Running large tests
k6 can generate a lot of load from a single machine. With proper monitoring and script optimization, you might be able to run a rather large load test without needing distributed execution. This document explains how to launch such a test, and some of the aspects you should be aware of.
Maximizing the load a machine generates is a multi-faceted process, which includes:
- Changing operating system settings to increase the default network and user limits.
- Monitoring the load-generator machine to ensure adequate resource usage.
- Designing efficient tests, with attention to scripting, k6 options, and file uploads.
- Monitoring the test run to detect errors logged by k6, which could indicate limitations of the load generator machine or the system under test (SUT).
A single k6 process efficiently uses all CPU cores on a load generator machine. Depending on the available resources, and with the guidelines described in this document, a single instance of k6 can run 30,000-40,000 simultaneous users (VUs). In some cases, this number of VUs can generate up to 300,000 HTTP requests per second (RPS).
Unless you need more than 100,000-300,000 requests per second (6-12M requests per minute), a single instance of k6 is likely sufficient for your needs. Read on to learn about how to get the most load from a single machine.
OS fine-tuning
Modern operating systems are configured with a fairly low limit of the number of concurrent network connections an application can create. This is a safe default since most programs don’t need to open thousands of concurrent TCP connections like k6. However, if we want to use the full network capacity and achieve maximum performance, we need to change some of these default settings.
On a GNU/Linux machine, run the following commands as the root user:
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w net.ipv4.tcp_timestamps=1
ulimit -n 250000These commands enable reusing network connections, increase the limit of network connections, and range of local ports.
The sysctl commands apply immediately for the entire system, and will reset to their default values if you restart the network service or reboot the machine. The ulimit command applies only for the current shell session, and you’ll need to run it again for it to be set in another shell instance.
For detailed information about these settings, how to make them permanent, and instructions for macOS, check out our “Fine tuning OS” article.
Hardware considerations
As load increases, you need to pay attention to hardware constraints.
Network
Network throughput of the machine is an important consideration when running large tests. Many AWS EC2 machines come with connections of 1Gbit/s, which may limit the load k6 can generate.
When running the test, use a tool like iftop in the terminal to view the amount of network traffic generated in real time.
If the traffic is constant at 1Gbit/s, your test is probably limited by the network card. Consider upgrading to a different EC2 instance.
CPU
k6 is heavily multi-threaded, and will effectively utilize all available CPU cores.
The amount of CPU you need depends on your test script and associated files. Regardless of the test file, you can assume that large tests require a significant amount of CPU power. We recommend that you size the machine to have at least 20% idle cycles (up to 80% used by k6, 20% idle). If k6 uses 100% of the CPU to generate load, the test will experience throttling limits, and this may cause the result metrics to have a much larger response time than in reality.
Memory
k6 can use a lot of memory, though more efficiently than some other load testing tools. Memory consumption heavily depends on your test scenarios. To estimate the memory requirement of your test, run the test on your development machine with 100VUs and multiply the consumed memory by the target number of VUs.
Simple tests use ~1-5MB per VU. (1000VUs = 1-5GB). Tests that use file uploads, or load large JS modules, can consume tens of megabytes per VU. Note that each VU has a copy of all JS modules your test uses. To share memory between VUs, consider using SharedArray, or an external data store, such as Redis.
If you’re using swap space, consider disabling it. If the system runs out of physical memory, the process of swapping memory to much slower secondary storage will have erratic effects on performance and system stability. Which likely will invalidate any test results as the load generator had different performance in different parts of the test. Instead, plan ahead for the memory usage you expect your tests to achieve, and ensure that you have enough physical RAM for the usage to not exceed 90%.
Monitoring the load generator
The previous section described how hardware limits the load your machine can generate. Keeping this in mind, you should monitor resources while the test runs—especially when running tests for the first time.
The easiest way to monitor the load generator is to open multiple terminals on the machine: one to run k6, and others to monitor the CPU, memory, and network. We recommend the following tools:
If you prefer graphical applications, use the system monitoring tool from your OS (e.g. GNOME System Monitor or Plasma System Monitor), or standalone tools like SysMonTask.
Here’s a screenshot of 3 terminal sessions showing k6, iftop and htop.
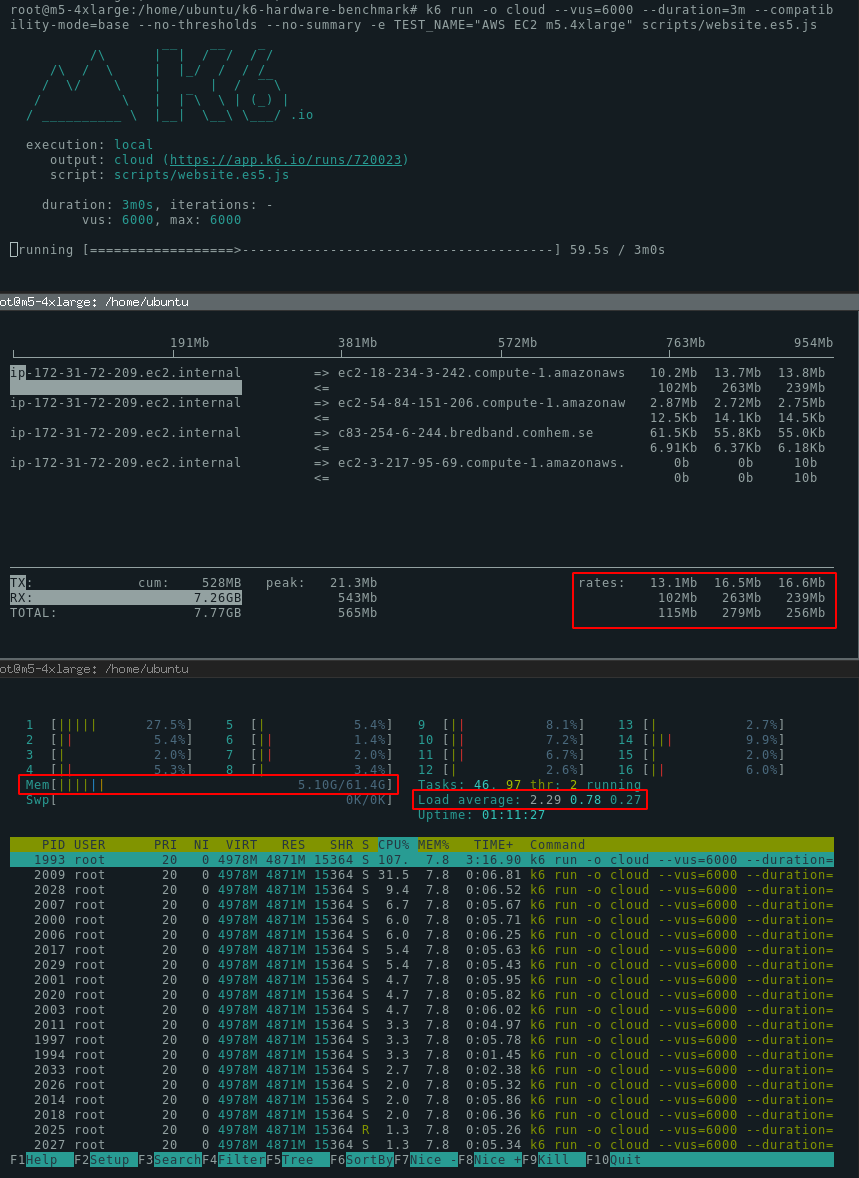
Monitoring guidelines
As the test runs, these are good indicators to monitor:
CPU utilization stays within 80%. If all CPU cores are 100% utilized during the test run, you might notice performance degradation in your test results.
Network utilization is at an acceptable level. Depending on your test, you might expect to fully saturate the network bandwidth, or this might be a signal that your test is bound by the available bandwidth. In other scenarios, you might want to minimize network usage to keep costs down.
Memory utilization doesn’t exceed 90%. If you’re close to exhausting available physical RAM, the system might start swapping memory to disk, which will affect performance and system stability (note that we recommend disabling swap space altogether). In extreme cases, running out of memory on Linux will cause the system to end the k6 process.
Error handling should be resilient
When running large stress tests, your script shouldn’t assume anything about the HTTP response. An oversight of some scripts is to test with only the happy path in mind.
For example, in k6 scripts, we often see something like this happy path check:
import { check } from 'k6';
import http from 'k6/http';
const res = http.get('https://test.k6.io');
const checkRes = check(res, {
'Homepage body size is 11026 bytes': (r) => r.body.length === 11026,
});Code like this runs fine when the SUT is not overloaded and returns proper responses. When the system starts to fail, this check won’t work as expected.
The issue is that the check assumes that the response always has a body.
But if the server is failing, r.body might not exist.
In such cases, the check itself won’t work as expected, and an error such as the following will be returned:
ERRO[0625] TypeError: Cannot read property 'length' of undefinedTo fix this issue, make your checks resilient to any response type.
The following change will handle the exception.
import { check } from 'k6';
import http from 'k6/http';
const res = http.get('https://test.k6.io');
const checkRes = check(res, {
'Homepage body size is 11026 bytes': (r) => r.body && r.body.length === 11026,
});Refer to subsequent sections for a list of common errors.
k6 options to reduce resource use
The following k6 settings can reduce the performance costs of running large tests.
Save memory with discardResponseBodies
By default, k6 loads the response body of the request into memory. This causes much higher memory consumption and is often unnecessary.
To instruct k6 to not process all response bodies, set discardResponseBodies in the options object like this:
export const options = {
discardResponseBodies: true,
};If you need the response body for some requests, override the option with Params.responseType.
When streaming, use --no-thresholds and --no-summary
If you’re running a local test and streaming results to the cloud (k6 cloud run script.js --local-execution), you might want to disable the terminal summary and local threshold calculation, because the cloud service will display the summary and calculate the thresholds.
Without these options, the operations will be duplicated by both the local machine and the cloud servers. This will save some memory and CPU cycles.
Here are all the mentioned flags, all in one:
k6 cloud run scripts/website.js \
--local-execution \
--vus=20000 \
--duration=10m \
--no-thresholds \
--no-summaryScript optimizations
To squeeze more performance out of the hardware, consider optimizing the code of the test script itself. Some of these optimizations involve limiting how you use certain k6 features. Other optimizations are general to all JavaScript programming.
Limit resource-intensive k6 operations
Some features of the k6 API entail more computation to execute. To maximize load generation, you might need to limit how your script uses the following.
- Checks and groups
- k6 records the result of every individual check and group separately. If you are using many checks and groups, you may consider removing them to boost performance.
- Custom metrics
- Similar to checks, values for custom metrics (Trend, Counter, Gauge and Rate) are recorded separately. Consider minimizing the usage of custom metrics.
- Thresholds with abortOnFail
- If you have configured abortOnFail thresholds, k6 needs to evaluate the result constantly to verify that the threshold wasn’t crossed. Consider removing this setting.
- URL grouping
- k6 v0.41.0 introduced a change to support time-series metrics. A side effect of this is that every unique URL creates a new time-series object, which may consume more RAM than expected.
- To solve this, use the URL grouping feature.
JavaScript optimizations
Finally, if the preceding suggestions are insufficient, you might be able to do some general JavaScript optimizations:
- Avoid deeply nested
forloops. - Avoid references to large objects in memory as much as possible.
- Keep external JS dependencies to a minimum.
- Perform tree shaking of the k6 script if you have a build pipeline, and so on.
Refer to this article about garbage collection in the V8 runtime. While the JavaScript VM that k6 uses is very different and runs on Go, the general principles apply. Note that memory leaks are still possible in k6 scripts, and, if not fixed, they might exhaust RAM much more quickly.
File upload considerations
File uploads can affect both resource usage and cloud costs.
- Network throughput
- The network throughput of the load generator machine and of the SUT are likely bottlenecks for file uploads.
- Memory
- k6 needs a significant amount of memory when uploading files. Every VU is independent and has its own memory, and files will be copied in all VUs that upload them. You can follow issue #1931 that aims to improve this situation.
- Data transfer costs
- k6 can upload a large amount of data in a very short period of time. Make sure you understand the data transfer costs before commencing a large scale test.
- Outbound Data Transfer is expensive in AWS EC2. The price ranges between $0.08 to $0.20 per GB depending on the region. If you use the cheapest region, the cost is about $0.08 per GB. Uploading 1TB, therefore, costs about $80. A long-running test can cost several hundreds of dollars in data transfer alone.
- If your infrastructure is already hosted on AWS, consider running your load generator machine within the same AWS region and availability zone. In some cases, this traffic will be much cheaper or even free. For additional data cost-saving tips, check this article on how to reduce data transfer costs on AWS. Our examples are made with AWS in mind. However, the same suggestions also apply to other cloud providers.
- Virtual server costs
- The AWS EC2 instances are relatively cheap. Even the largest instance we have used in this benchmark (m5.24xlarge) costs only $4.6 per hour.
- Make sure you turn off the load generator servers once you are done with your testing. A forgotten EC2 server might cost thousands of dollars per month. Tip: it’s often possible to launch “spot instances” of the same hardware for 10-20% of the cost.
Common errors
If you run into errors during the execution, it helps to know whether they were caused by the load generator or by the failing SUT.
read: connection reset by peer
This is caused by the target system resetting the TCP connection. It happens when the Load Balancer or the server itself isn’t able to handle the traffic.
WARN[0013] Request Failed error="Get http://test.k6.io: read tcp 172.31.72.209:35288->63.32.205.136:80: read: connection reset by peer"context deadline exceeded
This happens when k6 can send a request, but the target system doesn’t respond in time. The default timeout in k6 is 60 seconds. If your system doesn’t produce the response in this time frame, this error will appear.
WARN[0064] Request Failed error="Get http://test.k6.io: context deadline exceeded"dial tcp 52.18.24.222:80: i/o timeout
This error is similar to context deadline exceeded, but in this case, k6 wasn’t even able to make an HTTP request. The target system can’t establish a TCP connection.
WARN[0057] Request Failed error="Get http://test.k6.io/: dial tcp 52.18.24.222:80: i/o timeout"socket: too many open files
This error means that the load generator can’t open TCP sockets because it reached the limit of open file descriptors. Make sure that your limit is set sufficiently high. Refer to the “Fine tuning OS” article.
WARN[0034] Request Failed error="Get http://test.k6.io/: dial tcp 99.81.83.131:80: socket: too many open files"Note
Decide what level of errors is acceptable. At large scale, some errors are always present. If you make 50M requests with 100 failures, this is generally a good result (0.00002% errors).
Benchmarking k6
We’ve executed a few large tests on different EC2 machines to see how much load k6 can generate. Our general observation is that k6 scales proportionally to the hardware. A machine with 2x more resources can generate roughly 2x more traffic. The limit to this scalability is the number of open connections. A single Linux machine can open up to 65,535 sockets per IP address (refer to RFC 6056 for details). This means that a maximum of 65k requests can be sent simultaneously on a single machine. This is a theoretical limit that will depend on the configured ephemeral port range, whether HTTP/2 is in use, which uses request multiplexing and can achieve higher throughput, and other factors.
Primarily, though, the RPS limit depends on the response time of the SUT. If responses are delivered in 100ms, the theoretical RPS limit is 650,000 for HTTP/1 requests to a single remote address.
We maintain a repository with some scripts used to benchmark k6 and create reports. These tests are run for every new k6 version, and you can see the results in the results/ directory.
Distributed execution
In load testing, distributed execution happens when a load is distributed across multiple machines.
Users often look for the distributed execution mode to run large-scale tests. Although a single k6 instance can generate enormous load, distributed execution is necessary to:
- Simulate load from multiple locations simultaneously.
- Scale the load of your test beyond what a single machine can handle.
In k6, you can split the load of a test across multiple k6 instances using the
execution-segment option. For example:
## split the load of my-script.js across two machines
k6 run --execution-segment "0:1/2" --execution-segment-sequence "0,1/2,1" my-script.js
k6 run --execution-segment "1/2:1" --execution-segment-sequence "0,1/2,1" my-script.js## split the load of my-script.js across three machines
k6 run --execution-segment "0:1/3" --execution-segment-sequence "0,1/3,2/3,1" my-script.js
k6 run --execution-segment "1/3:2/3" --execution-segment-sequence "0,1/3,2/3,1" my-script.js
k6 run --execution-segment "2/3:1" --execution-segment-sequence "0,1/3,2/3,1" my-script.js## split the load of my-script.js across four machines
k6 run --execution-segment "0:1/4" --execution-segment-sequence "0,1/4,2/4,3/4,1" my-script.js
k6 run --execution-segment "1/4:2/4" --execution-segment-sequence "0,1/4,2/4,3/4,1" my-script.js
k6 run --execution-segment "2/4:3/4" --execution-segment-sequence "0,1/4,2/4,3/4,1" my-script.js
k6 run --execution-segment "3/4:1" --execution-segment-sequence "0,1/4,2/4,3/4,1" my-script.jsHowever, at this moment, the distributed execution mode of k6 is not entirely functional. The current limitations are:
- k6 does not provide the functionality of a “primary” instance to coordinate the distributed execution of the test. Alternatively, you can use the
k6 REST API and
--pausedto synchronize the multiple k6 instances’ execution. - Each k6 instance evaluates
Thresholds independently - excluding the results of the other k6 instances. If you want to disable the threshold execution, use
--no-thresholds. - k6 reports the metrics individually for each instance. Depending on how you store the load test results, you’ll have to aggregate some metrics to calculate them correctly.
With the limitations mentioned above, we built a Kubernetes operator to distribute the load of a k6 test across a Kubernetes cluster. For further instructions, check out the tutorial for running distributed k6 tests on Kubernetes.
The k6 goal is to support a native open-source solution for distributed execution. If you want to follow the progress, subscribe to the distributed execution issue on GitHub.
Large-scale tests in the cloud
Grafana Cloud k6, our commercial offering, provides an instant solution for running large-scale tests, among other benefits.
If you aren’t sure whether OSS or Cloud is a better fit for your project, we recommend reading this white paper to learn more about the risks and features to consider when building a scalable solution.