How MarshallZehr, a private real estate credit platform, uses Grafana Cloud to respond to incidents before clients are impacted
In private real estate financing, the margin between a well-run operation and a struggling one often comes down to information. How quickly can you see a problem forming? How clearly can you trace its origins? How confidently can you tell a client that a system is healthy?
MarshallZehr, a Canadian real estate debt lender and a privately held mortgage broker and administrator based in Waterloo, Ontario, has deployed over $4.5 billion in capital across 500-plus transactions. The firm runs a proprietary mortgage administration platform that serves as the operational backbone for its business. Supporting that platform is a four-person technology team responsible for everything from desktop support and infrastructure management to DevOps, security, and ongoing platform development.
When Nicholas Armstrong joined as chief technology officer, that team had no observability strategy. Today, they run Grafana Cloud across their full stack.
The team at MarshallZehr no longer waits to hear about problems. Proactive alerting, driven by telemetry from across the stack, now drives incident response. Anomalies in system behavior are detectable before they surface as user-facing failures.
In private real estate financing, that shift has implications beyond engineering. The ability to respond to an incident before a client is affected is not simply an operational efficiency—it is a service quality commitment made possible by infrastructure investment.
“The alerting capability has allowed us to be very responsive,” Armstrong says. “We no longer have to wait for users to report a problem. We can proactively alert on issues and act in a SRE fashion—responding to incidents based on our telemetry, rather than based on business impacts.”
Starting from zero
The situation Armstrong inherited was less a failure of execution than a product of how the company had grown. Parts of the platform pushed logs into Graylog for analysis, but the tool was used inconsistently. When something broke, the path to diagnosis typically ran directly through the application servers. There was no metrics layer, no visibility into response times or system load, and no baseline against which to measure anything.
Problems surfaced when users reported them.
“We really didn’t have any unified strategy for logs, and we had no metrics whatsoever,” Armstrong says. “That lack of insight into how our application behaved was what really drove the decision.”
For a team of four carrying a mandate that would challenge a team three times its size, the implications were significant. Without telemetry, there was no way to quantify what was slow, identify what was failing, or validate that changes were making things better. Engineering decisions were made without data. Improvements could not be measured. The team was operating in the dark about its own systems.
A deliberate start
Armstrong addressed that visibility gap methodically. He began with a controlled deployment: self-hosted Prometheus and Grafana OSS running on Amazon ECS, targeting the platform specifically. The goal was not broad coverage from the start—it was meaningful insight into a defined scope, built on a foundation he could trust.
The initial rollout confirmed the value of the approach quickly. Visibility into the platform’s behavior that had never existed before was now available in dashboards. The team could see response times, identify load patterns, and correlate log data with system metrics.
But after several months, a different pattern had also emerged. Hosting the observability infrastructure was generating its own operational load. Maintenance, reliability management, and keeping the stack current all demanded attention. For a four-person team already stretched across infrastructure, security, and active platform development, that overhead had a compounding cost.
The decision to migrate to Grafana Cloud followed.
“Not only did I get a fully hosted solution, I got something that was very reliable and did not require maintenance,” Armstrong explains. “It represents really good value.”
Building out the full stack
With the operational burden of self-hosting removed, the team expanded. MarshallZehr moved to the full Grafana Cloud stack for logs, unified visualization, and long-term metrics storage. For the first time, they had full-stack visibility in a single platform, rather than dispersed across disconnected tools and direct server access.
One of the more consequential changes came with the adoption of Alloy for collecting, processing, and exporting telemetry signals. The previous collection model relied on a centralized Prometheus scraper—a single aggregation point pulling telemetry from across the infrastructure. Alloy enabled a shift to a distributed model in which individual applications and host instances self-scrape and push telemetry directly to Grafana Cloud.
The architectural change is meaningful. A distributed collection model eliminates a single point of failure in the telemetry pipeline, removes bottlenecks as the infrastructure scales, and simplifies onboarding new services—each one responsible for its own instrumentation rather than requiring updates to a centralized configuration. For a small team managing a growing platform, reducing that category of maintenance toil has a real impact on what can be prioritized.
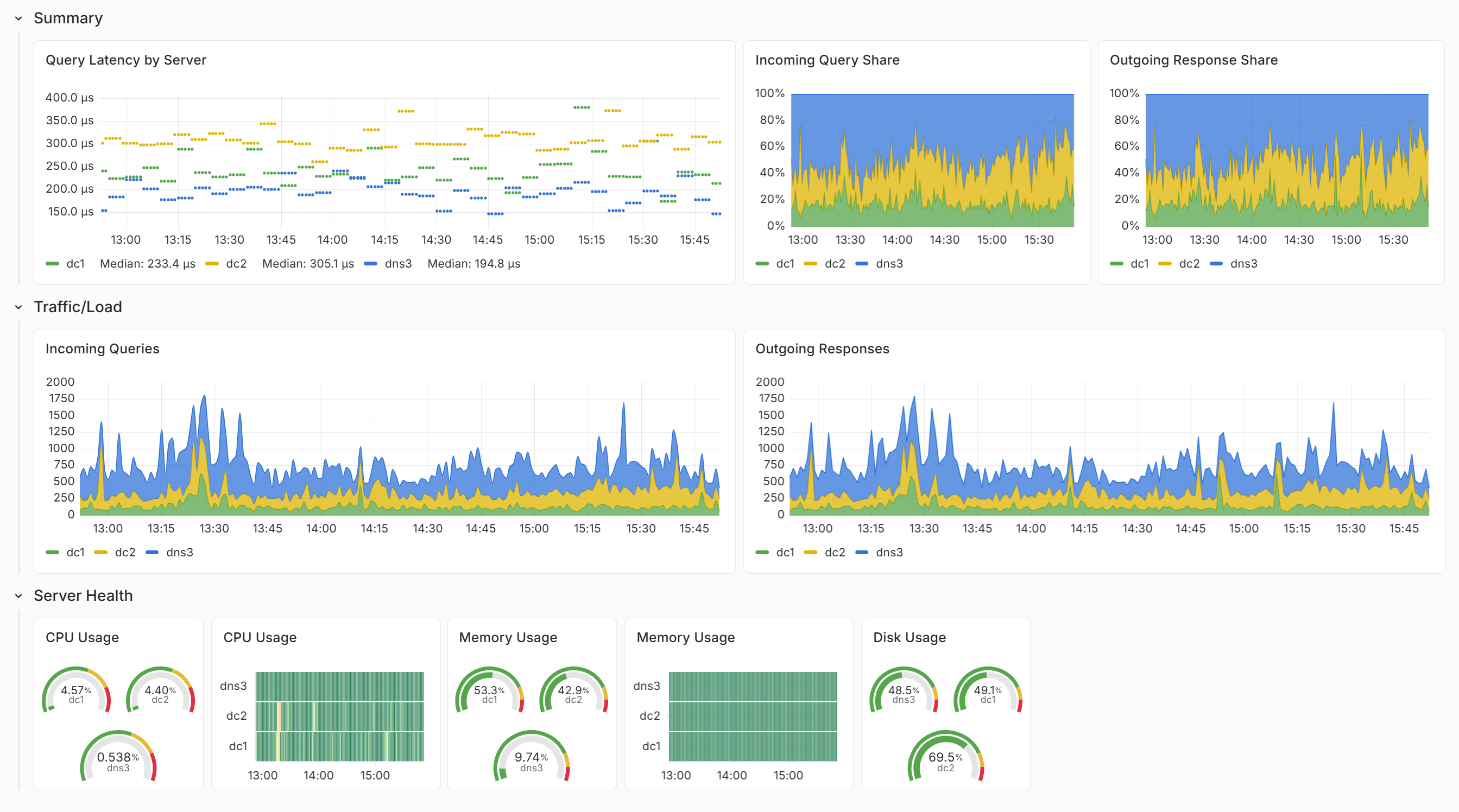
The operational shift
The consolidation of observability into a single platform has also compounded the team’s effectiveness in less visible ways. Fewer tools mean fewer context switches. Unified data means faster diagnosis. The time recaptured from maintenance of a self-hosted stack can be directed toward building the features and improvements to its own platform so they can help move the business forward.
There is also a competitive dimension that Armstrong is direct about. Private mortgage administration is not, by and large, a technically sophisticated industry. The observability practice that MarshallZehr has built gives the firm operational capabilities that most of its peers simply do not have. As a result, they’re better equipped to reduce risk and respond to their users’ needs—and they can do it with a smaller staff than their competitors.
What comes next
Armstrong has mapped out the next stages of the observability practice clearly. Distributed tracing, continuous profiling, and frontend observability are each on the roadmap. Cost-effectiveness is a central consideration at MarshallZehr’s scale—and Grafana’s adaptive capabilities, including adaptive metrics and adaptive logs, are how the team expects to extend coverage without a proportional increase in spend.
Internally, the work is also about culture as much as technology. Armstrong’s team is investing in helping engineers connect observability data to the direct impact of their work—building the feedback loop between code shipped and telemetry returned. Making observability a natural part of how the team builds software is the next phase of a practice that, not long ago, did not exist at all.


