Plugins 〉Multistat

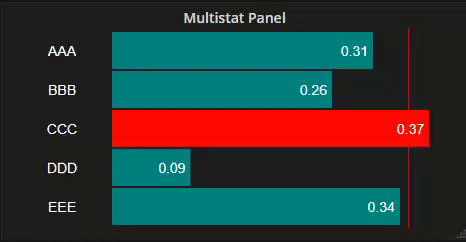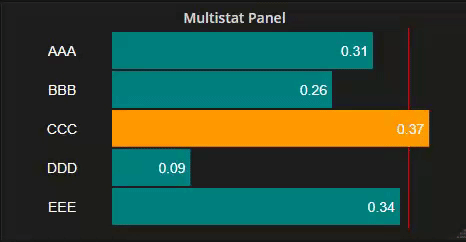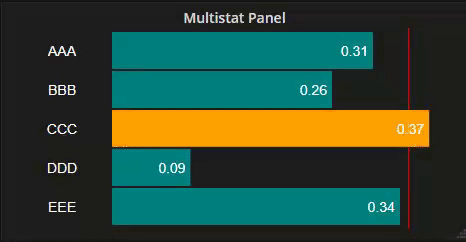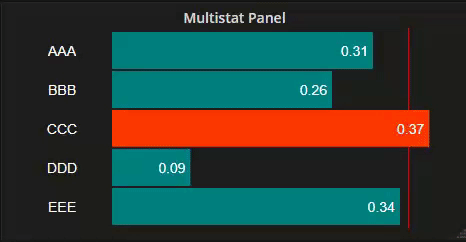
The Multistat plugin has been deprecated and is no longer maintained.
Multistat

michaeldmoore-multistat-panel
New Version (1.3.0) - Now with rules-based bar re-coloring!
New Version (1.4.0) - Now with restyled tooltips and clickable per-bar links!
New Version (1.6.0) - Now with support for multiple value columns per label!
New Version (1.7.0) - Now with support for label/group renaming and date formatting!
(Documentation for these changes is covered in the sections at the very end of this readme file)
Custom multistat panel for Grafana, inspired by the built-in SingleStat panel
This panel was developed for as a table-like panel for presenting bar charts, providing some useful additions particularly suited to process control/monitoring dashboards. As such, Multistat displays never use scroll-bars (scroll bars are useless in monitoring dashboard).
SingleStat displays a single metric from time series data set, with optional threshold-related coloring etc. Multistat builds on this base, but with multi-column table data sets, displaying query data in the form of bar graphs with optional upper and lower hard limits. Plus a lot, lot more....
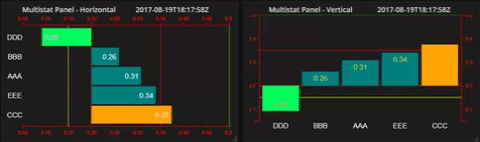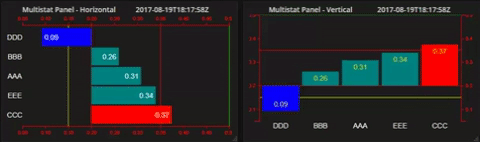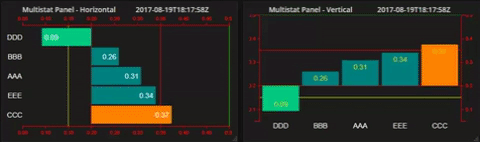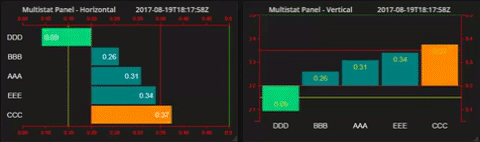
Data can be displayed as vertical bars...
Horizontally...

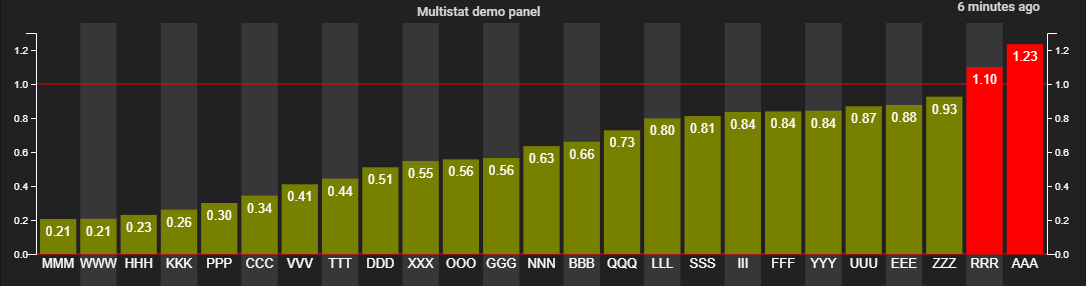
Or grouped on an attribute, again vertically

... or horizontally
 (Note these last two examples are single Multistat panels. A single set of configuration settings is automatically applied to each of the grouped sub-displays)
(Note these last two examples are single Multistat panels. A single set of configuration settings is automatically applied to each of the grouped sub-displays)
And (just about) everything is configurable... Max, Min, auto-scaling, base-lines, colors, rows and columns - (just about) everything...
High and Low limits too, with optional bar coloring

All this, and optional flashing too when bars surpass these limits.
Data
Multistat accepts Grafana table formatted data. Note - There is no support for time series formatted data.
As a minimum, Multistat requires table data with at least two fields per row - one, a label (string) and the other, a numeric value. These fields can be called anything. Multistat makes no assumptions regarding the names of the table data field it handles.
Each distinct label will be displayed as a bar - the length being determined by it's numerical value.
takes it's data from a table query - returning, at minimum, 2 fields (names can be anything)
A timestamp field can be useful too - this can be in any commonly understood format (Multistat uses the popular Moment.js java script library for manipulating time/date strings - see https://momentjs.com/docs/#/displaying/ for details).
A grouping field can be useful too, to organize large data sets into more meaningful sections. When grouping, the number of columns can be pre-configured, along with handy mechanisms for filtering and arranging the order each group is presented in.
Any additional fields are retained and presented in optional tool-tip balloons. Again, (just about) everything is configurable here...

Duplicate labels in table data
Each distinct label in the input data results in a distinct bar in Multistat. Ideally, table data should be created by queries that return distinct data sets - that is, sets in which each label is presented in a single row. When data sets are processed with multiple rows for a given label, Multistat needs to know which value to use (and hence, which values to ignore). A configurable aggregation parameter tells Multistat how to handle this. 'Last' (and 'First') select the last (or first) row in the data for any given label, throwing out all the others. The optional date/timestamp field helps too by pre-sorting the data table before selecting the aggregation function. The tool-tip then shows the set of fields for the selected data row, as expected.
Setting the aggregation parameter to 'Max' or 'Min' works in a similar way, selecting the row for each label with the corresponding value - and secondly using the last or latest value in the event that there is a tie in the value.
Setting the aggregation parameter to 'Mean' results in the arithmetic mean of all duplicate values to be used, as should be expected. A side effect of this though is that the fields presented in the tool-tip balloon in this case represent just one of the rows - actually the 'last' row, the value of which will not generally match the displayed 'mean' value for that label.
Data set size - a performance consideration
As mentioned before, ideally the data set should contain a single row for each distinct label. This offloads the maximum amount of filtering and aggregation etc., to the database which is generally much more efficient for these tasks. In the event that the database cannot pre-filter the data in this way, the aggregation setting can still generate the required display, but at the cost of increased CPU and network load. Generally, this is not significant - Multistat can easily handle queries with a few hundred labels, each with a hundred or more rows. Note though that huge data sets - data sets with multiple megabytes of data etc. - these will negatively impact performance. Particularly as refresh rates shorten. In extreme cases, this can even make the browser become unresponsive. Beware of enormous data sets.
Multistat has a wealth of configurable options. just about everything displayed can be adjusted and hidden using the extensive set of configuration options, described in detail below.
Features
Orientation - Horizontal or Vertical bars
Sorting (Dynamic, by Name, Value (or Update Time), ascending or descending)
Query result field name mapping - define which fields represent the labels and which represent values
Last Update Time display (Optional, if Update DateTime column included in query and column mapped). Useful to demonstrate the data source is actually updating
Optional display of values, selectable font size and color
Optional display of labels, selectable font size and color
Selectable Bar color (bar coloring is a subject in itself - see below for far more details regarding this)
Optional Left & Right value axes display (that is, upper & lower axes when in horizontal display mode)
Adjustable label margin size override
Min, Max and Baseline values (See below for discussion on baselines)
Optional High and Low value alarm limits and indicator lines
Optional setting color of bars exceeding High or Low alarm thresholds
Optional two-color alarm flashing, with settable flash rate
Note : With all these options, the author accepts no responsibility for
inducing nausea, epilepsy or generally violating the bounds of good taste)
Configuration details
The Grafana-standard Metrics tab allows the user to specify a query, to be issued each time the panel is refreshed.
This area is under continued active development. Currently, Multistat only supports Table data queries. Each row returned will be displayed as a bar, auto-sized to use the available space. The panel does not provide scroll bars, so any query returning more rows than can comfortably fit in the allotted panel area will be unreadable.
Note - getting appropriately formatted data can be challenging, especially while becoming familiar with all the options offered by Multistat. For this end - and for general purpose Grafana plugin testing - I've created a simple NodeJS data source called CSVServer, working in conjunction with the standard SimpleJSON datasource to import simple CSV files which can be easily edited to generate any kind of table or time series data sets. See here for details, including set up instructions : https://github.com/michaeldmoore/CSVServer
Table Queries
Multistat queries are expected to be something along the lines of ''Get the working pressure of all steam boilers in building 5'' or ''Get the temperature of the 10 hottest cities in the US'' etc. Anything that can be re-queried efficiently and returns a list of results containing - at minimum - a Label (e.g. Boiler ID or City Name) and a value (e.g. the pressure or temperature). Optionally, Multistat takes advantage of a DateTime field, if present, which can be displayed alongside the panel title as an indicator as to the last time the data was updated. More details on this below.
If no query is defined, or the data source is unavailable, Multistat displays a simple "No data" warning message.

Queries should return just one value per label
Multistat can only display a single bar for each label. Ideally, query results should be written to return a single value per label. When this is not possible, and the query returns multiple values per label, Multistat uses an aggregation operator to select one of these (first, last, mean, min or max). *one more - all - will eliminate the aggregator altogether, Be careful - This can create confusing displays as multiple values appear overlying the position of such bars. You have been warned. For efficiency though, it is much better to write a query that only returns the required data.
For this discussion, I created a test data set in a CSV file (demo.csv) distributed with the CSVServer add-on to SimpleJSON data source. I highly recommend installing this so you can follow along and see how the various configuration options work before worrying about live real-world data sets. The demo CSV file contains the following data:
time,sensor,area,quantity
2018-12-18 00:21:05.000,AAA,West,1.100
2018-12-18 00:21:04.000,AAA,West,1.000
2018-12-18 00:21:03.000,AAA,West,0.950
2018-12-18 00:21:02.000,AAA,West,0.900
2018-12-18 00:21:01.000,AAA,West,0.850
2018-12-18 00:21:00.000,AAA,West,0.800
2018-12-18 00:21:07.000,AAA,West,1.234
2018-12-18 00:21:07.000,BBB,East,0.662
2018-12-18 00:21:07.000,CCC,East,0.344
2018-12-18 00:21:07.000,EEE,West,0.357
2018-12-18 00:21:07.000,GGG,West,0.563
2018-12-18 00:21:07.000,HHH,West,0.234
2018-12-18 00:21:07.000,III,West,0.840
2018-12-18 00:21:07.000,JJJ,East,0.193
2018-12-18 00:21:07.000,KKK,West,0.262
2018-12-18 00:21:07.000,LLL,North,0.802
2018-12-18 00:21:07.000,MMM,East,0.211
2018-12-18 00:21:07.000,PPP,North,0.300
2018-12-18 00:21:07.000,QQQ,North,0.731
2018-12-18 00:21:07.000,RRR,North,1.101
2018-12-18 00:21:07.000,SSS,East,0.811
2018-12-18 00:21:07.000,WWW,East,0.213
2018-12-18 00:21:07.000,YYY,East,0.844
2018-12-18 00:21:07.000,ZZZ,North,0.928
Note, sensor AAA in this data set has multiple values, each a few hours apart. All the other sensors have a single row - this will allow the aggregation feature to be demonstrated later in this note. Each row in this data set includes a date/time, a label and a value, plus a region field (that will be useful in grouping). The field names can be anything; everything is defined in the configuration tabs. Additional fields, if any, will appear in the tool-tip pop-up display, if enabled.
As you can see, Multistat is configured using a number of option tabs. Let's examine each of these in sequence.
First, the data source and query is setup using the standard Metrics tab

Note the data set format is set to 'Table' (Multistat does not support time series data sets)
Note: The Query Inspector built into Grafana is a terrific resource for figuring out source data problems. Here's what we get from my demo query:
 etc.
etc.
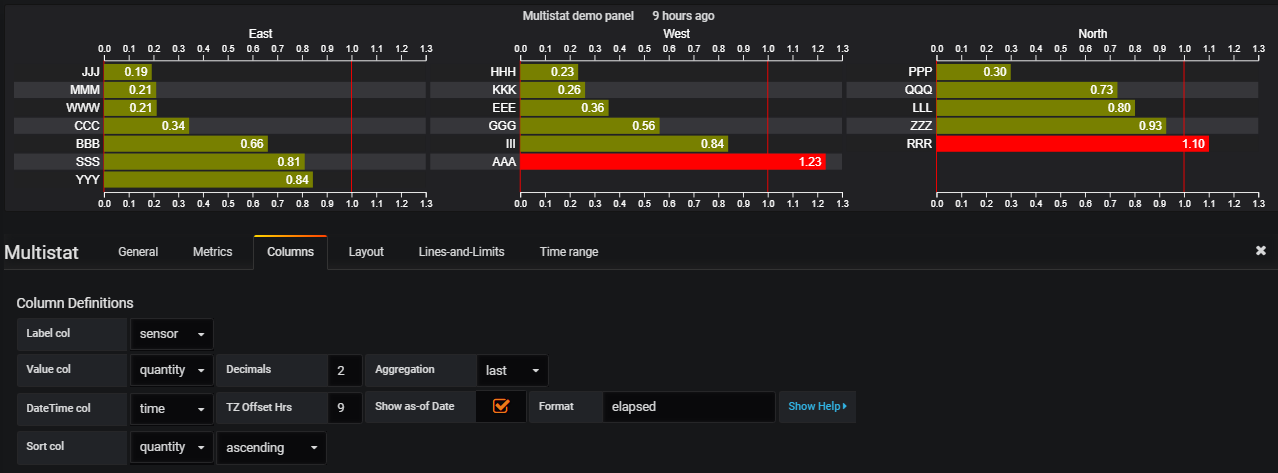
The data is mapped using the Columns configuration tab:

Here, you can see how the 4 key fields in the query result set get mapped to the Multistat fields. In this case, the label is associated with the query field 'sensor', Value as 'quantity', with 1 decimal place and no scaling (scale factor = 1). Note too that the default aggregation parameter of 'Last' is selected. This dataset contains multiple rows for some labels - this setting automatically selects the last (latest) value for each sensor.
Note too, that the bars are set to be sorted in ascending 'sensor' name.
The data is set to group on the 'area' field - this will create 3 sub-charts, for the East, North and West areas.
The DateTime col (optional) is mapped here to the 'time' field. When set, the TZ Offset Hrs setting can be used to offset the display value to account for time-zone differences between the data source and the client. (Note - this time offset features duplicates something similar built into recent versions of Grafana. This feature may be removed in future versions of Multistat)
The 'Show as-of Date' setting controls whether or not the last update time is to be displayed in the top right of the panel. Most users can ignore this setting. When it is set, the maximum datetime value in the query record set is displayed alongside the panel title. This can be useful in process monitoring applications to provide evidence that the data is being updated in a timely manner etc. The format field controls how this time is displayed (see documentation for moment.js for formatting details), or use the reserved keyword 'ELAPSED' to display as a natural language string, relative to the current time. Help is available, if needed.
The Layout tab

The Layouts tab defines the basic settings that control how the data is arranged on the panel. The Horizontal checkbox switches the bar orientation from vertical to horizontal. As the chart(s) rotate, the axis and labels rotate with them - hence the use of neutral terms for the axis as 'High' and 'Low' rather than 'Left', 'Right', 'Top' or 'Bottom'
Label Margin sets the area reserved for the labels can be set according to the length of the labels - or left blank, leaving the panel to calculate a reasonable value based on the actual data, orientation and chosen font size etc. Angle controls the rotation angle for the label text, which can help preserve screen real-estate - particularly when long labels are present. Note - it is quite difficult for the control to predetermine the ideal centre of rotation for these labels. Depending on the data, this can make the charts hard to understand. More work in future releases should improve this feature. Still, if it helps in any specific case, feel free to use it.
Low Side Margin and High Side Margin set the width of the two axis. Set to 0 to hide one or both of them.
High Axis Color and Low Axis Color set the colors for these axes, assuming they are visible
High Bar Color sets the regular color of bars who's values are above the baseline (normally 0, see the Lines-And-Limits tab). Low Bar Color does the same for bar descending below (or to the left) of the base line. Bar Padding controls the width of the gap between bars, as a percentage of the bar width
Odd Row Color and Even Row Color sets the colors of the alternating background stripes. These seem to work best when semi-transparent colors are chosen (switch the color picker to 'Custom' and slide the transparency control to the left)

The Grouping tab

Provided the Group Col (see the Columns Tab, above) is mapped to a field, this tab show settings for how the groups are to be displayed. (When Group Col is not defined, ALL the values appear in a single group)
The Columns Per Row setting controls how many sub-charts appear in each row. When the data contains more groups than are defined here, additional rows of sub-charts are added, wrapping to fill the available space. Note: If Group Col is set to something inappropriate, such as (say) the value or datetime field, Multistat can generate a ridiculous number of sub-charts - auto-scaled to fit in the available area, resulting in an unreadable mess. Don't panic - just choose a more meaningful grouping field, assuming your data has one.
The Group Name Filter field (this is an advanced feature most users can ignore. If in doubt, make sure this is blank. Especially if the chart appears to be empty!). This field should be a regular expression string which is used to filter out non-matching group names, when needed.
Using the demo sample data, for example (which contains values for areas East, West and North), we could select just the East and West groups by using a value of 'East|West' (Note the Pipe character '|' separating a sequence of matching strings. Regular expressions are amazingly powerful and can be much, much more complicated than this - but a simple set of pipe-delimited strings is usually enough in this application.
The Group Sort Order field is another regular expression string, this time used to define the order the groups are presented in (reading like a book from top left, wrapping to the bottom right). Matched group names are presented in order, followed by any remaining non-matched group names in the default (alphabetical) order.
Left blank with our sample data, the groups will be arranged in alphabetical order - that is, East->North->West. Setting this field to the regular expression 'West|North|East' overrides the alphabetical ordering, resulting in a more map-meaningful displays with the West group on the left and the East group on the right (apologies to users in the Southern Hemisphere who might have a different perspective...)
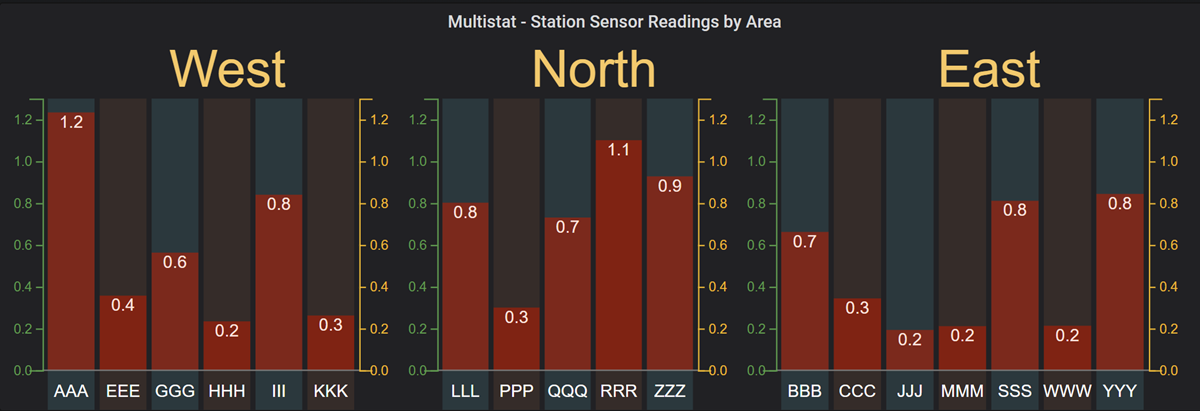 Notice how Multistat intelligently adjusts the height and width of the sub-charts to keep all bars the same width, regardless of the number of bars in each group. When more than one row of sub-charts is generated, Multistat inserts blank/dummy rows in groups needed to keep the groups aligned properly.
Notice how Multistat intelligently adjusts the height and width of the sub-charts to keep all bars the same width, regardless of the number of bars in each group. When more than one row of sub-charts is generated, Multistat inserts blank/dummy rows in groups needed to keep the groups aligned properly.

Show Group Labels controls whether or not each group is topped with it's name, along with the Font Size and Color settings.
The Options Tab

Show Values controls whether or not to display the values in text (the bar size always represents the value and may be enough for users without a readable text version). When checked, the Font Size and Color can also be defined. The Position setting controls where the value text will appear - either at the extreme (end) of the relevant bars, at the base of the bars or in a reserved area above (or to the right of) the chart. Choose what makes sense in your application.
 The three value positions, Bar Base, Bar End and Top
The three value positions, Bar Base, Bar End and Top
Show Group Labels and Show Labels - as before (Show Group Labels also appeared on the Grouping tab, for convenience).. Set Font Size and color etc. The Out Of Range label color override is an advanced feature for cases where a specific axis Max and/or Min setting is in place (see the Lines-And-Limits tab below) and a bar is outside one of these limits. This color overrides the standard label color for labels where this occurs. (This is useful, for example where a non-working sensor, for example, generates a wildly out of range value) Label Margin, Angle, Low Side Margin and High Side Margin - these too are duplicates of controls on the Layout tab, again, for convenience.
Tooltips enables the mouse over info balloons, listing all the fields corresponding to the identified bar. Date Format allows the setting formatting characters for the field identified as the datetime field (if any)
The Lines and Limits tab

Max Value and Min Value These overrides default auto-scaling axis extents, and if the Show Line checkbox is set, control the color of the resulting reference lines.
The BaseLine setting (default 0) differentiates between positive and negative values, each potentially having a different color. This can be useful when monitoring deviations from some non-zero set point. For example, Electrical generators (in North America, at least) operate at very close to 60Hz, with normally, only small deviations. Setting a baseline at 60.0 and a Max/Min to (say) 60.10 and 59.90 would make an easily understood display in such an application.
Values above the base line are generally draw using the High Bar color (see the Layout Tab). Values below in the Low Bar color.
High Limit and Low Limit, if set define additional 'warning' references. Corresponding reference lines and colors are set as before. In addition, the Color Bar option overrides the regular above or below base line bar colors for bars outside these warning levels. Optionally, these can be set to 'flash' - transitioning from one color to another at a controllable rate (period). The period is measured in mS, Values between 200mS and 400mS seem to work best.
As with all these settings, the user can display a reference line on the chart and set the colors to whatever makes sense in the application. In the frequency example above, there might be high and Low Limits set at (say) 60.05 and 95.95 respectively.
For example...

Putting it all together, the displays can make a truly unforgettable and un-ignorable, experience.


(In retrospect, setting the Rate parameter to 300 or 400 works just as well, without risk of inducing epilepsy...
Recolor Rules
(New feature added with version 1.3.0)
Any column of data can be designated as a 'recolor column'. Once set, an extensible array of recolor rules appears, each having a pattern, a match type and an override color.
In the sample below, the recolor column is set to 'room', which is also used in this example as the bar label column.

The pattern 'kitchen' is set for an exact match, so that the kitchen bar color is changed, in this case to yellow.
Multiple rules can de defined, evaluated in order until a match is found.
If none of the rules match the given recolor value, the bar colors are not overridden, and the colors based on the bar's numeric value are displayed.

In this case, the second rule 'room' with a subset match type sets all the bars containing the word 'room' blue.
The 'List' rule match type uses a comma separated list of names. In this case, the 'bed room' match applies over the more general 'room' rule as it appears higher up in the list of recoloring rules

A final option - 'Reg ex' uses the rule pattern as a regular expression, for those brave enough to work out the syntax (!)
Clickable tooltips & links
Version 1.4.0 introduces an upgraded per-bar tooltip system, with improved styling and clickable per-bar url links

Bar-links
New with this version, clickable URLs with bar-specific name/parameter substitutions - ideal for drill-downs or data look-ups etc.
These bar-links are automatically appended to the tool tips (see above). Both the display names and the generated URLs can include substitution tokens, matching the names of the columns, surrounded by '{' and '}' characters. These are replaced by the values of these data elements.
Any number of bar-links can be defined, using the Bar Links section of the panel editor

Multi-Column support
(New feature added with version 1.6.0)
Previously, Multistat was only able to display values for one numeric field at a time. In this version, the value column selector has been changed to support any number of fields, each appearing as a differently colored bar. Consider this simple table-formatted data set as an example:
Shop Region Food Beverages Other
Fred's Shop North 12000 3847 6363
Mary's Shop North 6583 1466 7463
Bob's Shop North 5343 9686 17632
Ted's Shop South 5342 5325 7653
Bill's Shop South 4252 2234 2426
Jill's Shop South 5000 1600 2000
This can now be displayed in a single Multistat panel like this:

Of course, all the other configuration features are still supported, such as bar orientation, grouping, threshold flashing etc. etc.
The value column configuration menu has been changed to support these added fields. Pressing the plus sign next to Values Cols adds a new (empty) row to the value fields table where the bar color for positive and negative bars can be defined. The select switch reflects whether or not this field is visible (The optional legend supports mouse clicks to dynamically set or reset this visibility too, mimicking the action on Grafana graph panel)

Label/Group renaming, plus date reformatting support
(New feature added with version 1.7.0)
Label field renaming
In previous versions of Multistat, the contents of the labels (and groups) were taken directly from the strings in the data received by the current query. In some cases, this results in unnecessarily long or confusing bar labels (and groups).
Using the data set above as a trivial example, suppose users which to simplify the display by removing redundant "'s shop" from each of the labels. The Columns configuration section has a new items for Label Renaming Rules. pressing the '+' button opens a new renaming rule definition where we can enter the text to be replaced and the replacement. in this case, the string "'s Shop" and the empty replacement.


Technically, the selection text is treated as a regular expression, with the 'ig' options, making it case insensitive.
Any number of rules can be defined, each operating sequentially, making this a very flexible way of pre-processing the data before display. Note, however, that every row of data is transformed by each and every renaming rule, so this does have the potential of slowing down the dashboard performance, especially when processing large data sets.
Group field renaming
A similar set of renaming rules is defined in the Grouping configuration setting, applying - obviously - to the grouping column, if any is defined.
These renaming rule sets are applied to the data set before sorting, grouping and filtering etc.
Date field reformatting
Multistat has provided some support for an optional date/time field. Time series data sets require date fields, while the table formatted data sets such as used by Multistats do not. When present, date/time fields are natively treated as numbers or strings - as defined in the data query. That is, unix timestamps will appear as very large numbers (seconds or milliseconds since 1970-01-01), others may appear in any number of string formats, such as "2019-04-21 22:00:00" etc. Multistat does it's best to try and automatically parse any identified data/time field - most significantly, to sort data so that the 'first' and 'last' aggregation settings can select the appropriate record for display. This behaviour has been standard in Multistat since the beginning. Optionally, Multistat could be set to add a formatted date/time label to the panel's title string.
In this version of Multistat, the optional date format field is used to parse and reformat the contents of such a date/time field in place, so these can be used in labels groups. This reformatting is done on the data received immediately before the earlier mentioned label and group renaming rules are applied. This has the potential of all sorts of data manipulation, pivot table-like.
For example, with a simple data set like this:
Date Region Sales
2019-01-01 Canada 134980
2019-01-01 Mexico 138300
2019-01-01 USA 231231
2019-02-01 Canada 222849
2019-02-01 Mexico 104779
2019-02-01 USA 342929
2019-03-01 Canada 273626
2019-03-01 Mexico 144882
2019-03-01 USA 348373
And setting the date time format string to qQ-MMM and selecting the Date column as the label field, with a 'sum' aggregation type, we can get this:

Conclusion
If you find this useful, and/or if you can think of additional features that you would find useful - make an entry on the project's GitHub/issues page
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Install on Grafana Cloud
Plugins can be installed directly from within your Grafana instance or automated using the Cloud API or Terraform.
Learn more about plugin installationMarketplace plugins
This is a paid plugin developed by a marketplace partner. To purchase an entitlement, sign in first, then fill out the contact form.
Get this plugin
This is a paid for plugin developed by a marketplace partner. To purchase entitlement please fill out the contact us form.
What to expect:
- Grafana Labs will reach out to discuss your needs
- Payment will be taken by Grafana Labs
- Once purchased the plugin will be available for you to install (cloud) or a signed version will be provided (on-premise)
Thank you! We will be in touch.
For more information, visit the docs on plugin installation.
Installing on a local Grafana:
For local instances, plugins are installed and updated via a simple CLI command. Plugins are not updated automatically, however you will be notified when updates are available right within your Grafana.
1. Install the Panel
Use the grafana-cli tool to install Multistat from the commandline:
grafana-cli plugins install The plugin will be installed into your grafana plugins directory; the default is /var/lib/grafana/plugins. More information on the cli tool.
Alternatively, you can manually download the .zip file for your architecture below and unpack it into your grafana plugins directory.
Alternatively, you can manually download the .zip file and unpack it into your grafana plugins directory.
2. Add the Panel to a Dashboard
Installed panels are available immediately in the Dashboards section in your Grafana main menu, and can be added like any other core panel in Grafana.
To see a list of installed panels, click the Plugins item in the main menu. Both core panels and installed panels will appear.
Change Log
All notable changes to this project will be documented in this file.
v1.6.0
Adding Multi-bar support
v1.6.1
Signed, as required by Grafana 7.x.x. No other changes
v1.7.0
Adding label and group reformatting rules, plus optional reformat-in-place for date/time field.