processors:
deltatocumulative: {}
Once converted to cumulative, the samples can be used with any exporter that supports the cumulative temporality, such as the prometheusremotewrite exporter.
exporters:
prometheusremotewrite:
endpoint: http://prometheus:9090/api/v1/write
resource_to_telemetry_conversion:
enabled: true
Running the processor
Once started, we can clearly see the even distribution of data points across the different workers, using the following query:
rate(otelcol_receiver_accepted_metric_points[1m])
In this example, the number of workers was scaled from two to three, then up to five, then back to two.
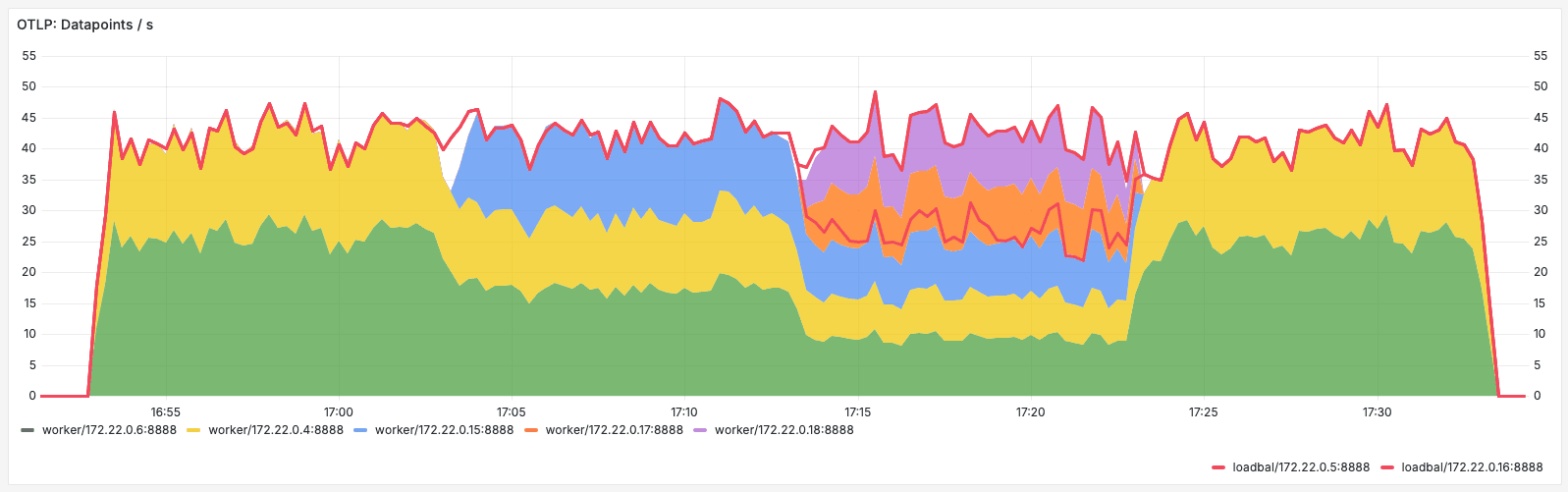
The instances were DNS discovered as they came and went, with loadbalancing always evenly distributing load between them.
The load-balancer (red line) was scaled from one to two and back.
Looking at deltatocumulative, we can see the streams tracked in memory. They are dropped after five minutes without receiving new samples:

Looking ahead
Most of this is early work, just released to the wider community.
Any kind of testing and feedback is highly appreciated. Don’t hesitate to file issues, engage on Slack (the Grafana community Slack and CNCF Slack both have #opentelemetry channels) or even contribute PRs.
Once mature, we will explore ways to reduce the operational complexity, such as bringing this functionality directly into backends such as Prometheus’ OTLP receiver or Grafana Cloud.
Grafana Cloudis the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!

