Plugins 〉Parquet-S3-Datasource

Parquet-S3-Datasource
Parquet-S3-Datasource for Grafana
Query and visualize Apache Parquet files stored in Amazon S3 (or any S3-compatible storage such as MinIO, Wasabi, Cloudflare R2, or DigitalOcean Spaces) directly in Grafana — without an intermediate database.
The datasource reads Parquet footers and column chunks straight from object storage, converts them through Apache Arrow into Grafana data frames, and runs a built-in lightweight SQL engine over the result so you can build dashboards and alerts from your data lake.
Overview
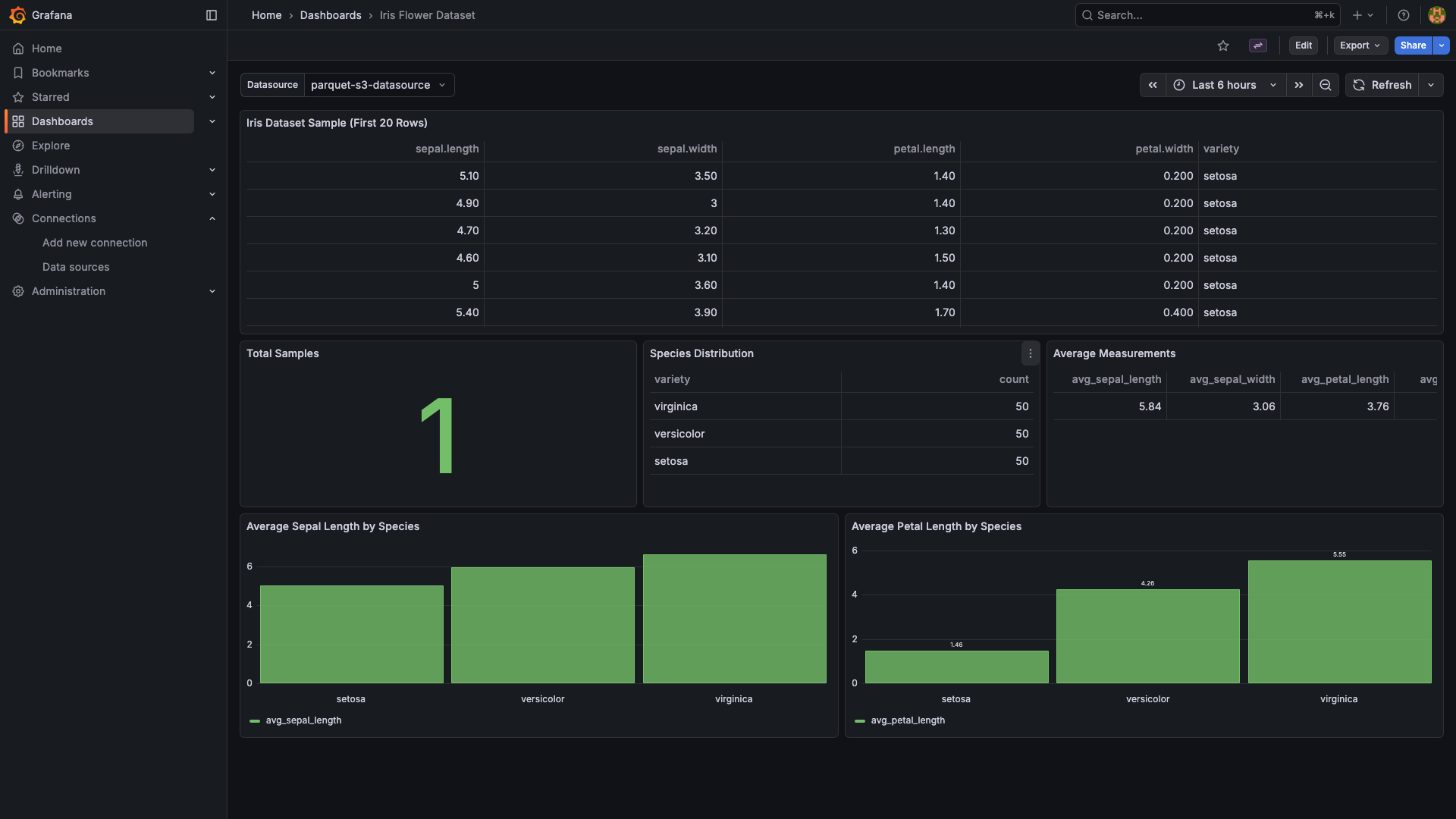
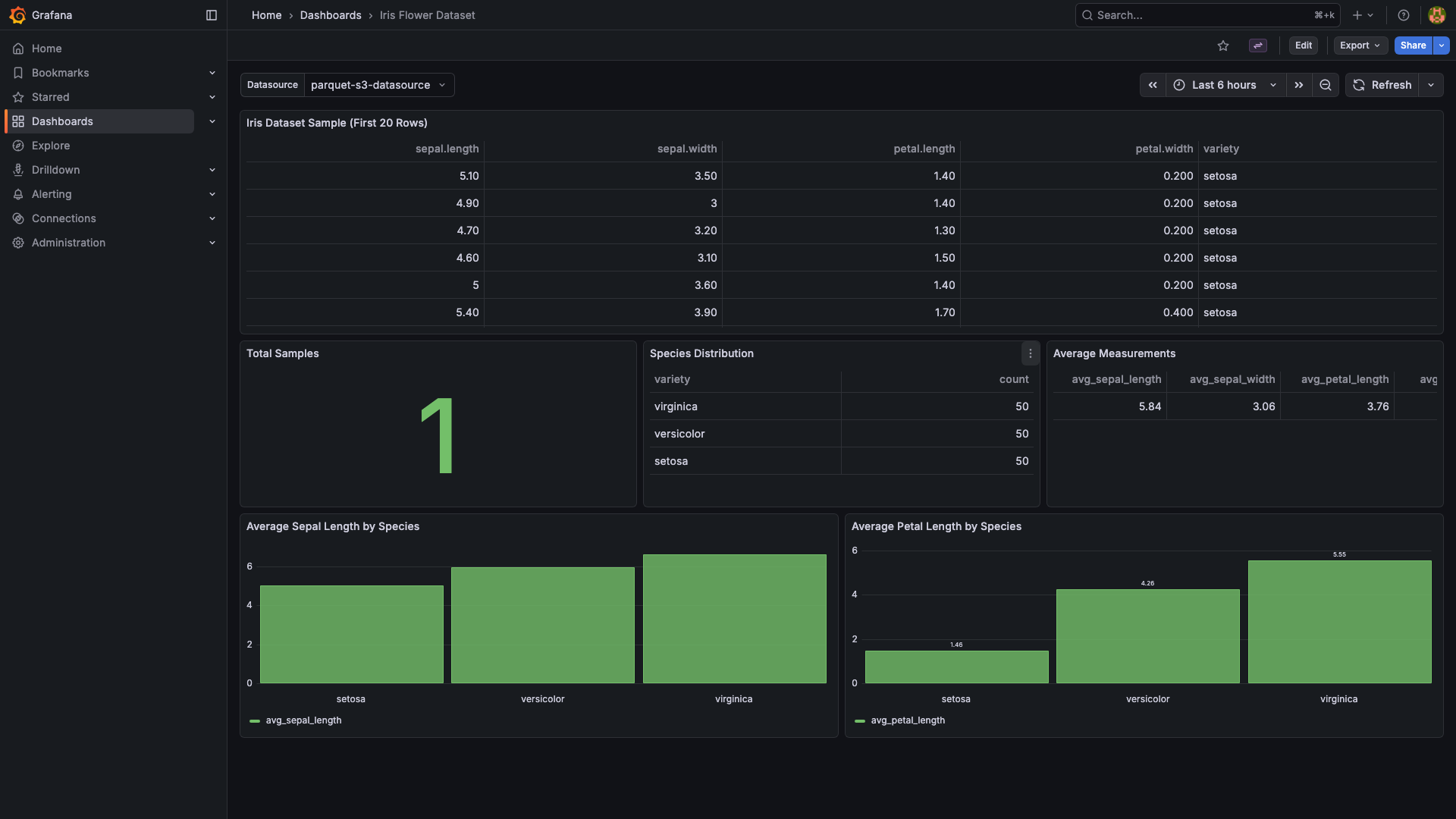
Typical use cases:
- Ad-hoc exploration of Parquet exports (analytics dumps, ML datasets, ETL outputs) sitting in S3.
- Long-term observability archives — keep recent metrics in Prometheus and roll older data into Parquet on S3.
- Multi-tenant data lakes where each customer's data lives in its own bucket or prefix.
- Alerting on data that already lives in S3, without standing up a query engine.
Features
- Direct Parquet access over S3 — no Athena, Trino, or DuckDB required.
- S3-compatible storage support: Amazon S3, MinIO, Wasabi, Cloudflare R2, DigitalOcean Spaces, Backblaze B2, etc. Custom endpoints and path-style URLs are supported.
- Apache Arrow pipeline for efficient columnar reads and type-correct Grafana frames (timestamps, numerics, booleans, strings).
- Built-in SQL subset with
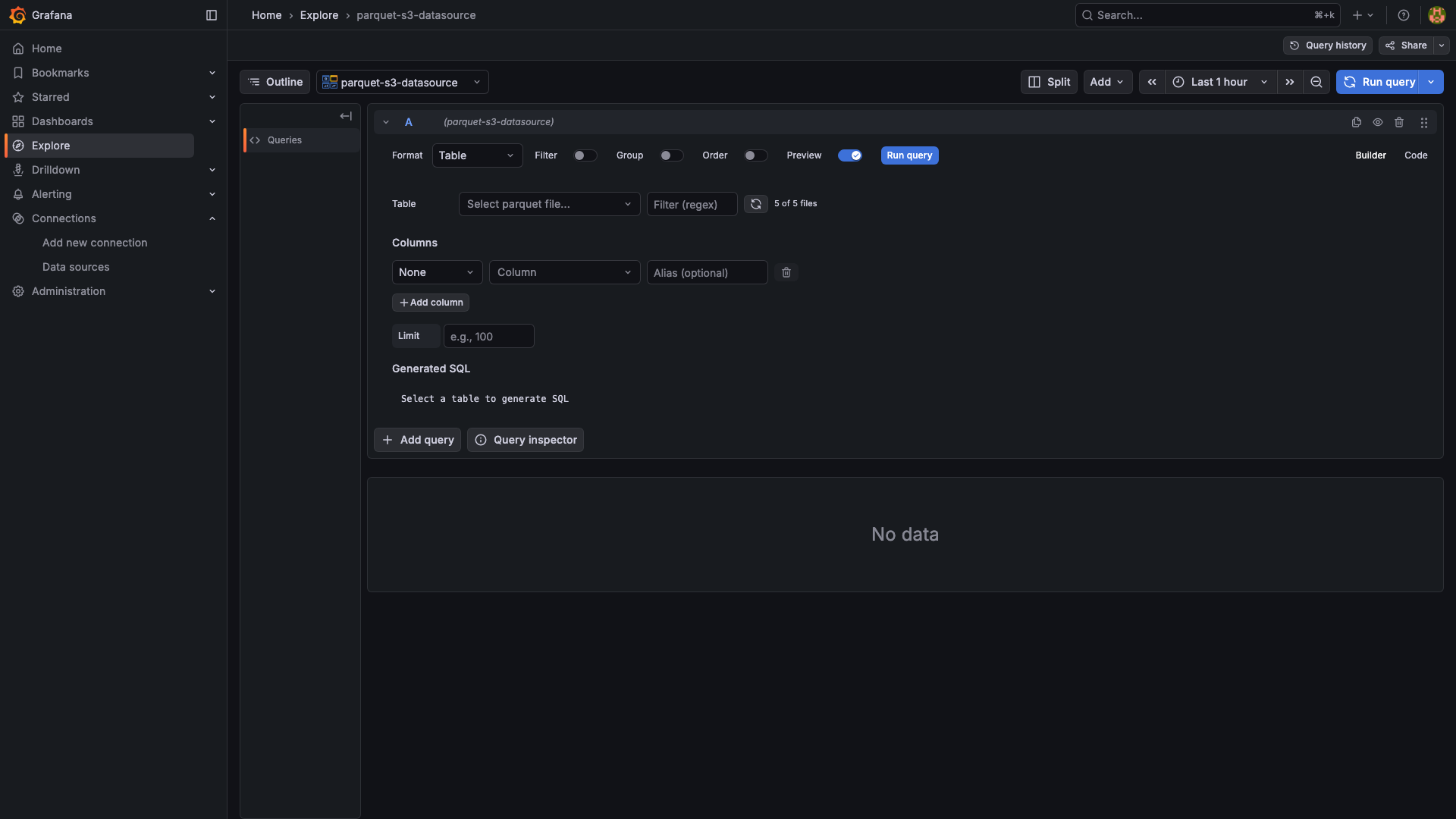
SELECT,WHERE,GROUP BY,ORDER BY,LIMIT, the aggregatesCOUNT,SUM,AVG,MIN,MAX, column aliasing, and the comparison/logic operators=,!=,>,<,>=,<=,LIKE,IN,IS NULL,IS NOT NULL,AND,OR. - Visual query builder in Builder mode, raw SQL in Code mode, with a SQL preview as you build.
- Template variables:
buckets(),files(prefix),prefixes(prefix), and arbitrary SQL-driven variables. - Alerting: the datasource implements Grafana's alerting interface, so any SQL query can drive an alert rule.
- AWS-SDK auth via
grafana-aws-sdk(access key, default chain, assume-role, instance profile, named profile).
The SQL engine is a custom in-memory executor shipped with the plugin — it is not DuckDB. DuckDB-specific functions, window functions, CTEs, and JOINs are not available.
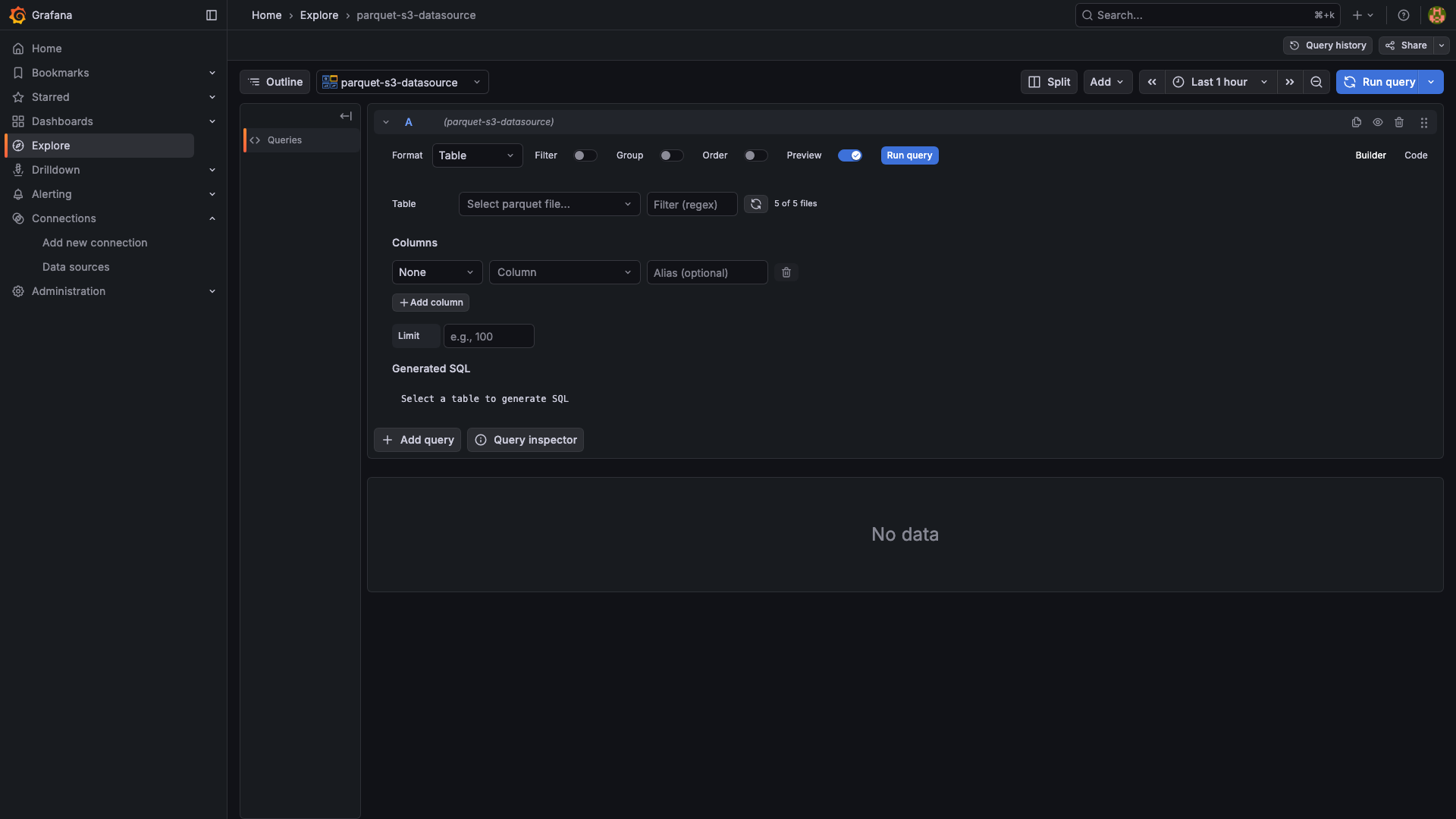
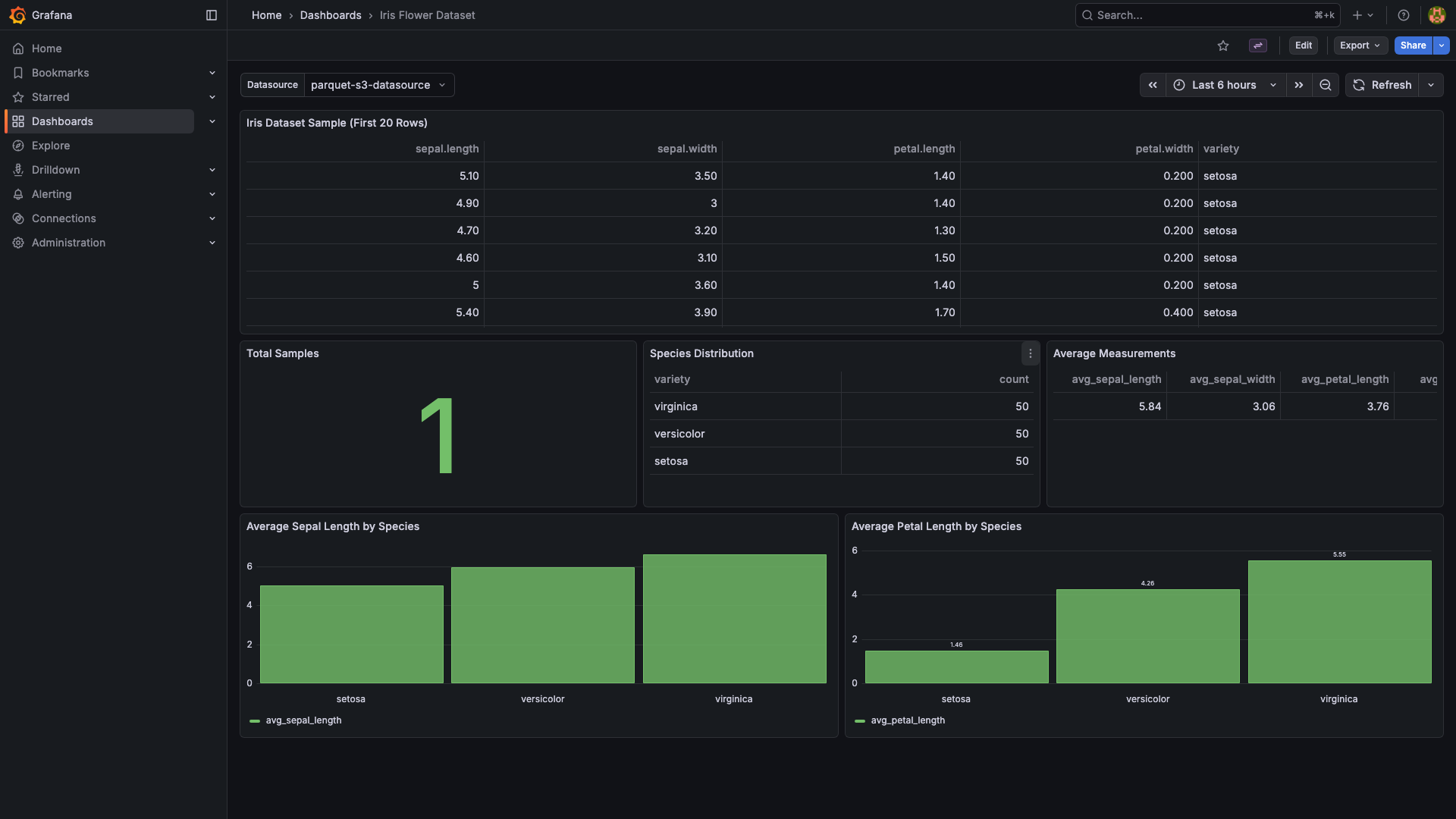
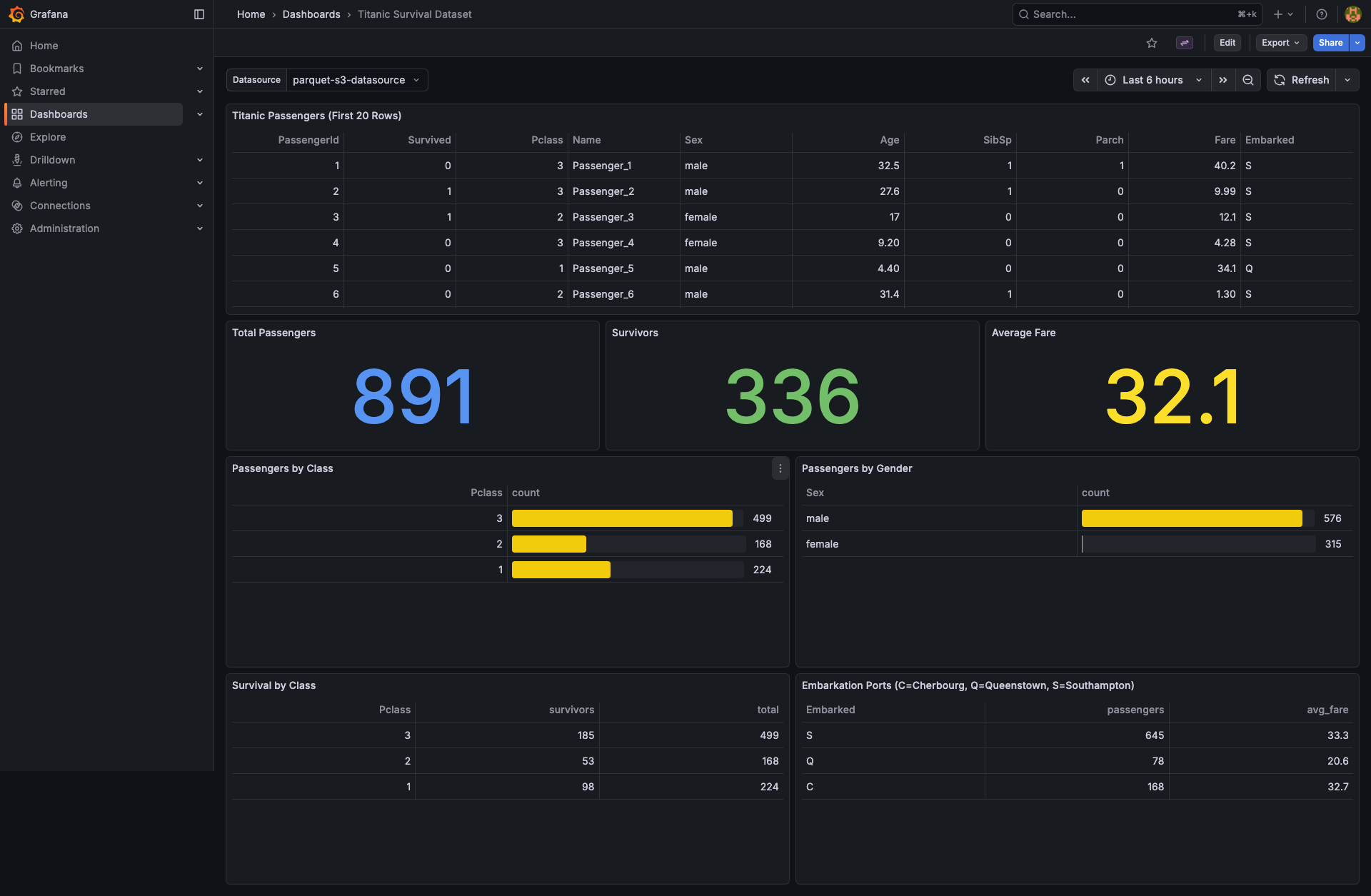
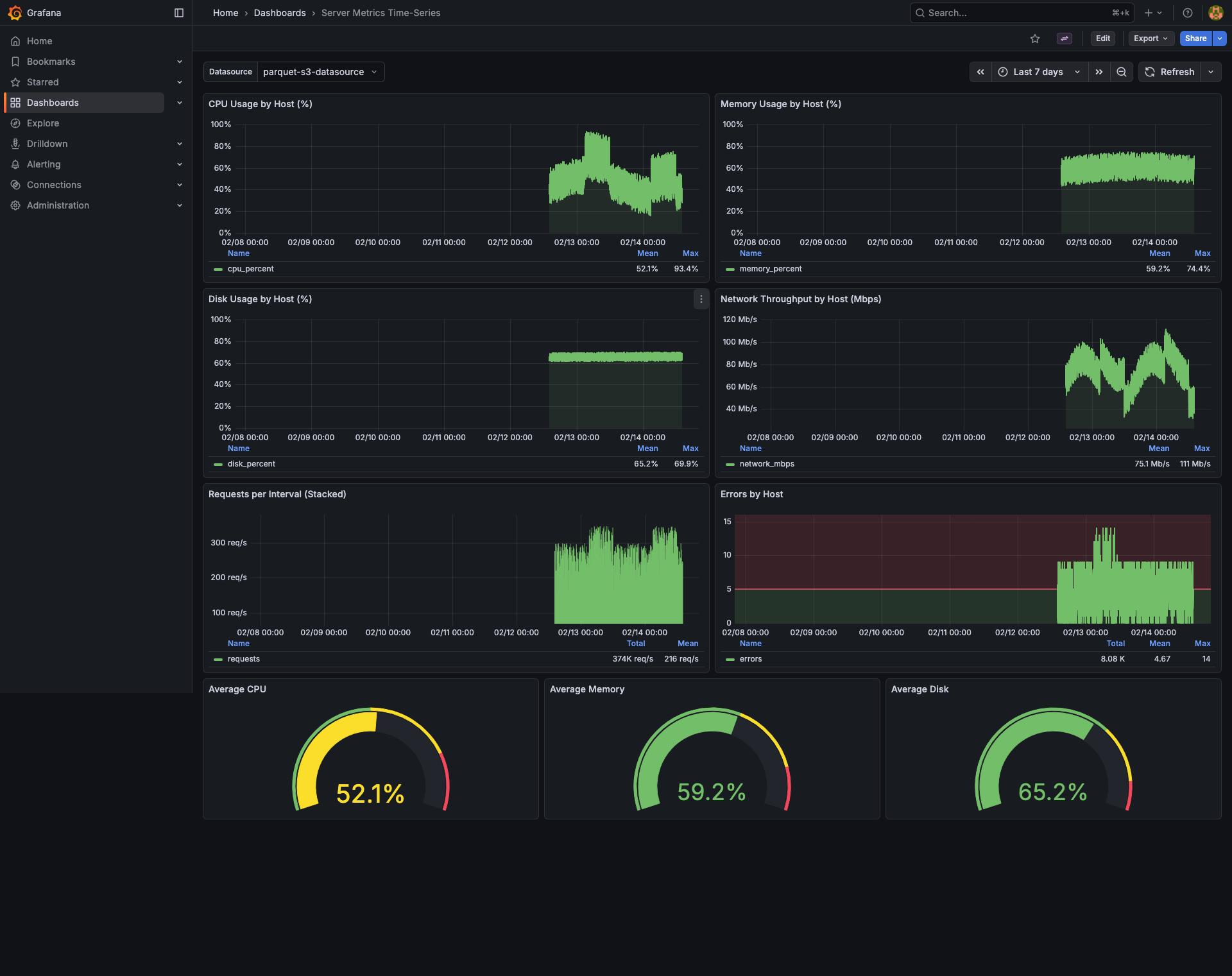
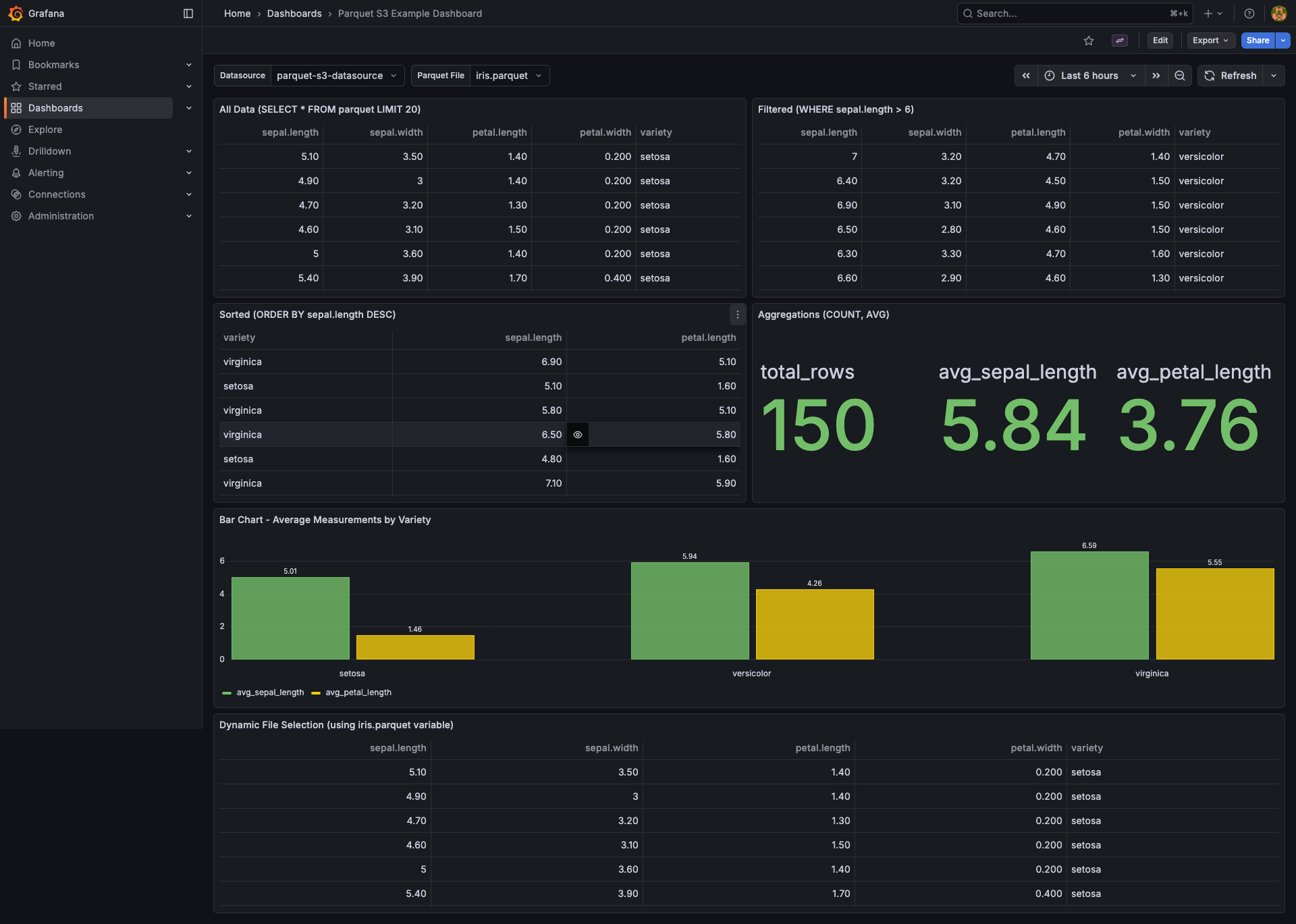
Screenshots
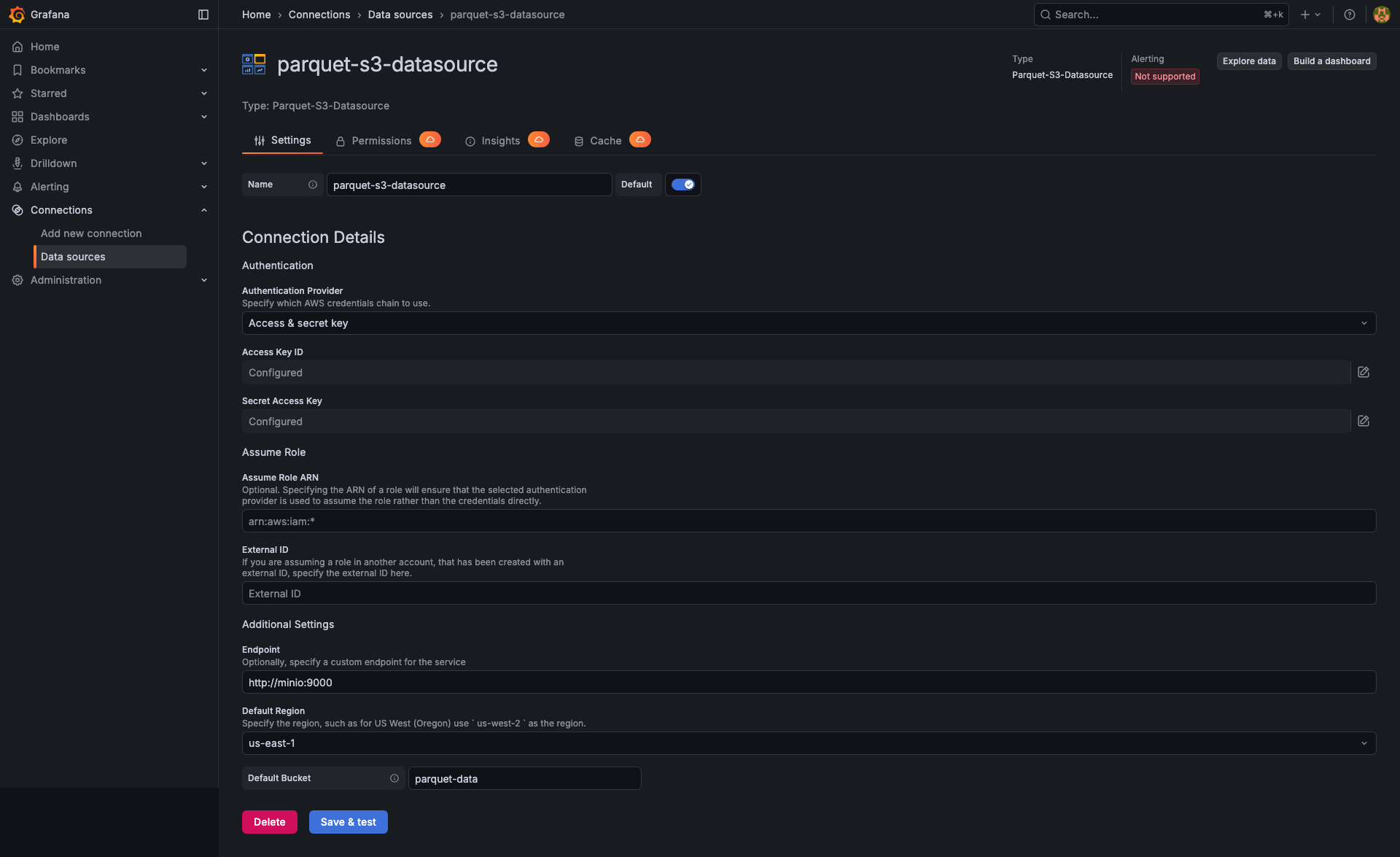
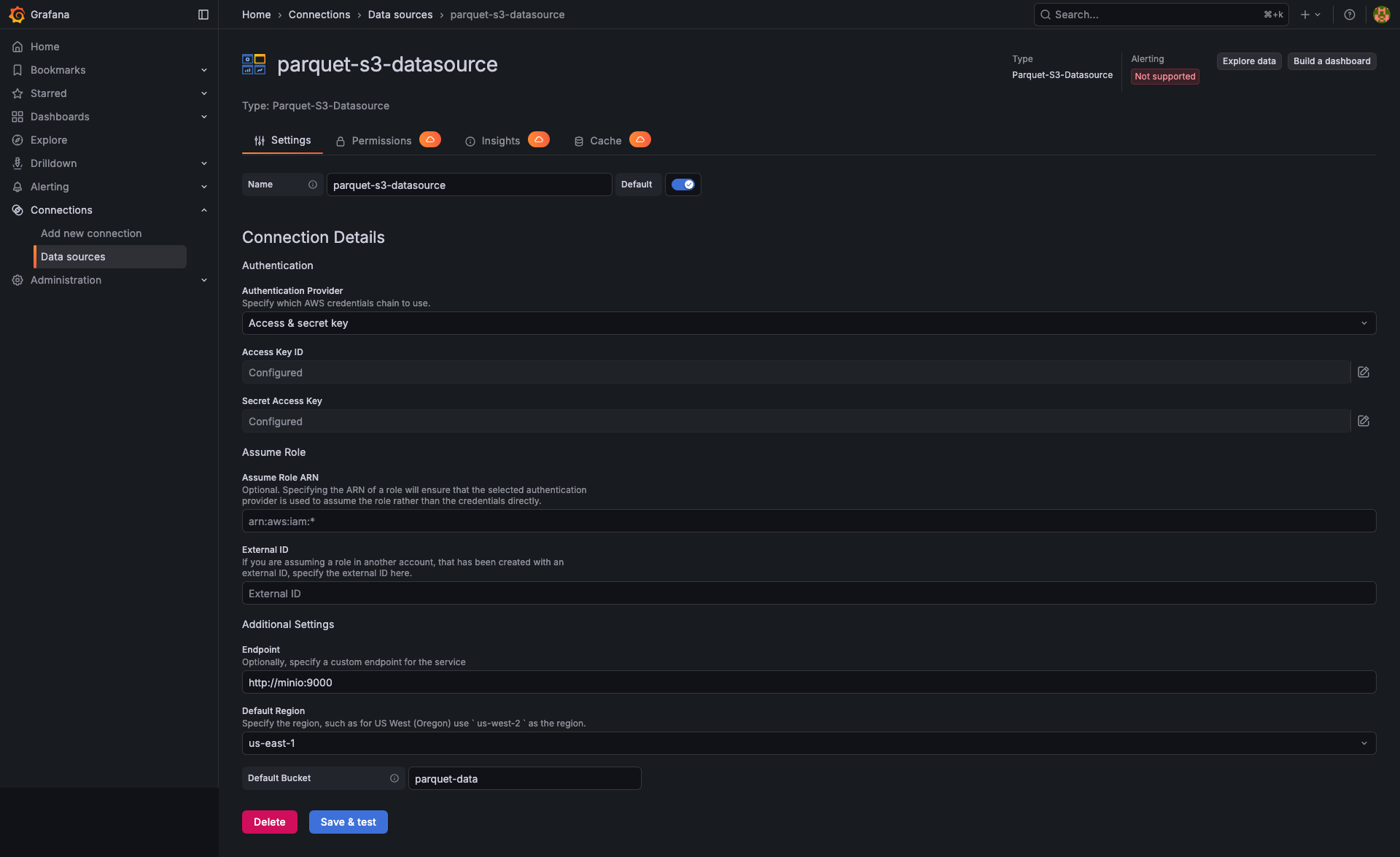
Datasource configuration
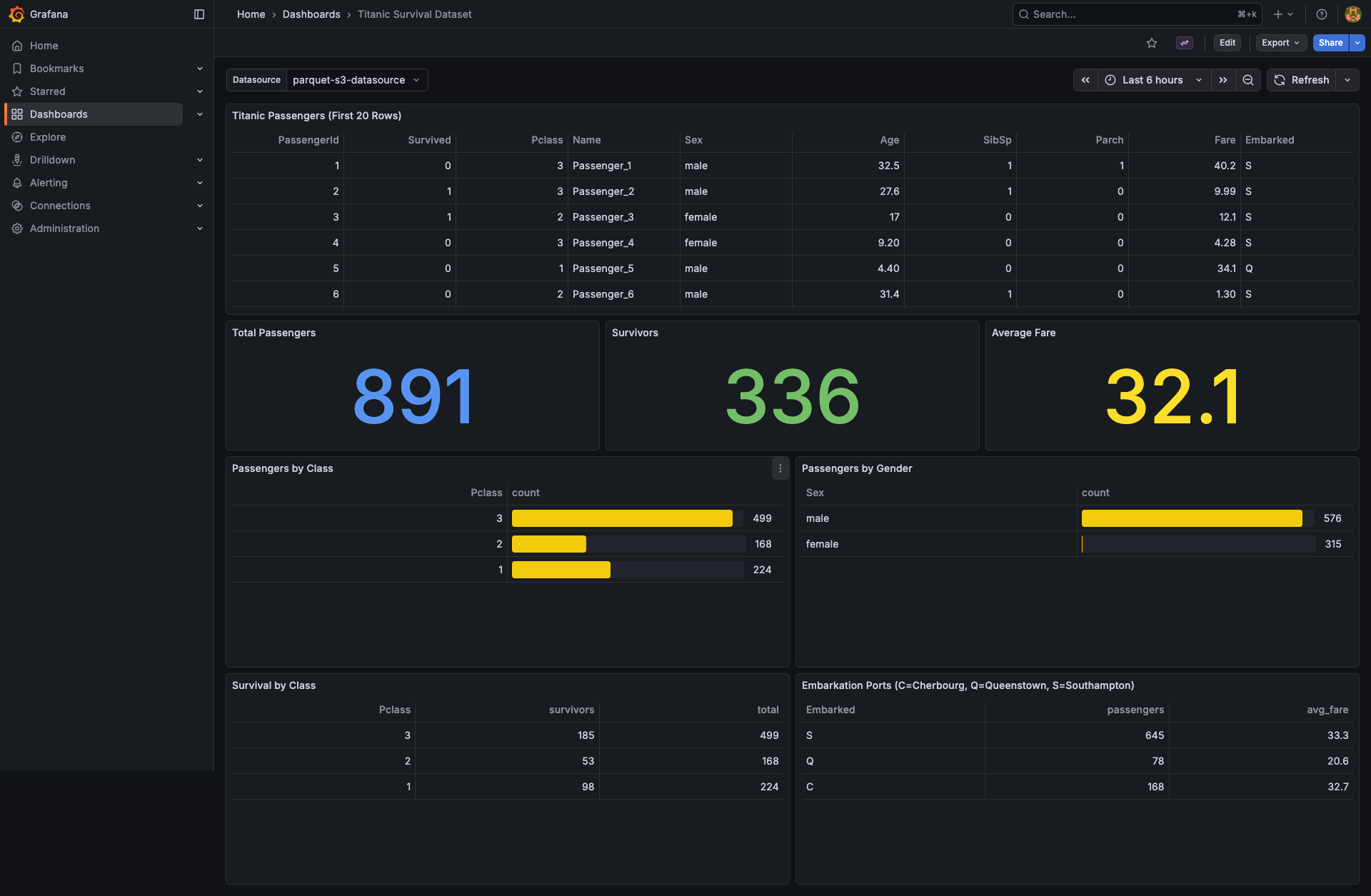
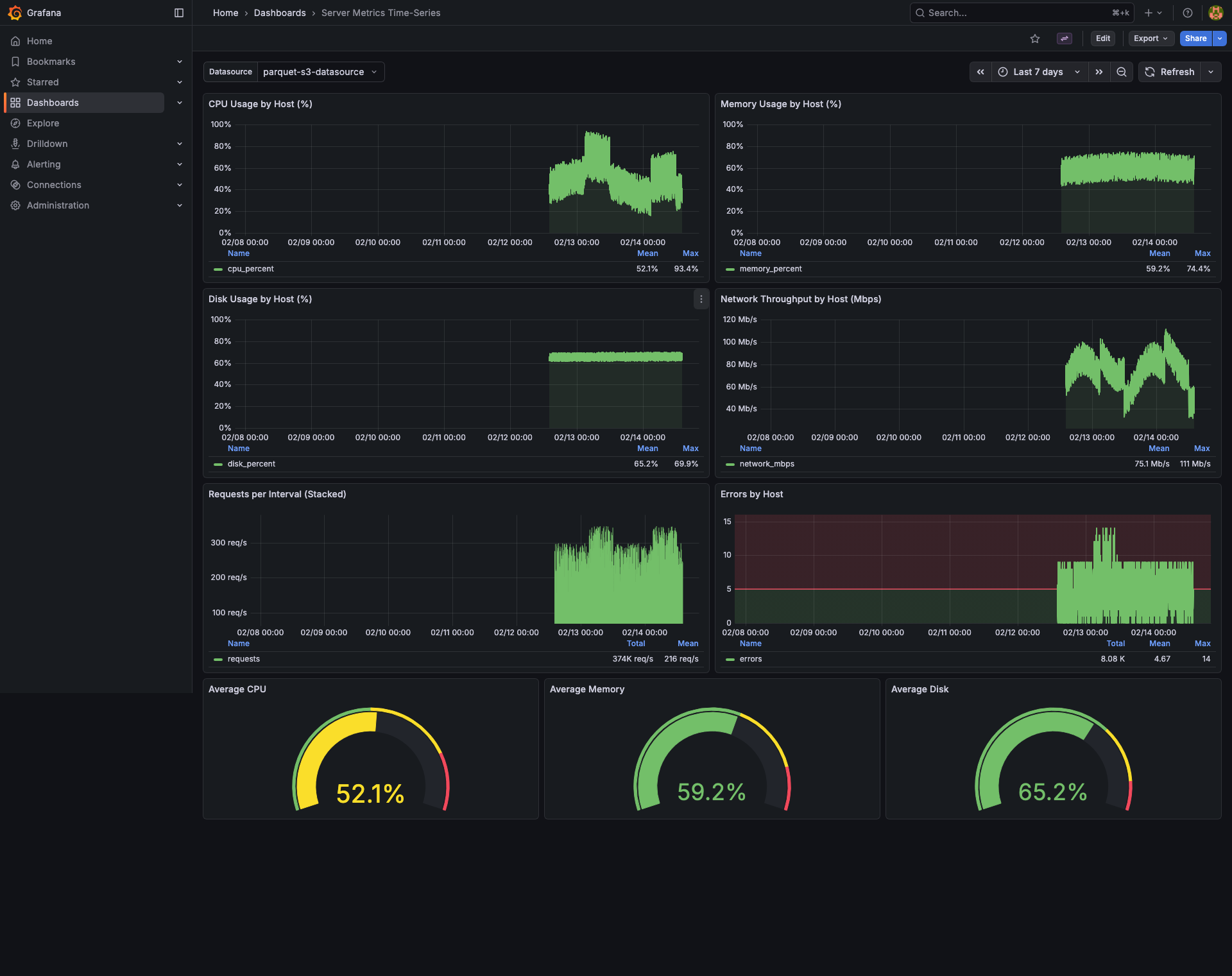
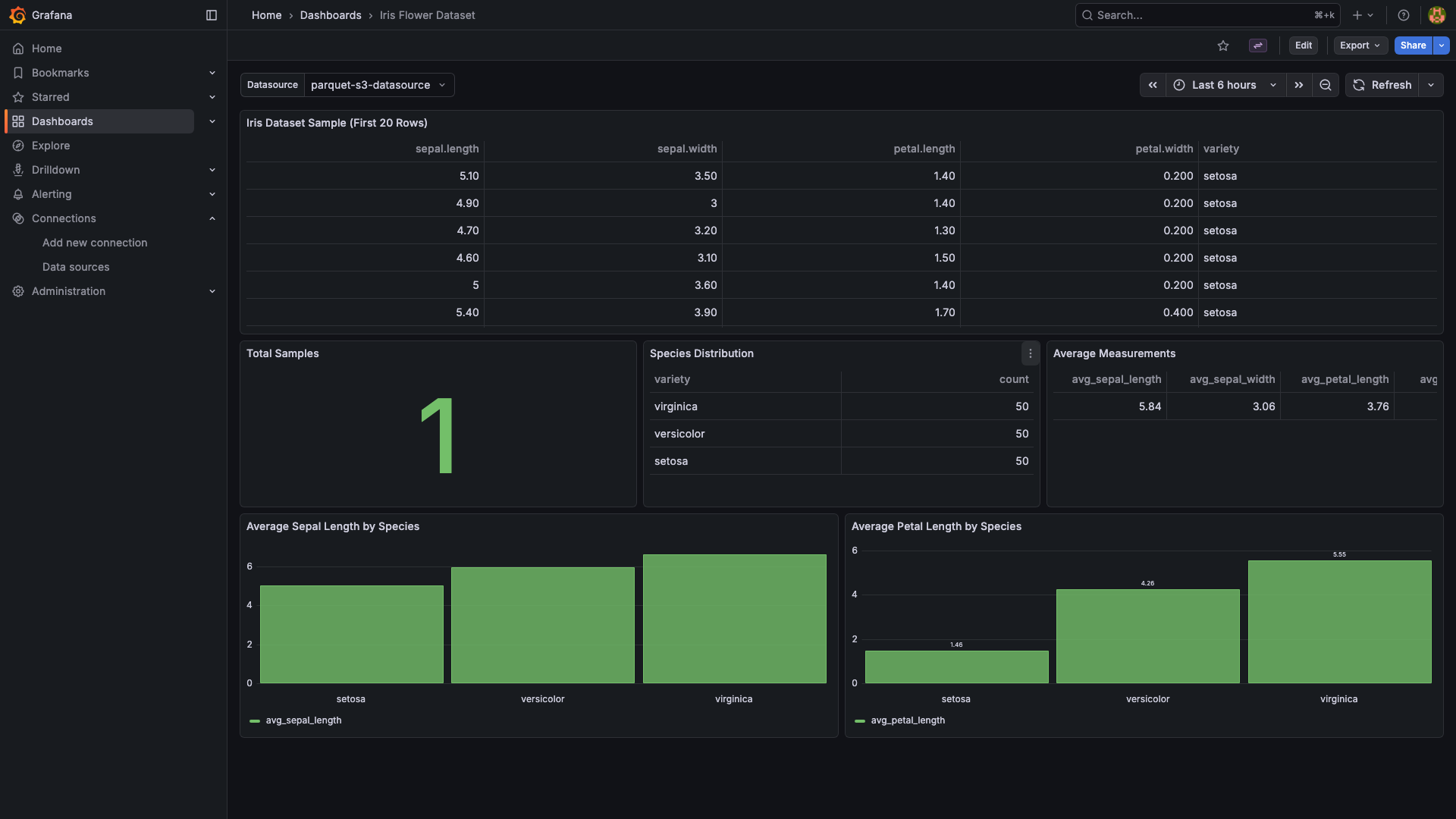
Example dashboards (included as provisioned samples)
Template variables
Requirements
- Grafana >= 11.0.0
- An S3 or S3-compatible bucket containing Parquet files
- Credentials with
s3:ListBucketands3:GetObjecton that bucket
Installation
Using the Grafana CLI:
grafana-cli plugins install tobiasworkstech-parquets3-datasource
Or with the official Grafana Docker image:
docker run -d -p 3000:3000 \
-e GF_INSTALL_PLUGINS=tobiasworkstech-parquets3-datasource \
grafana/grafana
Getting started
Add the datasource: in Grafana, go to Connections → Data sources → Add data source and pick Parquet-S3-Datasource.
Configure the connection:
- Region — the AWS region your bucket lives in (e.g.
us-east-1). Required by the SDK even for S3-compatible providers. - Bucket — the bucket to query.
- Endpoint (optional) — override the S3 endpoint URL for non-AWS providers (e.g.
https://minio.example.com,https://<account>.r2.cloudflarestorage.com). - Authentication type — choose between AWS SDK Default, Access & Secret Key, Credentials File, EC2 IAM Role, or Assume Role. For static keys, supply the Access Key and Secret Key.
- Region — the AWS region your bucket lives in (e.g.
Click Save & test. A green check means Grafana could authenticate and list the bucket.
Build a query: add a panel, pick the datasource, choose a Parquet file, then either let the builder generate SQL or switch to Code mode and write your own:
SELECT timestamp, host, cpu_percent FROM parquet WHERE host = 'web-01' ORDER BY timestamp DESC LIMIT 500FROM parquetis a placeholder — the actual Parquet file is determined by the Path field in the query editor.
Query examples
-- All rows, all columns
SELECT * FROM parquet
– Filter + sort
SELECT name, value FROM parquet
WHERE value > 100
ORDER BY value DESC
– GROUP BY + aggregates + alias
SELECT category,
COUNT(*) AS count,
AVG(price) AS avg_price
FROM parquet
GROUP BY category
– Most recent N rows
SELECT * FROM parquet
ORDER BY timestamp DESC
LIMIT 100
Template variables
| Query Type | What it returns | Inputs |
|---|---|---|
List Files | Object keys in the bucket matching a glob (*.parquet default) | Optional prefix, file pattern |
Prefixes | Top-level "folders" under a prefix (uses Delimiter=/) | Optional prefix |
SQL Query | First column of a SQL query, deduplicated | Path + SQL query |
Examples:
- All parquet files in the bucket: Query Type =
List Files, File Pattern =*.parquet. - Files in a folder: Query Type =
List Files, Prefix =data/2026/, File Pattern =*.parquet. - Distinct values from a column: Query Type =
SQL Query, Path =data.parquet, SQL =SELECT DISTINCT category FROM parquet.
Configuration examples
Amazon S3
Region: us-east-1
Bucket: my-data-lake
Endpoint: (leave empty)
Auth: Access & Secret Key (or Assume Role / Default chain)
MinIO (self-hosted, path-style)
Region: us-east-1
Bucket: parquet-data
Endpoint: http://minio.internal:9000
Auth: Access & Secret Key
Path-style routing is enabled automatically when a custom endpoint is set.
Cloudflare R2
Region: auto
Bucket: my-bucket
Endpoint: https://<account-id>.r2.cloudflarestorage.com
Auth: Access & Secret Key
Wasabi
Region: us-east-1
Bucket: my-bucket
Endpoint: https://s3.wasabisys.com
Auth: Access & Secret Key
Alerting
plugin.json declares "alerting": true, so any query you can write in this datasource can drive a Grafana alert rule. The bundled example (provisioning/alerting/alerts.yml in the repo) shows a "High CPU" rule built from SELECT AVG(cpu_percent) FROM parquet.
Supported Parquet features
- Primitive types:
INT8/16/32/64,UINT32/64,FLOAT32/64,BOOLEAN,STRING,LARGE_STRING,TIMESTAMP(ns/µs/ms/s). - Compression codecs handled by Arrow:
SNAPPY,GZIP,LZ4,ZSTD,BROTLI. - Column pruning when only a subset of columns is selected.
- Schema discovery via the Parquet footer — the column list for a file is fetched without downloading the whole file.
Nested types (STRUCT, LIST, MAP) are read using their Arrow string representation; explicit nested-projection support is on the roadmap.
Troubleshooting
Save & testfails with connection error — verify the region, bucket name, endpoint URL, and that the credentials haves3:ListBucketands3:GetObject. For self-signed endpoints, make sure the Grafana host trusts the certificate.- No data returned — confirm the file path matches an object key in the bucket (case-sensitive, no leading slash). Use a
List Filestemplate variable to discover keys. - SQL errors — column names are case-insensitive but must exist; quote names with special characters using double quotes (
"foo.bar"). Only the SQL subset documented above is supported. - Slow queries — the engine reads the full file for non-aggregated queries. Push selectivity into a smaller file or partition by writing your Parquet files with a prefix per time window (e.g.
metrics/2026/05/20/...).
Source, issues, and contributing
The plugin is open-source (Apache 2.0). Source, issue tracker, and release notes live at:
https://github.com/tobiasworkstech/tobiasworkstech-parquets3-datasource
Bug reports, feature requests, and pull requests are welcome.
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Install on Grafana Cloud
Plugins can be installed directly from within your Grafana instance or automated using the Cloud API or Terraform.
Learn more about plugin installationMarketplace plugins
This is a paid plugin developed by a marketplace partner. To purchase an entitlement, sign in first, then fill out the contact form.
Get this plugin
This is a paid for plugin developed by a marketplace partner. To purchase entitlement please fill out the contact us form.
What to expect:
- Grafana Labs will reach out to discuss your needs
- Payment will be taken by Grafana Labs
- Once purchased the plugin will be available for you to install (cloud) or a signed version will be provided (on-premise)
Thank you! We will be in touch.
For more information, visit the docs on plugin installation.
Installing on a local Grafana:
For local instances, plugins are installed and updated via a simple CLI command. Plugins are not updated automatically, however you will be notified when updates are available right within your Grafana.
1. Install the Data Source
Use the grafana-cli tool to install Parquet-S3-Datasource from the commandline:
grafana-cli plugins install The plugin will be installed into your grafana plugins directory; the default is /var/lib/grafana/plugins. More information on the cli tool.
Alternatively, you can manually download the .zip file for your architecture below and unpack it into your grafana plugins directory.
Alternatively, you can manually download the .zip file and unpack it into your grafana plugins directory.
2. Configure the Data Source
Accessed from the Grafana main menu, newly installed data sources can be added immediately within the Data Sources section.
Next, click the Add data source button in the upper right. The data source will be available for selection in the Type select box.
To see a list of installed data sources, click the Plugins item in the main menu. Both core data sources and installed data sources will appear.
Changelog
All notable changes to this project will be documented in this file.
[1.2.15] - 2026-05-20
Build
- Drop 32-bit
linux/armbinary. Apache Thrift v0.23.0 (required to fix CVE-2026-41602) usesmath.MaxUint32as an untypedintconstant inframed_transport.go, which overflows on 32-bit architectures. 32-bit ARM is rarely used to run Grafana (RPi 4+ is arm64), so the artifact is dropped rather than staying on the vulnerable Thrift version. A customBuildAlltarget inMagefile.gobuilds the remaining five platforms (linux amd64/arm64, darwin amd64/arm64, windows amd64). - Refresh
grafana-plugin-sdk-goto v0.292.0 to clear the validator's "SDK older than 2 months" warning.
[1.2.13] - 2026-05-20
Bug Fixes
- S3 list pagination:
listPrefixesandlistFilesnow page throughListObjectsV2results so buckets with more than 1000 objects are not silently truncated.
Improvements
- Schema discovery without full read:
SELECT * FROM parquet LIMIT 0(used by the frontend to fetch column names) now reads only the Parquet footer viaarrowReader.Schema()instead of downloading the entire file from S3. - Renamed
pkg/duckdb→pkg/sqlexec: the package never used DuckDB; the new name reflects what it actually is — a small in-memory SQL executor. - Plugin README: replaced the
@grafana/create-plugintemplatesrc/README.mdwith proper, screenshot-rich documentation that is bundled into the published plugin.
[1.2.0] - 2026-02-14
Bug Fixes
- Fix LARGE_STRING Parquet panic: Pandas-generated Parquet files use
LARGE_STRINGArrow type, which caused a panic in the Parquet reader. Separatedarrow.LARGE_STRINGandarrow.STRINGhandling with proper type assertions. - Fix GROUP BY not aggregating: GROUP BY queries returned one row per record instead of grouped results. The SQL executor was using pointer addresses as group keys (
*int64,*string). AddedformatValue()helper to dereference pointers before grouping. - Fix Titanic dashboard bar charts: Grafana barchart panels require a string x-axis but
Pclassis int64. Changed to table panels with gauge cell rendering.
Improvements
- Added Playwright E2E tests verifying all 4 provisioned dashboards load with correct data
- Added Docker Compose dev environment (
docker/docker-compose.yml) with MinIO and sample data generation - Updated all provisioned dashboard JSON files for Grafana compatibility
- Added
CLAUDE.mdproject documentation
[1.1.0] - 2026-02-02
Features
- SQL Query Support: Built-in, in-memory SQL engine (a custom lightweight executor, not DuckDB)
- SELECT, WHERE, GROUP BY, ORDER BY, LIMIT clauses
- Aggregation functions (COUNT, SUM, AVG, MIN, MAX)
- Filtering and sorting
- Visual Query Builder: PostgreSQL-style query builder interface
- Column selection with aggregations
- Filter toggle with condition builder
- Group By toggle with multi-column selection
- Order By toggle with ASC/DESC
- SQL Preview panel showing generated query
- Template Variables: Support for dashboard template variables
- List files in bucket (with regex filtering)
- List prefixes/folders
- SQL-based variable queries
- Explore View: Enhanced query editor for Grafana Explore
- File selector with regex filtering
- Refresh button to reload file list
- Builder and Code modes
- Sample Dashboards: Pre-built dashboards demonstrating plugin capabilities
- Iris Dataset dashboard
- Titanic Survival Dataset dashboard
- Time Series Metrics dashboard
Improvements
- Reduced Grafana version requirement to 11.0.0+
- Better error handling and logging
- Improved path-style routing for S3-compatible storage
- ARM64 binary support for Apple Silicon
[1.0.0] - 2025-12-22
Features
- Initial Release: Parquet-S3-Datasource plugin for Grafana
- S3 Connectivity: Support for Amazon S3 and S3-compatible storage providers:
- Amazon S3
- MinIO
- Wasabi
- DigitalOcean Spaces
- Any S3-compatible storage
- Direct Parquet Querying: Read Apache Parquet files directly from S3 without intermediate databases
- Apache Arrow Integration: Efficient columnar data processing using Apache Arrow
- Custom Endpoints: Configurable S3 endpoints for private cloud deployments
- Path-Style Routing: Automatic configuration for storage systems requiring path-style URLs
- Data Types Support: All Parquet primitive types, nested structures, and compression codecs
- Grafana 11.6+: Fully compatible with Grafana 11.6.0 and above
Components
- React-based frontend with TypeScript
- Go backend utilizing AWS SDK v2
- Docker Compose setup for local development with MinIO
- Comprehensive documentation and configuration examples
- Demo video and screenshots
Configuration
- Region selection
- Bucket specification
- Custom endpoint URLs
- Secure credential management (Access Key/Secret Key)
Development
- Provisioned datasource for quick Docker setup
- Sample Parquet file generation script
- Minio upload utilities
- End-to-end testing capabilities