How to effectively use the Elasticsearch data source in Grafana and solutions to common pitfalls
Covered in this article:
- Lucene Query Format
- Templated Queries
- Sawtooth-Like Graphs
- Incomplete data at the beginning and the end of a graph
- Sum function broken
About one year after I created an issue at Grafana’s GitHub page, we finally have support for using Elasticsearch as a time series database! At that time, I was trying to lower the burden of adopting the open source Java performance monitoring tool stagemonitor which I’m the project lead of. As stagemonitor already requires Elasticsearch for its request analysis feature, someone suggested that I should try to also store the metrics data into Elasticsearch so that stagemonitor users only have to install one database. At first, I was like ‘are you nuts? Elasticsearch is no TSDB, it’s used for logs and stuff but not for metrics!’. But the idea was interesting and I could not stop thinking about it. Also, around that time I first read about the metrics 2.0 approach which basically means that you don’t have ‘classic’ metric names that are dot-separated but rather a document of key-value pairs. This has several advantages e.g. it makes the metrics more self-descriptive and lets you add tags (aka dimensions like datacenter) afterwards without changing the metric identity (which would otherwise break your existing dashboards). To me it seemed like Elasticsearch actually would be a great fit for this data model and its aggregation framework could replace the most important functions of graphite.
I have already blogged about how to set up the data model so that it fits most naturally into Elasticsearch and how to tune the mapping to minimize disk overhead. In this post, I want to focus on how to effectively use the Grafana query editor and how to avoid common pitfalls.
When using the Elasticsearch data source, you have to keep in mind that this feature is relatively new. So there are some rough edges and not all functions (aggregations) Elasticsearch provides are currently available in the editor. When coming from Graphite, you first have to get familiar with the way aggregations work. But still, you might miss some functions especially if it comes to interacting with multiple series like dividing or subtracting two series. So before migrating all your metrics to Elasticsearch, you should do a proof of concept whether you will still be able to construct your most important graphs. In general, the Elasticsearch data source is more similar to InfluxDB or OpenTSDB which are based on tags and values than to Graphite which is based on dot-separated metric names.
One big problem of the TSDB market is that there are no standards (like SQL) and that there is no clear leader. There are so many TSDBs out there that all have some pros and cons. That’s why Grafana supports a lot of data sources which is great, but switching from one to another TSDB requires a lot of effort because the fundamental concepts are different and the graphs and dashboards have to be rebuilt without an easy migration path. However, there are plans to support functions within Grafana that can be applied to all data sources. That means that only a basic set of functions have to be provided by the data sources. In particular, those which require access to all data points like the percentiles function. Other functions like the difference between two series can just as well be performed within Grafana.
### Lucene query format The biggest difference to the query editor for InfluxDB is that there is no input for FROM and WHERE but only a Lucene query input field. The Lucene query syntax is a quite powerful language for constructing a search query. But don’t despair, you don’t have to know all the nuances of that syntax. Most use cases can be handled with a basic set of instructions. Also, in the future, there might be a more convenient way to enter Elasticsearch queries which will probably work more like the InfluxDB WHERE input so you don’t have to mess with the actual Lucene query for simple cases. Grafana Query editor for InfluxDB
Grafana Query editor for InfluxDB
 Grafana Query editor for Elasticsearch
Grafana Query editor for Elasticsearch
The fundamental difference of these databases is that in InfluxDB you have a dedicated name for the series that is like a table name in relational databases. In Elasticsearch there is no dedicated series name but you have tags and values you can use to filter, for example, to show only metrics of a certain host. So when you are using Elasticsearch, it is advisable that you always have a tag called name, that acts like the series name in InfluxDB. Of course you can also use a different tag like series, @metric or something else. Just make sure that this name is consistent throughout all your metrics.
Let’s say we want to migrate the InfluxDB query FROM logins.cout WHERE hostname= $Hostname to Elasticsearch. At first we have to translate the FROM clause into a Lucene query like this:
name:logins.count
The second step is to apply the templated hostname filter
name:logins.count AND hostname:$Hostname
The important thing is that you explicitly have to combine the two filters with the boolean operator AND. If you forget the AND, the default operator OR will be applied which would result in a mess because it would mean: either collect the logins.count metric or return any metric where hostname is $Hostname. Remember: the series name is just another tag. There is another important point: if a value you want to filter by contains a whitespace you have to quote it.
name:logins.count AND hostname:“my awesome host”
Best practice is that you don’t have white spaces in tag values. I’ll tell you why in a moment.
###Templated queries Templated queries are a great way to make dashboards more dynamic by allowing users to slice and dice the data. For example, you could make a dashboard where you get an overview of all data across all hosts and use a templated query to be able to see the data of one or more individual hosts. To do this with the Elasticsearch data source, we currently have to enter raw JSON data when creating a template. The following collects all hosts that are in the eastern datacenter:{“find”: “terms”, “field”: “host”, “query”: “datacenter: east”}
When a certain host in the dropdown gets selected, the value of the template variable $Host changes. But that does not mean that all graphs are automatically filtered by the currently selected host like you may be used to if you have used Kibana before. To apply the host filter to a graph you have to explicitly add it to the Lucene query like this:

But beware of white spaces in template values. Because the templating system works with simple string replacement, the values get inserted into the raw Lucene query and the query fails. Looking closer at the Lucene query reference you could put the template variable in quotes like host:"$Host" but that in turn fails if you select multiple hosts. In that case $Host gets expanded to (“host1” OR “host2”). So quoting $Host results in “(“host1” OR “host”)” which leads to an invalid query again.
For the same reason inserting a template variable into a template query fails:
{“find”: “terms”, “field”: “host”, “query”: “datacenter:$Datacenter”}
If only one data center is selectable everything is fine, but as soon as you select more than one, the query becomes invalid.
Long story short: avoid white spaces in tag values.
### Sawtooth-like graphs This problem can appear when you have multiple reporters that are sending metrics to Elasticsearch, for example, if you have two instances of a web application that are monitored by stagemonitor. Typically you configure them so that they report in a uniform interval (like each 60 seconds). But the moment they are reporting depends on when the servers are started.If you want to graph the average response time across your web servers, that difference in the reporting moment can cause these ugly sawtooth-like graphs (don’t look too long at it - it gets kinda hypnotic ;)
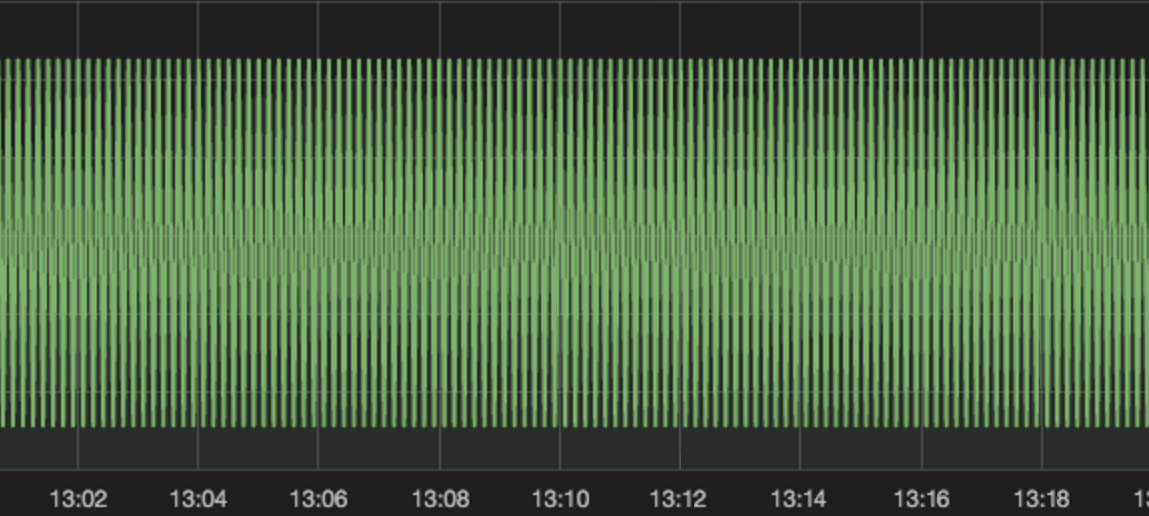
The problem is more than one data point (the group by time interval) per 60 seconds (the reporting interval) gets requested. So the average function does not really take the average value of the values of ‘Host A’ and ‘Host B’ but rather hops between their values, because they don’t fall into the same bucket.
![]()

The solution to this is to make sure that the values always fall into the same bucket regardless of the exact moment the different hosts reported their values.
![]()

In Grafana this is quite easy as you can set a lower bound for the group by time interval in the Metrics tab of the panel editor like this:

If you are using stagemonitor you don’t have to do this manually as it already knows the reporting interval and sets the group by time interval accordingly on all graphs when importing the dashboards.
Incomplete data at the beginning and the end of a graph
This problem also results from the different reporting moments that occur when multiple agents push metrics into Elasticsearch. The group by time ‘trick’ works for most cases but at the very beginning of a graph where there might be one data point of ‘Host A’ that falls into a bucket where there is none for ‘Host B’ because B’s data point (that should be in the same bucket) is not within the requested timeframe. The same problem can also occur at the very end of a graph.

Most of the times this might not be a real issue, but in some cases it totally screws up your graph. A good example of that is when you want to monitor Disk I/O. From /proc/diskstats you get the total bytes written since the last reboot. That number can diverge quite massively between different servers. To get a meaningful graph, you probably want to apply a derivative function so that you get the bytes written per second. That together makes a missing data point at the end/beginning fatal as it causes a massive spike so that the data in the middle is not visible. This is why:
First, the average of the values of all hosts are calculated. If there is a massive difference in the values of the hosts, the average is a lot different when there is a missing datapoint. Things get worse if you also apply a derivative function. For example let’s assume the value of Host 1 is 1 and the value of Host 2 is 1,000,000 and their values increase by 1 each time they report. In a happy world, the fist average is 500,000.5 the second one 500,001.5 and so on and the derivative is always 1. But let’s say the first value of Host 1 is missing. The first average now is 1,000,000 and the second one 500,001,5. That makes the graph look a bit quirky but that’s something we can live with. But when applying the derivative function everything starts to fall apart. The fist derivative is 499,998.5 (1,000,000-500,001,5) and the consequent ones are always 1 again. That leads to a massive spike at the beginning of the graph so that the real information (that the derivative is always 1) is not visible. This is what it looks like:
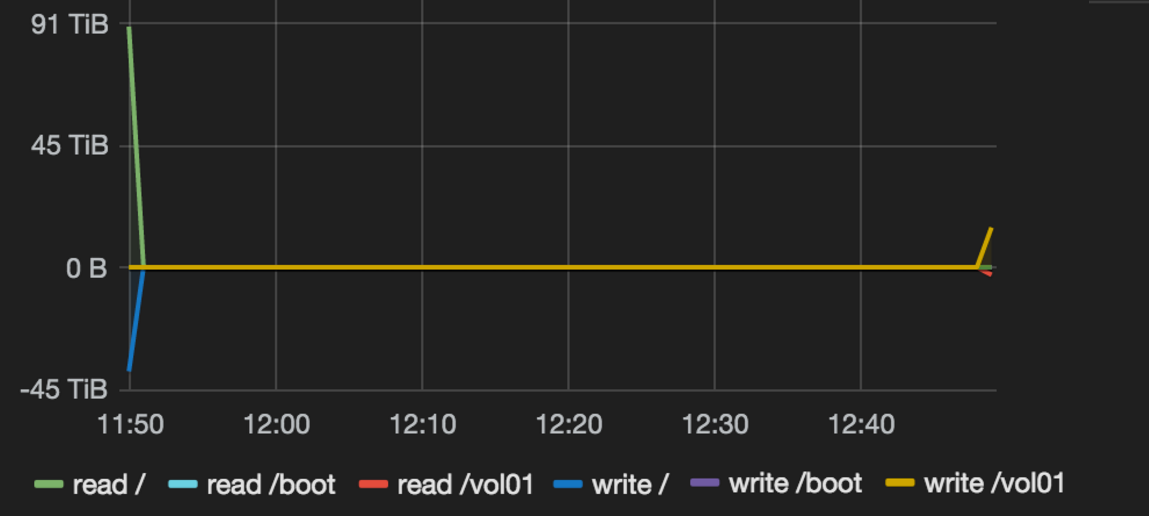
One thing you can do to avoid this issue is to perform a group by on the tag that identifies a reporter. In this case I would do a group by on the host tag because there is one reporter on each host that sends metrics. So each host has an individual graph, thus I avoid the problem.
One thing that Grafana could do to avoid this issue is to ask for a larger timeframe than requested and then truncate the graph client side. But this only fixes the start of the graph, as you obviously can’t look into the future to include the not-yet-reported value of ‘Host A’.
Sum function broken
A common question when monitoring a clustered web application is to find out how many users are currently online. One simple way would be to just sum all sessions across all hosts. Sounds easy. Sounds like I just have to apply the sum function of Elasticsearch and I’m good. Well, unfortunately, that’s wrong.
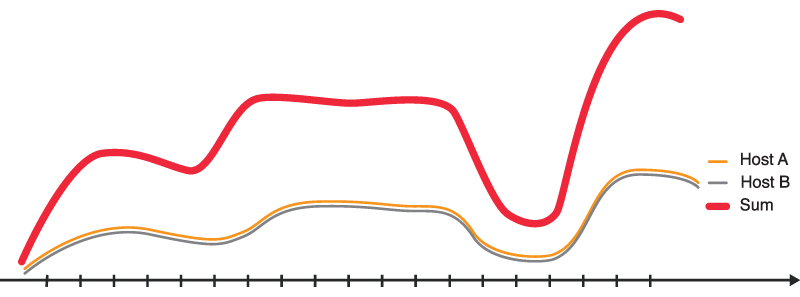
This time, the problem doesn’t have to do with multiple reporters or different reporting moments. It even occurs when you want to sum the sessions of only one application. To understand the issue we first have to understand how the sum function in Elasticsearch works. To display a graph, we always have to apply the date histogram aggregation, which creates buckets for a certain timeframe (the group by time interval). Grafana auto-selects the bucket size that is appropriate for the current timeframe. The larger the time span of the graph gets (for example last 24h) the bigger the buckets get and the more individual data points fall within a single bucket. For example, when we report each 30 seconds and the bucket size is 60 seconds there are two data points per bucket. The sum function works by summing all values that are in a single bucket. That means that the calculated sum is higher than we expect.

That renders the sum and also the count function quite useless for most cases and you should rather work with the average and max functions. There, unfortunately, is not an easy fix for that. I came up with two attempts to solve that problem.
The first attempt is based on the fact that the sum is accurate when the reporting interval is equal to the size of the buckets. So if we divide the sum by bucket size/reporting interval in a script, it would show the correct sum regardless of the bucket size. But that attempt comes with big flaws which doesn’t make that a viable solution. We would somehow have to know what the current group by time interval is. Grafana could, for example, expose a template variable for that. But this seems like an ugly hack to me. The other reason is that when you want to change the reporting interval you would also have to change every single graph that is built that way - a maintenance nightmare.
A more pragmatic solution is to group the sessions by Hosts and then stack the values.

The problem with that approach is that it can quickly get quite messy. Especially if you have a lot of hosts and you are also grouping by other dimensions, the number of individual graphs quickly add up. For example, let’s say you want to stack the read and write I/O of all your hosts for each mount point. Depending on how many hosts you are monitoring and how many different mount points they have, you might end up with thousands of graphs.
Conclusion
I hope you found this Elasticsearch article useful and will give the data source a shot. If you come up with a better approach on how to solve a particular problem, or you came across another challenge, please let me know in the comments. I should also mention that most of the problems are not specific to Elasticsearch and will also occur if you are using InfluxDB or other data sources that work in a similar way.