Why this matters
Observability works best as a progression. Each level builds on the previous, though teams sometimes need to work on multiple levels at once.
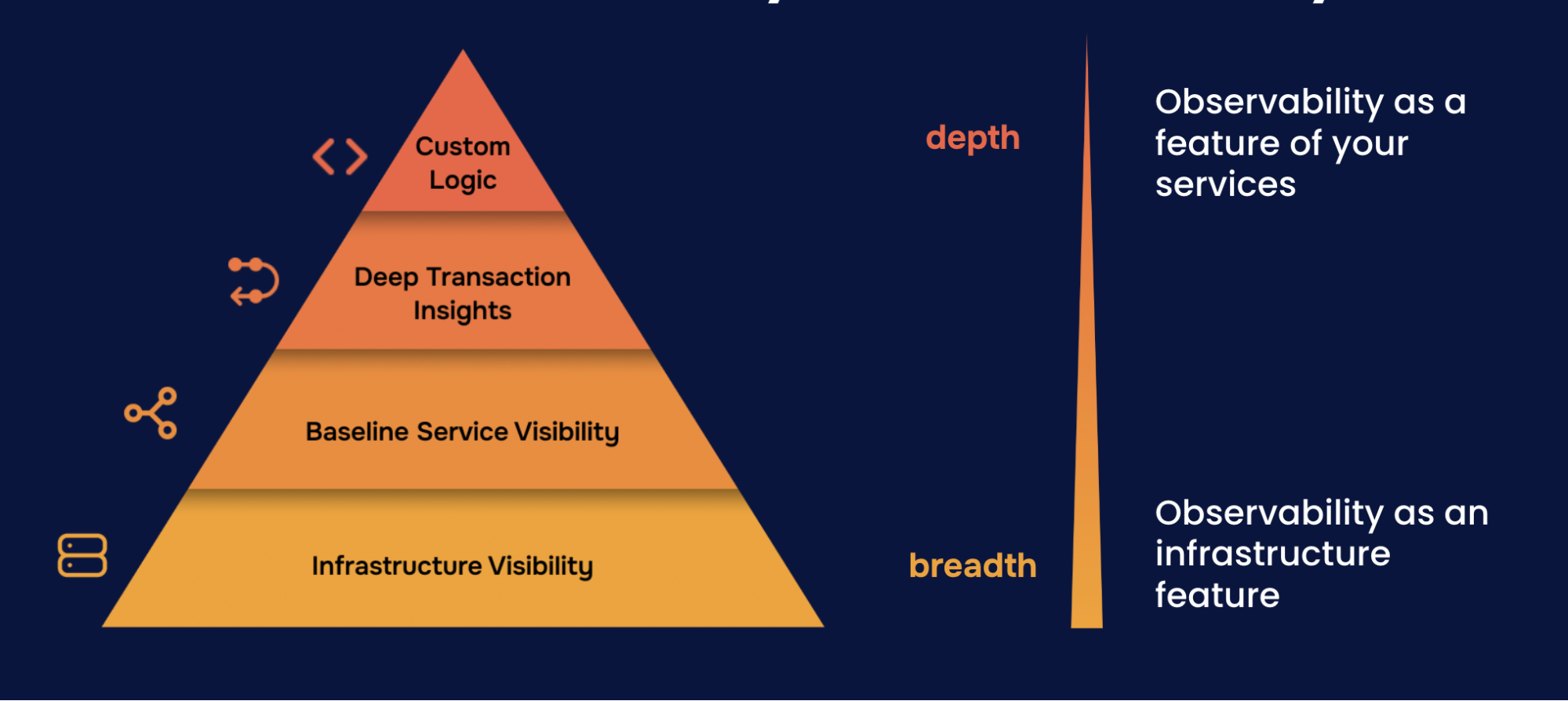
Each level builds on the previous
Each level provides context for the next.
Observability works best as a progression. Each level builds on the previous, though teams sometimes need to work on multiple levels at once.
Each level provides context for the next.