How Opsdis is building custom observability solutions on Grafana Cloud
Companies are always looking for transparency and visibility when it comes to monitoring, but as monitoring requirements and methods evolve, it’s not always easy to keep up. That fact led to an inspired idea by Johannes Dagemark, an entrepreneur with a background in tech, and Anders Håål, a technical consultant experienced in aggregated metrics and event data. In 2017, they founded the observability consulting company Opsdis. Based in Göteborg, Sweden, Opsdis focuses solely on helping clients implement systems for monitoring and metrics so they can keep up with the ever-expanding world of cloud computing and containerized environments.
The firm works with many companies in the health care and transportation sectors, and several of its projects have centered on building automation for clients. “For many customers, we’ve also tried to bridge them over from their classic infrastructure monitoring and have them start to use that as a source for Grafana, for example,” says Håål, who is now Opsdis’ CTO. “If you have classic node-based monitoring, you want to start to look at all these metrics in a smarter way.”
In September 2020, the company joined Grafana Labs’ partnerships program, which offers specialized support and growth opportunities for service providers who build Grafana-based solutions to meet their customers’ observability, monitoring, and data visualization goals. “The tool stack that Grafana Labs is promoting is really key for us,” Håål says. “It makes so much sense, especially now with the introduction of Loki, and the combination of advanced logs and metrics.”
You don’t have to think about internal servers, an infrastructure setup, or anything complicated like that. You can focus on the functionality you want to achieve with your observability instead.
Anders Håål, CTO, Opsdis
One of the features of Loki that Håål likes in particular for his clients is that it takes up less disk and memory space than most other logging solutions. “Loki is lighter to design and there are absolutely less resources to consume,” he explains.
A weighty issue
Last year, Opsdis was contacted by Cind AB, a Swedish company that uses innovative 3-D camera technology to measure the weight and volume of objects, such as bulk packages on a conveyor belt or the size of a lumber load on a truck.
At the time, Cind only had manual monitoring processes. If there was a problem, a customer would have to call the company to tell them that something was wrong at their site, which might be a warehouse or lumberyard. Then, Cind’s support team would use SSH to remotely connect to the site and try to manually grep through each and every log file — all of which were created locally to each customer site — and see if all the processes were running. “It was a non-proactive way of understanding the quality of each customer’s site,” Håål explains. Adding to the difficulty, as Cind began to add more and more customers, that process became increasingly inefficient.
Cind asked Opsdis to come up with a new observability solution for their sites that could monitor the health and state of key system processes and onsite cameras, as well as gather logs from the entire system.
Cind’s customers are distributed around the world, so it also required a monitoring solution that could be implemented locally at each customer site. On top of that, the company wanted visibility across those sites so its operations team wouldn’t have to log into individual customer sites to receive alerts, track down issues, grep through log files, or check on statues.
And of course, Opsdis needed to provide a system that was easily scalable for the fast-growing company, which currently has more than 50 sites.
Picturing a solution
One bright side of Cind not having a legacy monitoring solution in place was that Håål and the Opsdis team didn’t have to worry about building anything custom or new on top an existing platform, nor did they have to worry about the hassle of migrating any data. The big change, however, came from how they logged data and where it was stored.
Opsdis developed a monitoring system for Cind using Prometheus, Loki, and Grafana, along with the fully managed Grafana Cloud offering. “Grafana Cloud is simple to use and simple to get going with,” Håål says. “You just sign up for an account and you get everything you need. You don’t have to think about internal servers, an infrastructure setup, or anything complicated like that. You can focus on the functionality you want to achieve with your observability instead.”
At each of the sites, Opsdis installed Prometheus, Promtail, and exporters that monitor everything that goes on at each location. Once logs and metrics are retrieved, they’re pushed to Grafana Cloud with remote_write.
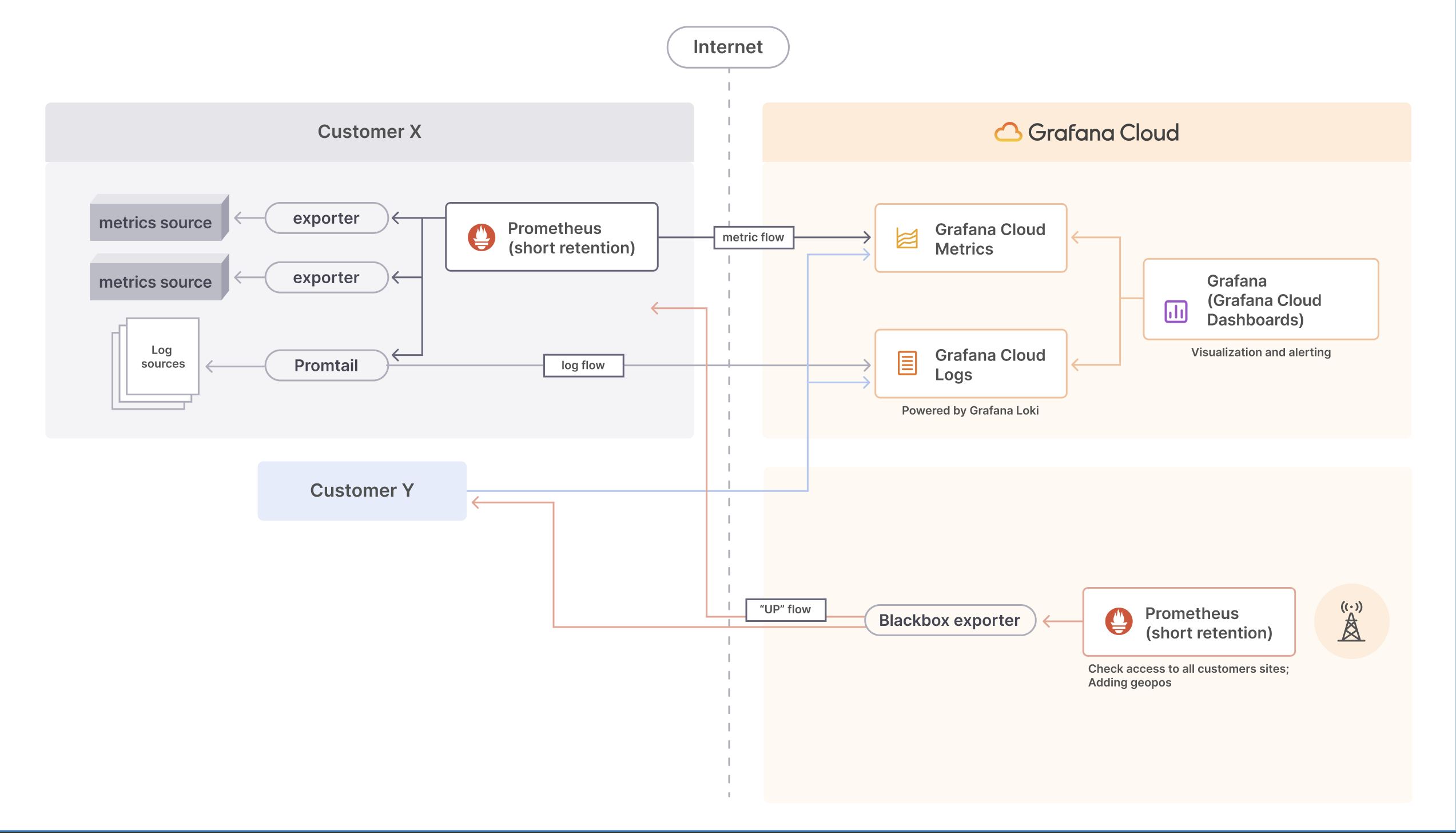
As a result, the Cind operations team is able to see across all of its customers’ sites in real time, know if they were up and running, and check on the status of each and every one of their cameras: Are they functioning? How’s the quality? What are their temperatures? Is all of the system software running as expected?
There were other ways Opsdis could have approached a solution, Håål says, but he reiterated that “simplicity of the Grafana stack was the more important factor.”
Prometheus comes with its own set of benefits, he added, including the fact that the community creates so many of its own exporters, making it easy to find what you need. “There is also a community of knowledge around how to use these tools, which makes it easy to enter.”
One feature he likes about Loki — and that makes it a great choice for Opsdis’ clients — is that log queries are easy for anyone already familiar with PromQL. “And then you can combine Prometheus and Loki, like we do in the Cind case,” Håål says. “We take logs, and when they’re processed by promtail, we create metrics that are scraped by Prometheus directly to the local promtail. So it’s not a big step to get started.”
Håål likes pairing all of that with Grafana Cloud because it gives him less to worry about. “I don’t have to focus on installing Grafana, or installing a multi-tenant Prometheus instance, or think about how logs are indexed and how many I can have,” he explains. “I can just get started with Prometheus, promtail, and a local installation to get the data in.”
After that, a client can explore the data, what it means, and what can be done with it.
Seeing success
“Working with Opsdis gave us a complete new insight into our customers’ sites and the state of the operations”, says Marcus Schelin, CEO at Cind. “Now we have an automated observability platform with metrics and logs that we can continue to build on.”
Cind’s operations team uses a few templated dashboards in Grafana. There’s an overview map where the company can see the statuses of all of its customers (below).
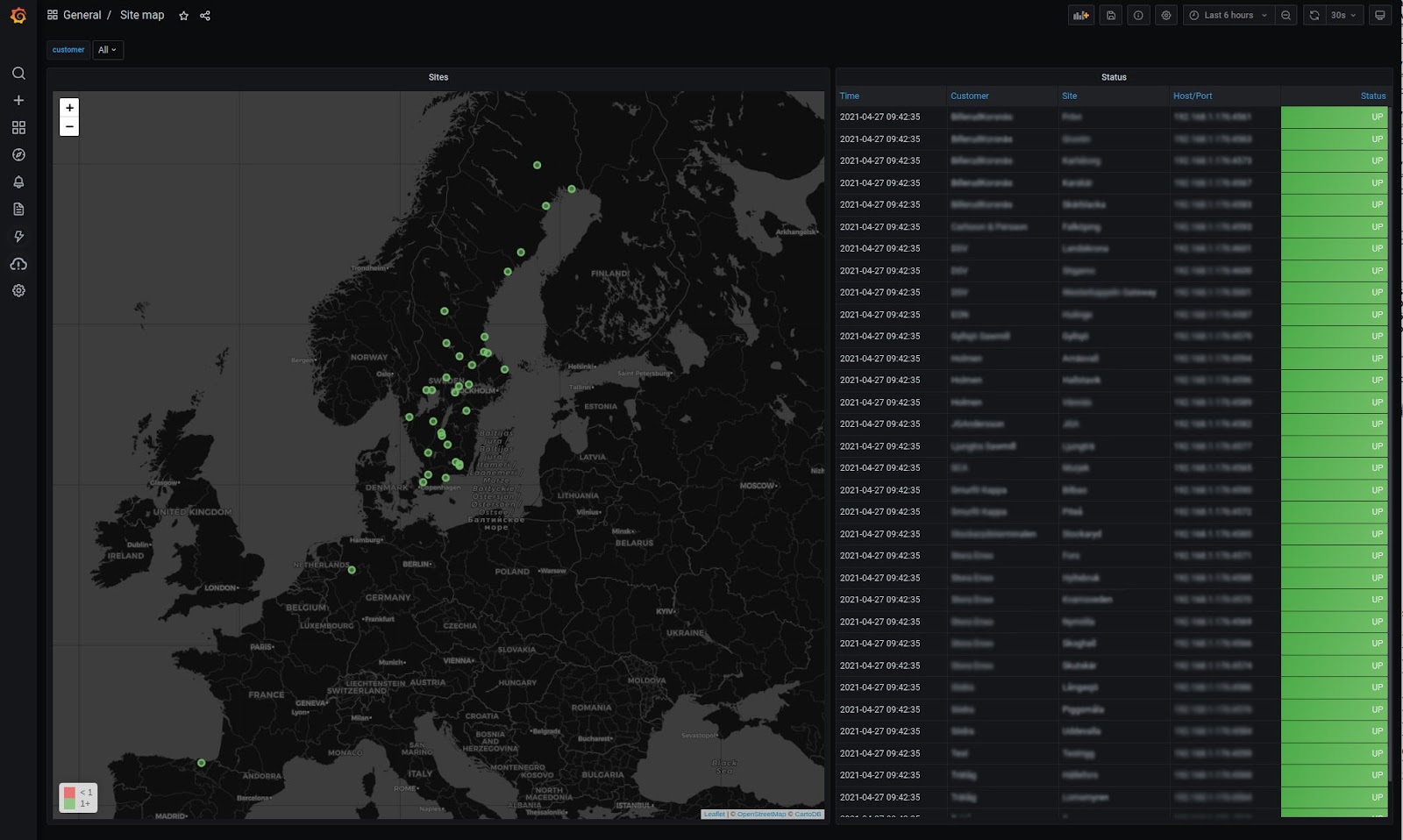
Cind can then narrow down the view to sites belonging to one customer.

And finally, the team can look at site-specific dashboards, which are designed the same for all locations. The panels include temperature data, camera statuses, the state of site processes, and other key information.
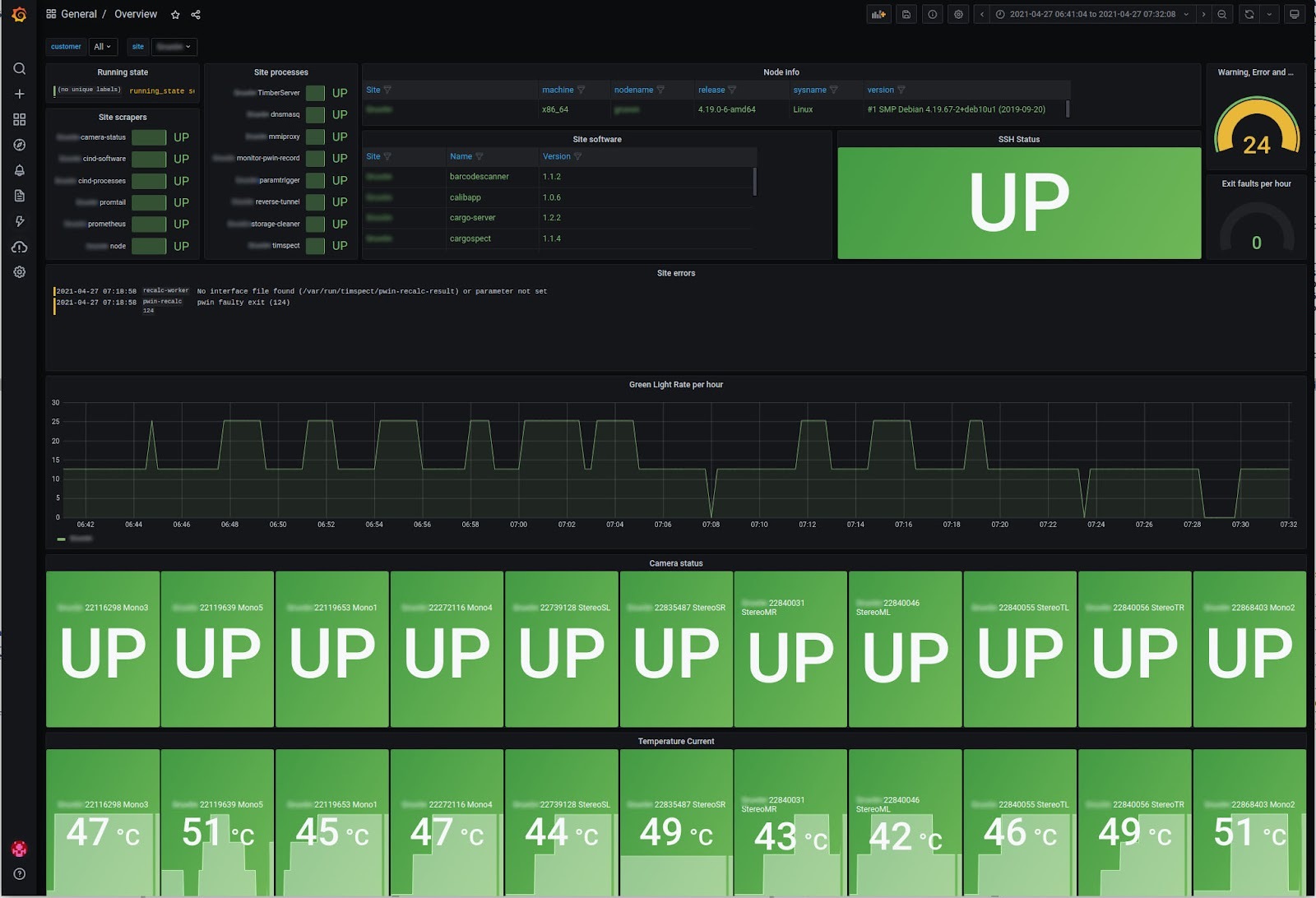
“What they got is a central view of all their customers that they didn’t have before,” Håål says. Not only can Cind reach the logs and calculate metrics on the fly, but the new monitoring system has also given the company a way to manage its data and use the information in meaningful ways, such as using Loki for log discovery and forensics.
Cind’s support team has created a number of alerts which are defined in Prometheus or Cortex. When an alert is triggered at a site, the Cind support team receives it through Slack. Since they’re also able to look at historical trends, now they can understand how their equipment has changed or moved over time. The team can even solve issues before a customer realizes there’s a problem. “Now they have almost all of the customer log data in a central location,” Håål says, “so they can just do queries with Loki’s LogQL query language.”
Thanks to Grafana Cloud, the Cind support team is able to focus their attention on the company’s own services rather than worrying about self-hosted infrastructure. If Cind adds more customers (resulting in more metrics and log data sources) or decides to make changes to its system in the future (like run its own on-premises Cortex or adopt Grafana Enterprise Metrics), the transition will be easy, Håål says. “It doesn’t change anything in terms of what we’ve done on the different customer sites where data is being collected.”
Cind’s new monitoring system left the company intrigued about what it can do next. “This aspect of observability has become part of their own development process,” Håål says. In fact, Cind’s developers have been working on a contexted log format and a data model for how things are named.
Opsdis had created exporters to move data from Cind’s different applications into their own system software, but now, Cind’s developers have created a roadmap to have a native Prometheus API in their system software, so they won’t need to have any exporters between the system software and Prometheus. Håål notes this is typical for his customers as once they see their early successes with the Grafana Stack, the ease of Grafana Cloud allows them to take over, mature their own deployments, and adopt as much of the stack as they need to be successful.
Continuing to grow with Grafana Labs
The team at Opsdis has been more than pleased with their Grafana Labs partnership. Opsdis feels they share the same values as Grafana Labs, and that it’s shown in every aspect of the communications and interactions they’ve had with the company. “And I think if we like how Grafana Labs approaches and supports customers, the customers will like it,” Håål says. Looking ahead, Opsdis hopes to bring Grafana Labs products to more clients, including building an observability platform for network use cases. Håål concludes, “We look forward to continuing our partnership with Grafana Labs and building more custom solutions on Grafana Cloud that allow clients to benefit from open source observability tools without having to worry about managing or scaling their own infrastructure.”