

How to work with multiple data sources in Grafana dashboards: best practices to get started
Grafana dashboards enable you to visualize and correlate data from a wide range of sources. With a centralized view of your data, you can troubleshoot faster, make better decisions, and streamline monitoring.
But for those of you ramping up with Grafana, you might have a few questions about how, exactly, to create these rich dashboards featuring data from disparate sources, or even how to incorporate multiple queries from a single source into your visualization.
To start, it’s helpful to understand how dashboards are built in Grafana. Grafana dashboards consist of panels that display data in beautiful graphs, charts, and other visualizations. These panels are created using components that transform raw data from a data source into visualizations. The process involves passing data through three gates: a data source plugin (there are over 150 of them in the Grafana ecosystem), a query, and an optional transformation.

You can learn more about how data flows from its source into a Grafana dashboard in our technical documentation.
In this post, we’ll move beyond this basic model and cover how to do the following in your Grafana dashboards:
- Use multiple queries from the same source in a panel
- Join/connect multiple data frames with transformations
- Use mixed-source queries for different formats and databases
You can find all the examples in this post on Grafana Play to reference as you read through.
How to use multiple queries in a single panel
When you edit any visualization in Grafana, in the Queries section, you would normally write a query that resembles what’s shown in the screenshot below. For simplicity, rather than a SQL or PromQL query, here we are using static CSV data; this could be any query that results in a similar data set.
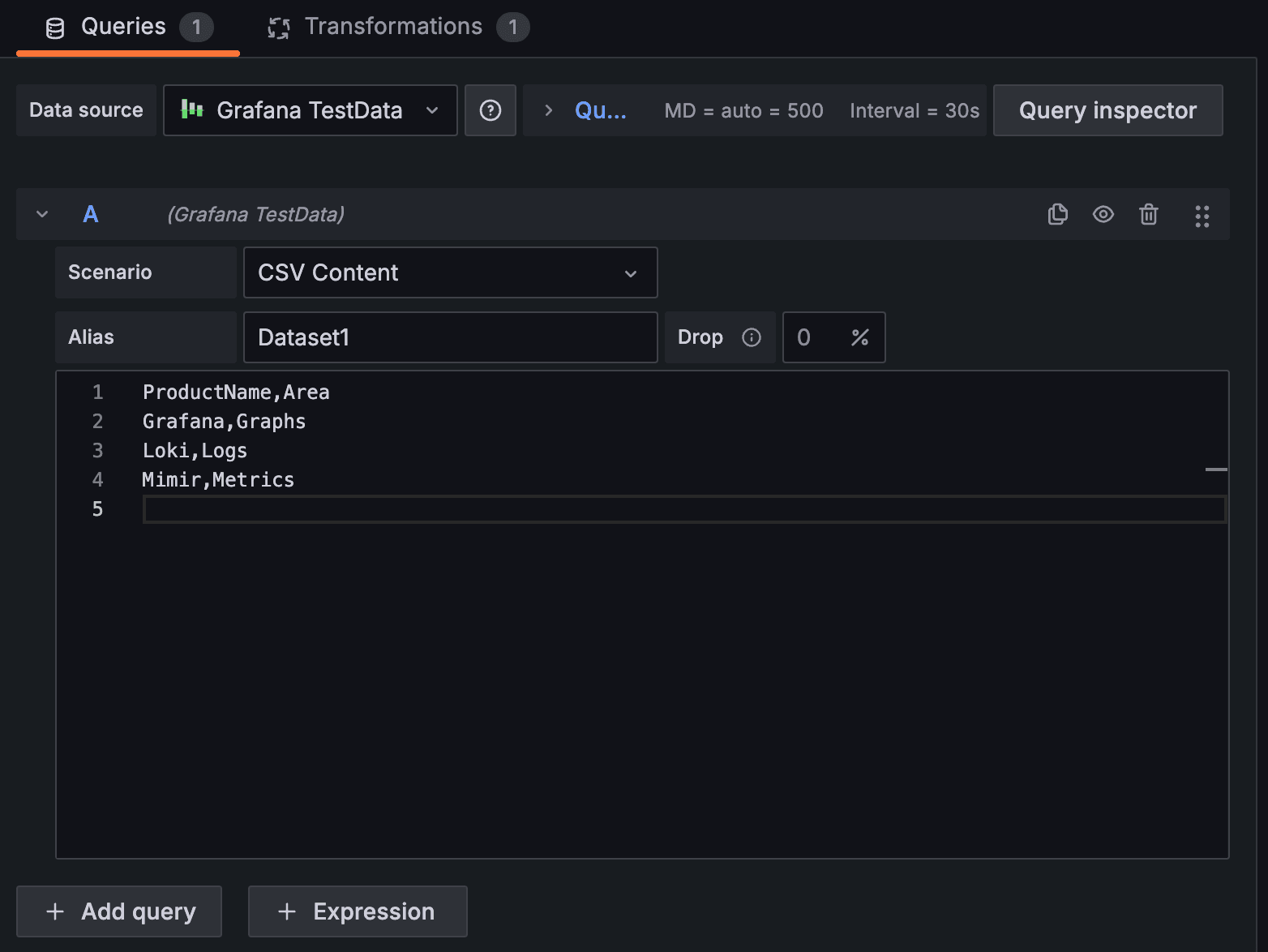
We can click the Add query button to create a second query, piping two (potentially different) data sets into the same visualization. Let’s add a second one. Notice that Grafana automatically names these queries “A” and “B,” but you can edit the label to make it more specific.

These are just the basics. You can add as many queries as you like to any visualization, and you can give them all custom names.
Here, our very basic example results in a selectable visualization; it is really two tables in one with a selector at the bottom. We got two tables because we gave Grafana two different data sets with no connection. What we really want is a single, unified table, so that’s next!

How to join data with transformations
Whenever you query data in Grafana, you transform that data into an intermediate format called data frames. Many Grafana visualizations support multiple data frames only by letting you choose which one to view at a time, as we saw above. To consolidate them, we need to turn those two data frames into a single frame, and we can do this with transformations.
Merge transformation (UNION operation)
In our CSV example above, the two data frames had the same schema and columns. So the simplest way we can combine them is with a merge transformation, as shown below. By going to the Transformations tab, clicking Add Transformation, and selecting Merge, we essentially create a union of all of the data.

Join transformation: SQL-like joins on any Grafana query
In this second example, we will define two different CSV data sets that store different data (this time, Grafana products and their initial release years).
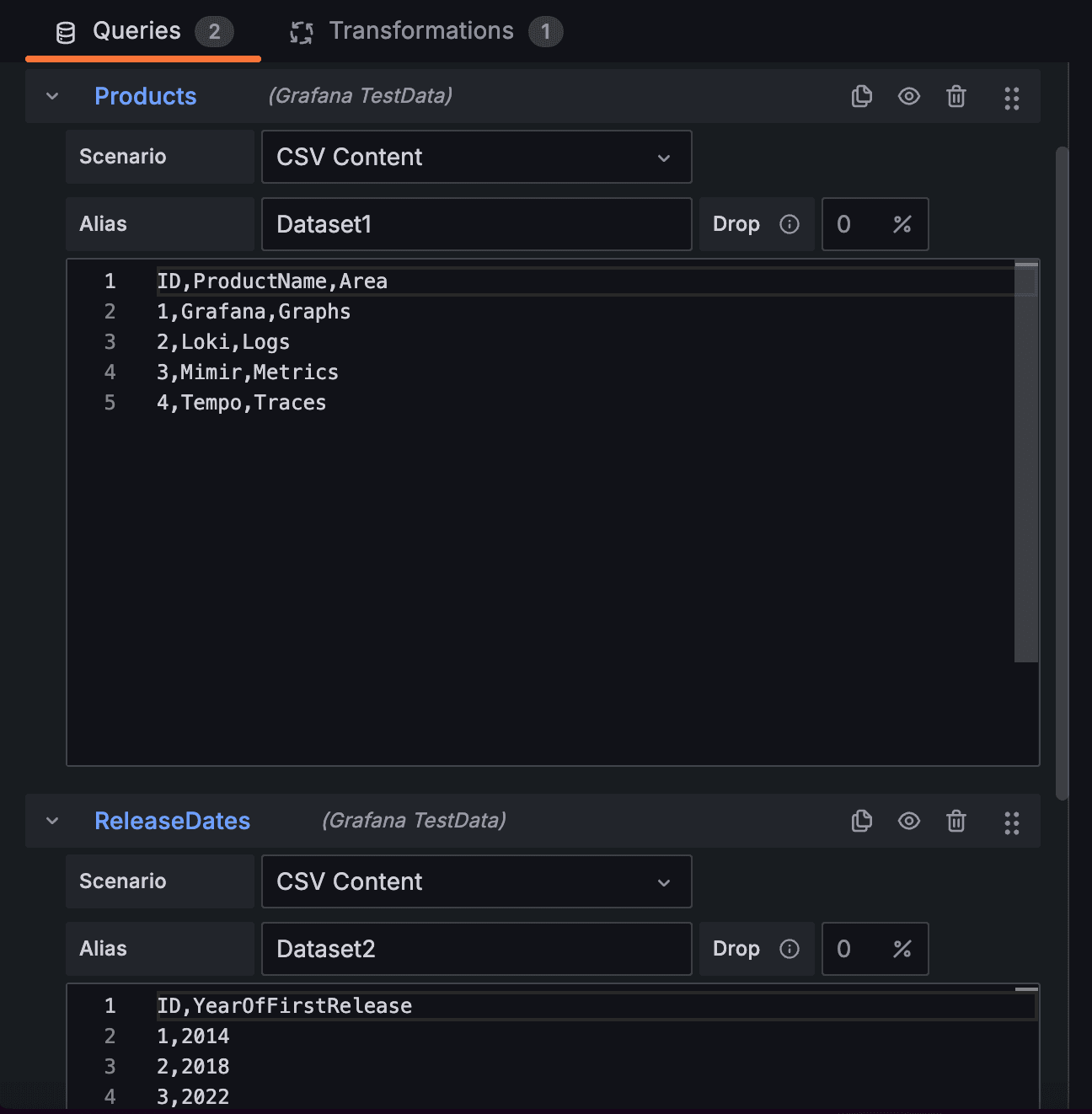
In this case, we can’t simply combine the data sets because their schema and columns don’t match. So instead, we use a “Join by field” transformation, and specify that we want the data joined by the ID field.
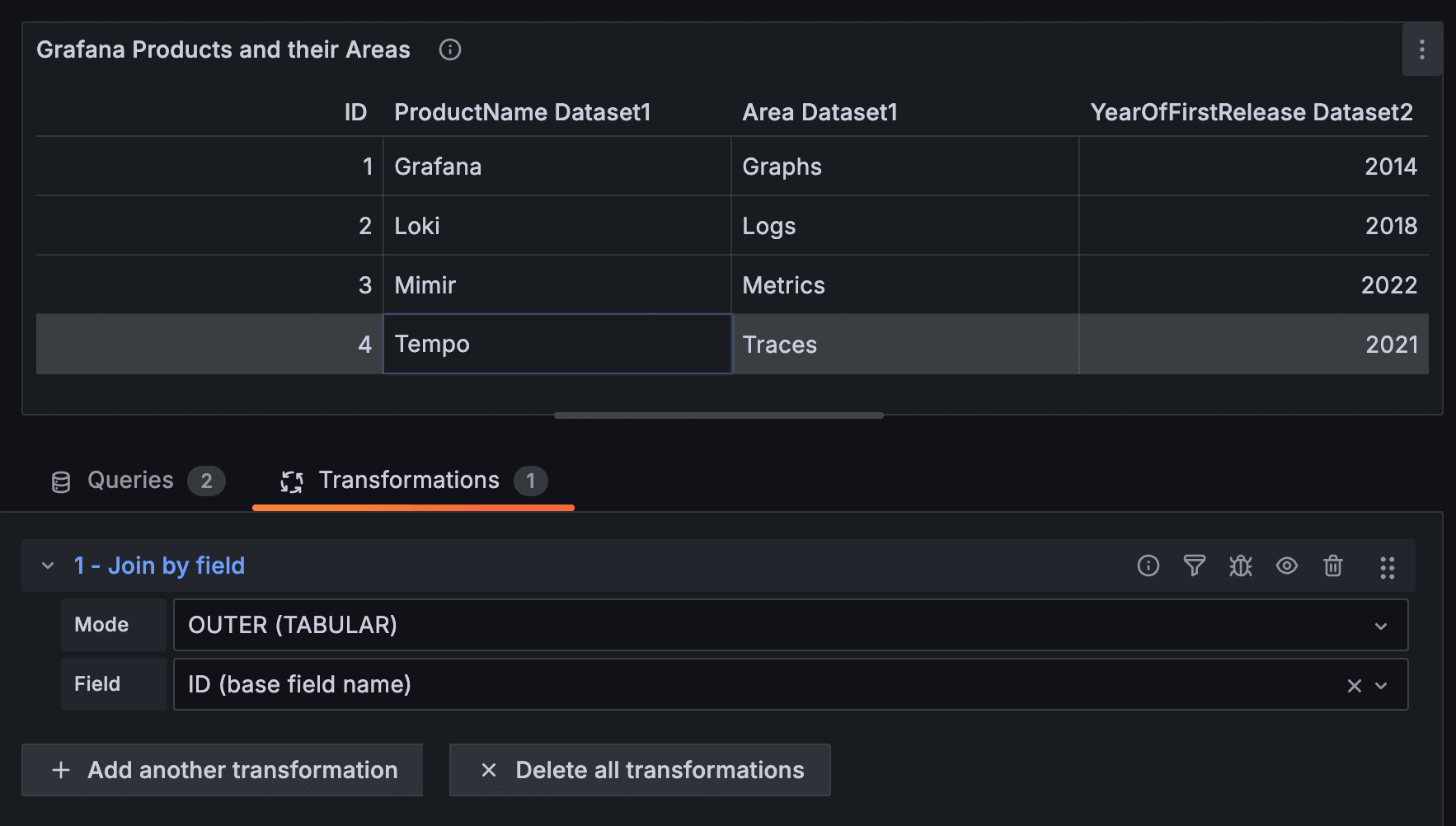
We combine two data frames into another, just as a SQL join operation might connect two tables. You may notice that the new, combined data frame has “qualified names” and that the columns are now called “ProductName Dataset1” to indicate which source each column came from. If you do not want this kind of field renaming to help keep things separate, you can add another transformation, “Organize fields by name,” and rename those fields.

How to use mixed-source queries
Let’s take this a step further and connect JSON data to tabular data to show that we do not have to be using sample test data, schemas do not have to match, and the form of the data (JSON vs. tables) does not have to match.
In the previous examples, we were using the test data source. For this one, we’ll need to choose the Mixed data source, because we’ll be defining multiple queries pointing to different sources.

The first query gets a list of target countries. In a further, built-out example, we could limit this to the countries that Grafana Labs does business in, but let’s start with all the countries first.
Notice that we aliased a column here; I selected the “Code2” field as a different name, “iso.” This will become important in a minute. The Code2 field contains a two-character country code: US for the United States, CN for China, and so on.

The second query gets data about airports, heliports, and other locations from GitHub. We use the Infinity data source plugin, a versatile plugin that allows you to query and visualize data from JSON, CSV, XML, and GraphQL endpoints (aka, a Swiss army knife for dealing with data available on the web.)

After creating these two queries, we’re going to apply another join, by the field iso. We will then further cut down the data to only large locations that are airports, excluding, for example, small heliports, to make the amount of data more manageable.

“Join by field” requires both data frames to share a field by a given name (in this case, iso). So, if I had not aliased that field earlier, there would be no common field to do the join on, and it would not be possible to perform the join.
If you don’t have the option I used to SQL alias a field, you can use the “Organize fields by name” transformation to rename a field. If, for example, you wanted to join two JSON data frames with no shared fields, you could rename a field on one side as your first transformation, and then have a shared field on which to join.
All of that data from GitHub has latitude and longitude information in it, so we can simply change the visualization type to Geomap, and now we get a fused view of all of the world’s largest airports on a map, which you interact with.

Note: While Grafana can perform many operations similar to a database, if you’re dealing with large data volumes, it’s better to filter data as extensively as possible at the database layer before getting it into Grafana. If you query three systems for 100,000 records each, only to join and filter in Grafana to the 10 records you really want, performance might get slugging because of the amount of work required.
Your best bet is to “push work down” to each data query as much as you can. I had to filter that airport JSON from GitHub using Grafana because I couldn’t query it live, but if I had the option to query it through a service endpoint, that would be preferable.
Summary and how to learn more
Using these techniques, you can create rich dashboards that borrow and connect data from many different sources. You can use these same techniques beyond just two queries, applying them to three or more.
To recap, these techniques work because of three important things:
- Any data query to a source turns into a “data frame” inside of Grafana, and gives you a common basis for dealing with a query result set, no matter where it came from or how it was originally formatted
- Grafana’s big tent and open source approach means you can use just about anything you can imagine as a datasource; there are over 150 data source plugins.
- A flexible set of transformations lets you perform database-like filtering and joining inside of your data definitions.
For dashboard creators, all of this means you don’t need centralized data to create cool, centralized visualizations. If you want to learn more about how Grafana works, we recommend the data sources topic in our documentation. Our transformations docs also offer more information about what you can do with multiple data sources. Lastly, you can check out our extensive collection of community-submitted dashboards for Grafana.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!

