Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Using Google Stackdriver in Grafana
Available as a beta feature in Grafana v5.3.x and v5.4.x. Officially released in Grafana v6.0.0
Grafana ships with built-in support for Google Stackdriver. Just add it as a data source and you are ready to build dashboards for your Stackdriver metrics.
Adding the data source
- Open the side menu by clicking the Grafana icon in the top header.
- In the side menu under the
Dashboardslink you should find a link namedData Sources. - Click the
+ Add data sourcebutton in the top header. - Select
Stackdriverfrom the Type dropdown. - Upload or paste in the Service Account Key file. See below for steps on how to create a Service Account Key file.
NOTE: If you’re not seeing the
Data Sourceslink in your side menu it means that your current user does not have theAdminrole for the current organization.
Authentication
There are two ways to authenticate the Stackdriver plugin - either by uploading a Google JWT file, or by automatically retrieving credentials from Google metadata server. The latter option is only available when running Grafana on GCE virtual machine.
Using a Google Service Account Key File
To authenticate with the Stackdriver API, you need to create a Google Cloud Platform (GCP) Service Account for the Project you want to show data for. A Grafana data source integrates with one GCP Project. If you want to visualize data from multiple GCP Projects then you need to create one data source per GCP Project.
Enable APIs
The following APIs need to be enabled first:
Click on the links above and click the Enable button:

Create a GCP Service Account for a Project
Navigate to the APIs and Services Credentials page.
Click on the
Create credentialsdropdown/button and choose theService account keyoption.
Create service account button On the
Create service account keypage, choose key typeJSON. Then in theService Accountdropdown, choose theNew service accountoption:
Create service account key Some new fields will appear. Fill in a name for the service account in the
Service account namefield and then choose theMonitoring Viewerrole from theRoledropdown:
Choose role Click the Create button. A JSON key file will be created and downloaded to your computer. Store this file in a secure place as it allows access to your Stackdriver data.
Upload it to Grafana on the data source Configuration page. You can either upload the file or paste in the contents of the file.

Upload service key file to Grafana The file contents will be encrypted and saved in the Grafana database. Don’t forget to save after uploading the file!

Service key file is uploaded to Grafana





Using GCE Default Service Account
If Grafana is running on a Google Compute Engine (GCE) virtual machine, it is possible for Grafana to automatically retrieve default credentials from the metadata server. This has the advantage of not needing to generate a private key file for the service account and also not having to upload the file to Grafana. However for this to work, there are a few preconditions that need to be met.
- First of all, you need to create a Service Account that can be used by the GCE virtual machine. See detailed instructions on how to do that here.
- Make sure the GCE virtual machine instance is being run as the service account that you just created. See instructions here.
- Allow access to the
Stackdriver Monitoring APIscope. See instructions here.
Read more about creating and enabling service accounts for GCE VM instances here.
Metric Query Editor
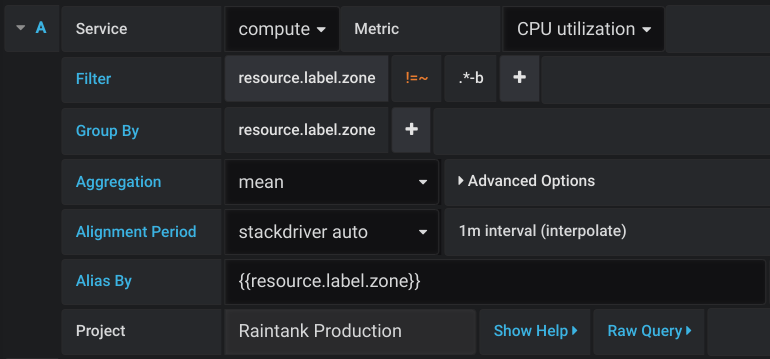
The Stackdriver query editor allows you to select metrics, group/aggregate by labels and by time, and use filters to specify which time series you want in the results.
Begin by choosing a Service and then a metric from the Metric dropdown. Use the plus and minus icons in the filter and group by sections to add/remove filters or group by clauses.
Stackdriver metrics can be of different kinds (GAUGE, DELTA, CUMULATIVE) and these kinds have support for different aggregation options (reducers and aligners). The Grafana query editor shows the list of available aggregation methods for a selected metric and sets a default reducer and aligner when you select the metric. Units for the Y-axis are also automatically selected by the query editor.
Filter
To add a filter, click the plus icon and choose a field to filter by and enter a filter value e.g. instance_name = grafana-1. You can remove the filter by clicking on the filter name and select --remove filter--.
Simple wildcards
When the operator is set to = or != it is possible to add wildcards to the filter value field. E.g us-* will capture all values that starts with “us-” and *central-a will capture all values that ends with “central-a”. *-central-* captures all values that has the substring of -central-. Simple wildcards are less expensive than regular expressions.
Regular expressions
When the operator is set to =~ or !=~ it is possible to add regular expressions to the filter value field. E.g us-central[1-3]-[af] would match all values that starts with “us-central”, is followed by a number in the range of 1 to 3, a dash and then either an “a” or an “f”. Leading and trailing slashes are not needed when creating regular expressions.
Aggregation
The aggregation field lets you combine time series based on common statistics. Read more about this option here.
The Aligner field allows you to align multiple time series after the same group by time interval. Read more about how it works here.
Alignment Period/Group by Time
The Alignment Period groups a metric by time if an aggregation is chosen. The default is to use the GCP Stackdriver default groupings (which allows you to compare graphs in Grafana with graphs in the Stackdriver UI).
The option is called Stackdriver auto and the defaults are:
- 1m for time ranges < 23 hours
- 5m for time ranges >= 23 hours and < 6 days
- 1h for time ranges >= 6 days
The other automatic option is Grafana auto. This will automatically set the group by time depending on the time range chosen and the width of the graph panel. Read more about the details here.
It is also possible to choose fixed time intervals to group by, like 1h or 1d.
Group By
Group by resource or metric labels to reduce the number of time series and to aggregate the results by a group by. E.g. Group by instance_name to see an aggregated metric for a Compute instance.
Metadata labels
Resource metadata labels contains information to uniquely identify a resource in Google cloud. Metadata labels are only returned in the time series response if they’re part of the Group By segment in the time series request. There’s no API for retrieving metadata labels, so it’s not possible to populate the group by dropdown with the metadata labels that are available for the selected service and metric. However, the Group By field dropdown comes with a pre-defined list of common system labels.
User labels cannot be pre-defined, but it’s possible to enter them manually in the Group By field. If a metadata label, user label or system label is included in the Group By segment, then you can create filters based on it and expand its value on the Alias field.
Alias Patterns
The Alias By field allows you to control the format of the legend keys. The default is to show the metric name and labels. This can be long and hard to read. Using the following patterns in the alias field, you can format the legend key the way you want it.
Metric Type Patterns
Label Patterns
In the Group By dropdown, you can see a list of metric and resource labels for a metric. These can be included in the legend key using alias patterns.
Example Alias By: {{metric.type}} - {{metric.labels.instance_name}}
Example Result: compute.googleapis.com/instance/cpu/usage_time - server1-prod
It is also possible to resolve the name of the Monitored Resource Type.
Example Alias By: {{resource.type}} - {{metric.type}}
Example Result: gce_instance - compute.googleapis.com/instance/cpu/usage_time
Templating
Instead of hard-coding things like server, application and sensor name in you metric queries you can use variables in their place. Variables are shown as dropdown select boxes at the top of the dashboard. These dropdowns makes it easy to change the data being displayed in your dashboard.
Check out the Templating documentation for an introduction to the templating feature and the different types of template variables.
Query Variable
Variable of the type Query allows you to query Stackdriver for various types of data. The Stackdriver data source plugin provides the following Query Types.
Using variables in queries
There are two syntaxes:
$<varname>Example:metric.label.$metric_label[[varname]]Example:metric.label.[[metric_label]]
Why two ways? The first syntax is easier to read and write but does not allow you to use a variable in the middle of a word. When the Multi-value or Include all value options are enabled, Grafana converts the labels from plain text to a regex compatible string, which means you have to use =~ instead of =.
Annotations
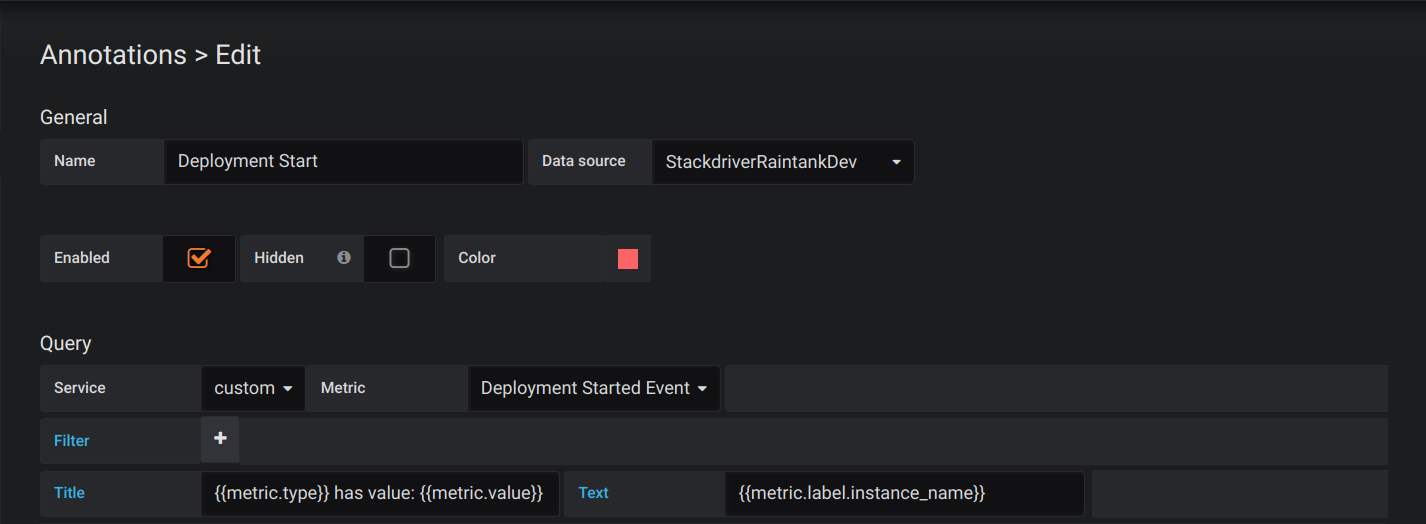
Annotations allows you to overlay rich event information on top of graphs. You add annotation queries via the Dashboard menu / Annotations view. Annotation rendering is expensive so it is important to limit the number of rows returned. There is no support for showing Stackdriver annotations and events yet but it works well with custom metrics in Stackdriver.
With the query editor for annotations, you can select a metric and filters. The Title and Text fields support templating and can use data returned from the query. For example, the Title field could have the following text:
{{metric.type}} has value: {{metric.value}}
Example Result: monitoring.googleapis.com/uptime_check/http_status has this value: 502
Patterns for the Annotation Query Editor
Configure the data source with provisioning
It’s now possible to configure data sources using config files with Grafana’s provisioning system. You can read more about how it works and all the settings you can set for data sources on the provisioning docs page
Here is a provisioning example using the JWT (Service Account key file) authentication type.
apiVersion: 1
datasources:
- name: Stackdriver
type: stackdriver
access: proxy
jsonData:
tokenUri: https://oauth2.googleapis.com/token
clientEmail: stackdriver@myproject.iam.gserviceaccount.com
authenticationType: jwt
defaultProject: my-project-name
secureJsonData:
privateKey: |
-----BEGIN PRIVATE KEY-----
POSEvQIBADANBgkqhkiG9w0BAQEFAASCBKcwggSjAgEAAoIBAQCb1u1Srw8ICYHS
...
yA+23427282348234=
-----END PRIVATE KEY-----Here is a provisioning example using GCE Default Service Account authentication.
apiVersion: 1
datasources:
- name: Stackdriver
type: stackdriver
access: proxy
jsonData:
authenticationType: gce

