
How to visualize Prometheus histograms in Grafana
Do you have a Prometheus histogram and have you asked yourself how to visualize that histogram in Grafana? You’re not alone. Here, we will show you how it’s done.
This post assumes you already have a basic understanding of Prometheus and Grafana and it will look at Prometheus histograms from the perspective of Grafana 7.0.
If you’re interested in Prometheus histograms on a technical level you should read Björn “Beorn” Rabenstein’s post about how histograms changed the game for monitoring time series with Prometheus and watch the accompanying talks.
Introducing our data
Our data is a histogram from a fictional image hosting service. Based on this histogram, I’ll ask a set of questions and provide instructions for how to create a panel answering the question.
A Prometheus histogram consists of three elements: a _count counting the number of samples; a _sum summing up the value of all samples; and finally a set of multiple buckets _bucket with a label le which contains a count of all samples whose value are less than or equal to the numeric value contained in the le label.
I’ve put some emphasis on the word “all” above because Prometheus puts a sample in all the buckets it fits in, not just the first bucket it fits in. In other words, the buckets are cumulative. (I’ll come back to this idea later.)
Our image hosting site receives pictures ranging in size from a few bytes to a few megabytes, and we’ve set up our buckets in an exponential scale between 64 bytes and 16MB (each bucket representing four times the size of the previous).
uploaded_image_bytes_bucket{le="64"}
uploaded_image_bytes_bucket{le="256"}
uploaded_image_bytes_bucket{le="1024"}
uploaded_image_bytes_bucket{le="4096"}
uploaded_image_bytes_bucket{le="16384"}
uploaded_image_bytes_bucket{le="65536"}
uploaded_image_bytes_bucket{le="262144"}
uploaded_image_bytes_bucket{le="1048576"}
uploaded_image_bytes_bucket{le="4194304"}
uploaded_image_bytes_bucket{le="16777216"}
uploaded_image_bytes_bucket{le="+Inf"}
uploaded_image_bytes_total
uploaded_image_bytes_count
For the examples, I’ve generated a log-normal distribution between the buckets where the 64KB and 256KB buckets contain almost the same amount of values (the median hovers around 64KB). The buckets surrounding those will gradually decrease in size.

A few notes on my data before we go ahead:
- I’m making the assumption that the Prometheus data here doesn’t contain any relevant resets and doesn’t require me to join metrics.
- I’ve chosen an example with only positive numeric values. This means we can use the
_sumas if it was a counter. - The Go Prometheus client uses scientific notation for large numbers. I’ve chosen not to do that in my code samples, which is the reason for screenshots occasionally being slightly off. The principle is the same.
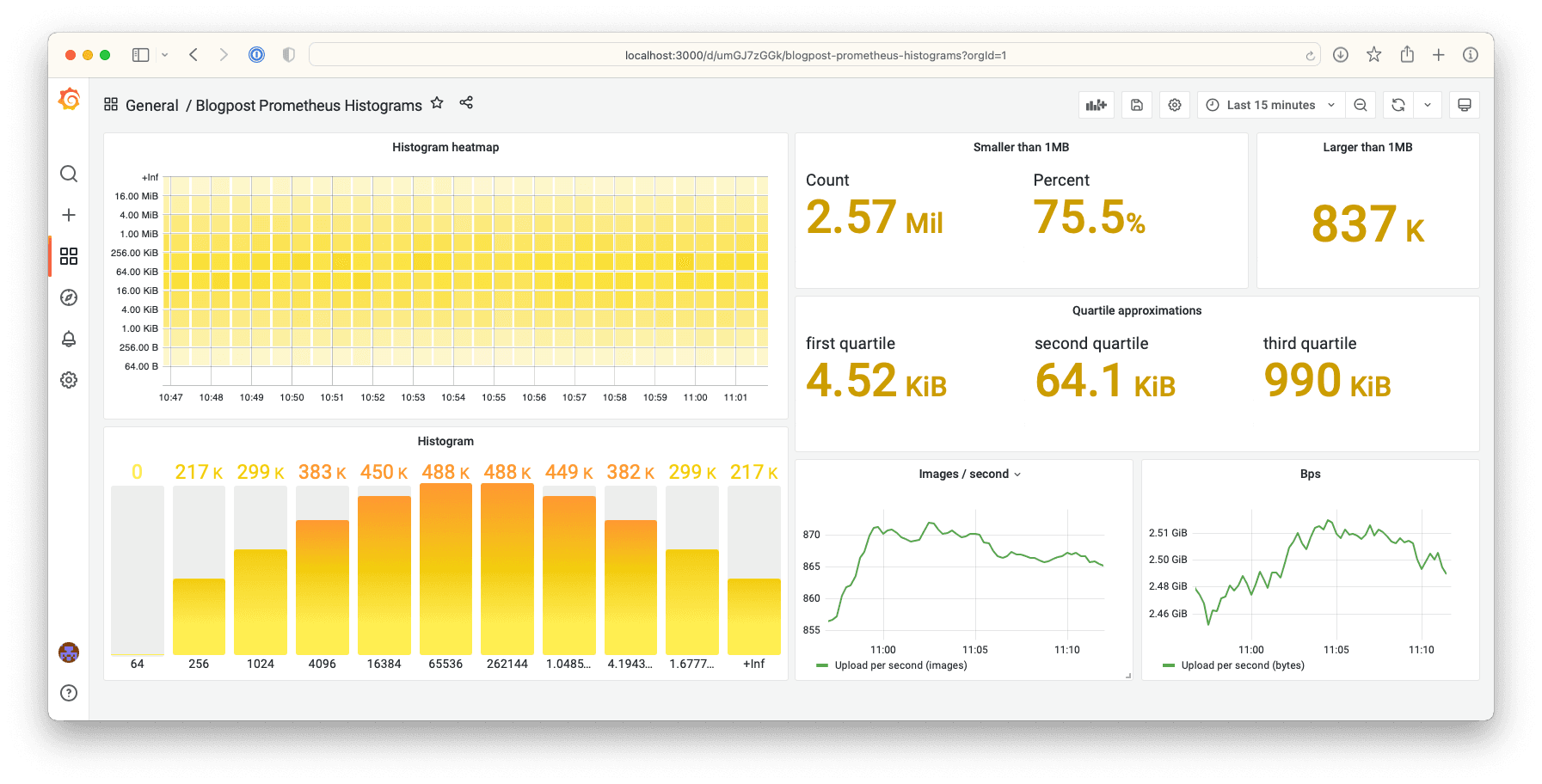
How many files less than (or equal to) 1MB have been uploaded?
This is really the base question for a Prometheus histogram. The answer is stored in the time series database already and we don’t need to use either functions or arithmetics to answer the question.
uploaded_image_bytes_bucket{le="1048576"}
If Prometheus didn’t store the buckets cumulatively, we would have to add up all buckets smaller than 1MB. Adding up the sum of buckets manually would be error-prone and complicated, and while we can assume that we’d have a helper function in case we’d have to do that, the operation would also mean that even simple queries like this one would have to look at a substantial number of unique time series rather than ideally just one.
To visualize this query you can use either the stat, gauge, or graph panels in its default configuration. I’ve chosen stat since I’m mostly interested in how many files we have right now as opposed to over time (as you would see with a graph). And a gauge doesn’t make sense when the data isn’t within a predefined range.
Based on this query, there are a few more queries that we can answer by tweaking the PromQL for the same visualization.
What proportion of the files are smaller than 1MB?
The difference between this question and the previous question is that we want it in relation to the total count. There are two ways of getting the total count for a histogram.
It’s available as uploaded_image_bytes_count and as uploaded_image_bytes_bucket{le="+Inf"} (i.e. How many events are smaller than positive infinity, which is by definition all events).
If we divide the number of files smaller than 1MB by the total number of files, we’ll get a ratio between the two which is what we want.
uploaded_image_bytes_bucket{le="1048576"} / ignoring (le) uploaded_image_bytes_count
Since the normal way of displaying ratios is as percentages, we’ll set the unit to Percent (0.0-1.0).
How many files are larger than 1MB?
We already know the number of files smaller than or equal to one megabyte and the total number of files. Subtracting the number of smaller files from the number of total files will give us the larger files.
uploaded_image_bytes_count - ignoring(le) uploaded_image_bytes_bucket{le="1048576"}
How many files are in the bucket between 256KB and 1MB?
This is the same logic as for the previous query: we can get the number of files between any two bucket boundaries by subtracting the smaller boundary from the larger.
uploaded_image_bytes_bucket{le="1048576"} - ignoring(le) uploaded_image_bytes_bucket{le="262144"}
What size is a quarter of the files smaller than?
As far as the basic questions go, this one is more complicated than the others. We don’t have an accurate answer to this question. We can approximate an answer to this question using PromQL’s histogram_quantile function. The function takes a ratio and the histogram’s buckets as input and returns an approximation of the value at the point of the ratio’s quantile. (i.e. If 1 is the largest file and 0 is the smallest file, how big would file 0.75 be?)
The approximation is based on our knowledge of exactly how many values are above a particular bucket and how many values are below it. This means we get an approximation which is somewhere in the correct bucket.
If the approximated value is larger than the largest bucket (excluding the +Inf bucket), Prometheus will give up and give you the value of the largest bucket’s le back.
With that caveat out of the way, we can make our approximation of the third quartile with the following query:
histogram_quantile(0.75, uploaded_image_bytes_bucket)
Note: When talking about service level, the precision of quantile estimations is relevant. Historically, a lot of services are defined as something like “the p95 latency may not exceed 0.25 seconds.” Assuming we have a bucket for le=0.25, we can accurately answer whether or not the p95 latency does exceed 0.25 or not.
However, since the p95 value is approximated, we cannot tell definitively if p95 is, say, 0.22 or 0.24 without a bucket in between the two.
A way of phrasing this same requirement so that we do get an accurate number of how close we are to violating our service level is “the proportion of requests in which latency exceeds 0.25 seconds must be less than 5 percent.” Instead of approximating the p95 and seeing if it’s below or above 0.25 seconds, we precisely define the percentage of requests exceeding 0.25 seconds using the methods from above.
Show me the buckets’ distribution
Until now we haven’t used any of Grafana’s intrinsic knowledge about Prometheus histograms. If we want to visualize the full histogram in Grafana rather than just getting some data points out of it, Grafana has a few tricks up its sleeve.
If you create a bar gauge panel and just visualize uploaded_image_bytes_bucket in it and set the label to {{le}} you’ll notice a few things:
- The values might be wrong. This is because the default calculation the bar gauge performs on the data it receives is Mean. Under the Panel > Display > Value option, changing this to Last instead will provide you with the correct value.
- You might notice how the buckets are out of order as they are being ordered alphabetically rather than numerically (i.e. 10 is smaller than 2, since 1 is smaller than 2).
- You’ll also be reminded of the cumulative nature of the histogram, as every bucket contains more elements than the previous.
To tell Grafana that it’s working with a histogram and that you’d like it to sort the buckets and only show distinctive counts for each bucket, there’s an option to change the format of the Prometheus data from Time series to Heatmap.
After changing the format, you’ll notice how your histogram bar gauge panel looks much more like a school book example of how a histogram should look.
Now show me the buckets’ distribution over time
Since a bar gauge doesn’t contain any temporal data, we’ll have to use something else when we’re interested in seeing the same visualization over time. Grafana has a Heatmap panel for this purpose. When we have our histogram bar gauge set up, if we switch the panel type to Heatmap there are a few adjustments we’re going to have to make before our heat map is displayed properly:
- We have to change the Panel > Axes > Data Format > Format option from Time series to Time series buckets as we have our buckets pre-defined.
- We’re also going to change our query a little to show the increase per histogram block rather than the total count of the bucket. Our new query is
sum(increase(image_uploaded_bytes_bucket[$__interval])) by (le). When we have a temporal dimension in our visualization it makes sense to make sure the query takes advantage of that. - Finally, we’re going to set Query options > Max data points to 25. Heat maps are packed with information already, and they have a tendency of slowing down the browser when the resolution is too high.
Note: I accidentally used rate instead of increase when recording the animation for the heat map. The rate is the average increase per second for the interval. The relative difference between the buckets is the same, so the resulting heatmap will have the same appearance.
Conclusion
While there are still a million things that can be said about histograms and their visualizations, hopefully this has provided you with the push you needed to embrace and further explore your histograms.
I’d love to see some real-world examples using histograms — if you’re able to, please tweet screenshots of your Grafana instances to @grafana or post them to our community forum at community.grafana.com.
You can get started with Grafana and Prometheus in minutes with Grafana Cloud. We have free and paid Grafana Cloud plans to suit every use case — sign up for free now.

