Preconfigured dashboards and alerts
Cloud Provider Observability provides the following preconfigured dashboards and alerts for you to install in your Grafana Cloud instance. These dashboards are embedded in and accessible in the AWS Observability section of Cloud Provider Observability in Grafana Cloud.
Preconfigured dashboards
Preconfigured dashboards are out-of-the-box visualizations available in Grafana Cloud for popular Amazon services.
Cloud Provider Observability provides preconfigured dashboards for the following AWS services. Click the links to view details on the default metrics pulled from Amazon CloudWatch metrics.
Compute Services
Amazon Elastic Compute Cloud metrics: AWS/EC2
For more information on the metrics included and how to optimize your resources using them refer to AWS EC2 dashboard.
Amazon Elastic Container Service metrics: AWS/ECS
AWS Lambda metrics: AWS/Lambda
Storage Services
Database Services
- Amazon DynamoDB metrics: AWS/DynamoDB
- Amazon ElastiCache metrics: AWS/ElastiCache
- Amazon Relational Database Service metrics: AWS/RDS
Networking & Content Delivery
- Amazon API Gateway metrics: AWS/ApiGateway
- Amazon CloudFront metrics: AWS/CloudFront
- Amazon Elastic Load Balancing Application Load Balancer metrics: AWS/ApplicationELB
- Amazon Elastic Load Balancing Network Load Balancer metrics: AWS/NetworkELB
- Amazon Network Address Translation service metrics: AWS/NATGateway
- Amazon Route 53 metrics: AWS/Route53
- Amazon Route 53 Resolver metrics: AWS/Route53Resolver
- AWS Virtual Private Network metrics: AWS/VPN
Application Integration
Analytics & Streaming
- Amazon Managed Streaming for Apache Kafka metrics: AWS/Kafka
AI/ML Services
- Amazon Bedrock AgentCore metrics: AWS/Bedrock/Agents
Management & Governance
- AWS Billing metrics: AWS/Billing
Note
The preconfigured dashboard for AWS ELB Classic Load Balancer metrics was deprecated.
Preconfigured alerts
When you configure CloudWatch metrics, the following prebuilt alerts are available.
AWS Bedrock AgentCore
- AwsBedrockAgentCoreHighErrorRate: Fires if the specified agent has a high error rate.
- AwsBedrockAgentCoreHighLatency: Fires if the specified agent has high latency.
- AwsBedrockAgentCoreHighThrottleRate: Fires if the specified agent has a high throttle rate.
- AwsBedrockAgentCoreHighUserErrorsRate: Fires if the specified agent a high user errors rate.
AWS DynamoDB
- AwsDynamoDBConditionalCheckFailedRequests: Fires if there is a high number of conditional check failed requests on the table that could indicate issues with the application logic or data inconsistency in DynamoDB.
- AwsDynamoDBHighNumberOfThrottledRequests: Fires if there is a high number of throttle requests, meaning the specified table is receiving more traffic than what it can handle based on the provisioned read and write capacity. This issue can lead to slower performance and failures in your application. You need to increase provisioned capacity if necessary or switch to On-Demand mode.
- AwsDynamoDBHighReadCapacityUtilization: Fires if the DynamoDB account read quota utilization is high, meaning the account-level provisioned read capacity limit is being approached in the specified region. This affects ALL provisioned DynamoDB tables in that region and prevents further table provisioning/scaling. You need to check Service Quotas for DynamoDB Read Capacity in the specified region.
- AwsDynamoDBHighSystemErrors: Fires if there are high system errors, meaning there were internal issues with the specified table while executing the specified operation.
- AwsDynamoDBHighWriteCapacityUtilization: Fires if the DynamoDB account write quote utilization is high, meaning the account-level provisioned write capacity limit is being approached in the specified region. This affects ALL provisioned DynamoDB tables in that region and prevents further table provisioning/scaling. You need to check Service Quotas for DynamoDB Write Capacity in the specified region.
AWS EBS
- AwsEBSHighVolumeUtilization: Fires if there EBS volume utilization is too high. You need to increase IOPS or resize the EBS volume for better performance.
- AwsEBSHighVolumeQueueLength: Fires if you need to investigate whether the workload exceeds the provisioned IOPS or if there are inefficiencies in the application. You need to resize or upgrade the specified volumes to handle the queue.
- AwsEBSLowBurstBalance: Fires if EBS volume burst balance is low. You need to upgrade the EBS volume to a provisioned IOPS volume for consistent performance.
- AwsEBSLowIdleTime: Fires if there is very low idle time. You need to investigate processes causing high disk usage on the volume.
AWS EC2
- AwsEC2HighCpuUtilization: Fires if CPU utilization is too high for your EC2 instance indicating it is under heavy load and may become unresponsive.
- AwsEC2StatusCheckFailed: Fires if the EC2 instance status check fails. You need to view the AWS EC2 health checks and investigate underlying issues for the specified instance.
AWS ElastiCache
- AwsElastiCacheHasEvictions: Fires if evictions are detected for the specified cluster which could have an impact on memory.
- AwsElastiCacheHighCpuUtilization: Fires if CPU utilization is too high for the specified cluster indicating it is under heavy load and may become unresponsive.
- AwsElatiCacheHighReplicationLag: Fires if the specified cluster has high replication lag which indicates it may become stale.
- AwsElastiCacheHighSwapUsage: Fires if the specified cluster has high swap usage that might lead to insufficient memory.
AWS Kafka
- AwsKafkaActiveControllerCount: Fires if the cluster does not have exactly one active controller, meaning the specified clusters have a controller issue.
- AwsKafkaHighRootDiskUsed: Fires if root disk used percentage is too high, meaning the specified broker’s root disk is almost at capacity and needs to have free space increased.
- AwsKafkaHighSystemCpu: Fires if system CPU is too high, meaning the specified cluster is under heavy load and may become unresponsive.
- AwsKafkaOfflinePartitions: Fires if offline partitions are detected in a specified cluster.
- AwsKafkaPatitionUnderReplicated: Fires if under replicated partitions are detected in the specified cluster.
AWS Lambda
- AwsLambdaInvocationFailures: Fires if Lambda invocation failures are detected in the specified function. This issue indicates errors in function execution that may affect application functionality.
- AwsLambdaThrottlingEvents: Fires if Lambda function throttling is detected in the specified function due to concurrency limits. This issue may cause request failures and degraded performance.
AWS RDS
- AwsRDSDiskIOPSBottleneck: Fires if there is a disk IOPS bottleneck detected. You need to upgrade the specified instances to Provisioned IOPS storage (gp3/io1) or investigate inefficient queries.
- AwsRDSHighCpuLoad: Fires if sustained high CPU load is detected on your RDS instance. You need to scale up the specified instance, optimize queries, or investigate long-running queries.
- AwsRDSHighCpuSpikes: Fires if unexpected CPU spikes are detected on your RDS instance that may be causing latency issues or throttling.
- AwsRDSReadReplicaLag: Fires if RDS replicas are too slow.
AWS Route 53
- AwsRoute53HealthCheckUnhealthy: Fires if the specified health check is not healthy.
- AwsRoute53HealthCheckFailed: Fires if the specified health check failed.
- AwsRoute53HSlowConnectionTime: Fires if the specified health check has a slow connection time.
- AwsRoute53SlowTimeToFirstByte: Fires if the specified health check has a slow time to first byte.
Install AWS preconfigured dashboards and alerts
To install and view preconfigured dashboards and alerts:
- After you configure metrics, click the Configuration tab.
- Scroll down to the Dashboards and Alerts Installation section and click Install dashboards and alerts.
- Click the Services tab.
- Use the Service or Source filters to help you find the source or service you want to see.
- Optionally, click the Services with firing alerts checkbox to limit the services displayed to only those with firing alerts.
- Locate the specific service in the list, and click the name of the service in the Service column of the table to open the preconfigured dashboard for that service. If a Service’s name is not a link it means there is not a preconfigured dashboard for that service. To add a link to the Service’s name for a dashboard, refer to Dashboards and views settings.
- Optionally, click the Configure button to add a dashboard to the Service name.
- Optionally, click the Explore button to view links for custom dashboards, drilldown metrics, or to explore metrics. Refer to Dashboards and views settings for more information on adding custom dashboards.
Refine dashboard data
You can use the following filters on dashboards to refine your data:
- Data source
- Job
- Resource group
- Subscription name
- Resource name
Additionally, use the time range selector to change time period of your data.
View predictions
For the preconfigured dashboards that include drilldown information for specific instances, Cloud Provider Observability includes machine learning predictions. Predictions can help you ensure resources are available during spikes in usage, as well as help you decrease the amount of unused resources due to over provisioning. To use prediction tools, first enable LLM features for your Grafana instance.
You can view the prediction model for various metrics by clicking the Predict button in the top right corner of the panel.
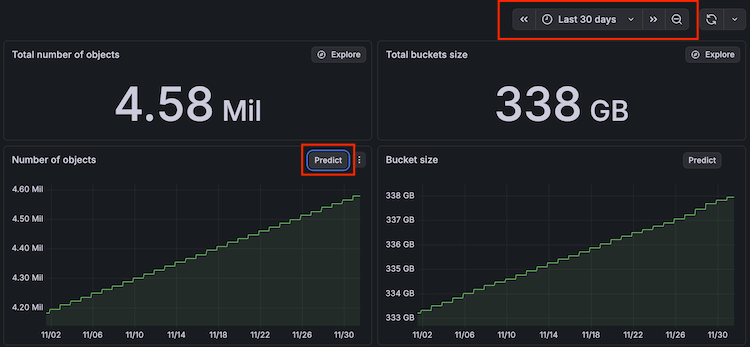
Use the time range filter to adjust the time range to show more advanced predictions. The time range you select must be at least two hours to use the prediction tool.
For more information on the terminology included and how machine learning works in the prediction graph, refer to the Query Metrics page in the AI and machine learning documentation.
Use the Knowledge graph with AWS services
Cloud Provider Observability integrates with the Knowledge graph so you can understand relationships between cloud resources, such as AWS RDS, S3, and EC2 instances, and application services. You can move from identifying a problem on a cloud resource to investigating root cause using RCA workbench, view connections in the Entity graph, and explore connected entities without leaving Cloud Provider.
Note
To access root cause analysis tools from Cloud Provider Observability, activate the Knowledge graph on your stack.
Access root cause analysis from service overviews
From overview pages for AWS RDS, S3, or EC2 services, you can open RCA workbench or see entity health and connected entities for a specific resource.
To access root cause analysis from a service overview page:
Hover over or click the Insights rings icon beside the instance Account ID.

Insights dialog box revealed when hovering over Insights rings The dialog box displays either This entity looks healthy or the current health state, and under Direct connections the number of connected entities (for example, 1 Database).
Click + Workbench to add the resource to RCA workbench and start an investigation.
Optionally click Analyze to run analysis using Grafana Assistant for that entity.

Access root cause analysis from an instance
When you are on the instance page for a specific cloud resource (for example, an AWS RDS instance), you can open RCA workbench or see entity health and connected entities for a specific resource.
To access root cause analysis from an instance page:
At the top of the page next to the time range selector, click Insights (a badge may show the number of insights).
In the Insights dropdown, review the entity type (for example, RDSInstance) and any listed alerts or insights.

Insights dialog box revealed when clicking the Insights dropdown Click Open in RCA Workbench to open RCA workbench with this resource already loaded.
Optionally click Analyze run analysis using Grafana Assistant for that entity.
You can then use RCA workbench Timeline, graph, and mind map views to correlate events and dependencies.

Explore connected entities
To see which services or other entities are connected to a cloud resource (for example, which application uses an RDS instance):
- From an AWS service overview in Cloud Provider, hover over the Insights rings next to an instance.
- Click the View button next to the connected entity section in the Insights dialog box.
The View button only displays if the entity is connected to another entity.

Insights dialog box revealed when clicking the Insights dropdown - Expand the sections below the selected resource name at the top of the Explore connected entities dialog box to see connected entities.
- For each connected entity you can:
- Click Open KPIs to open Knowledge Graph dashboards.
- Click RCA Workbench to add that entity to RCA workbench.
- Click See in entity graph to open the Entity graph with this resource and its connections in a visual graph.
This flow helps you move from a cloud resource (for example, a database) to the application services that use it, and then into RCA workbench or Entity graph for full context.
Manage alerts
To view alerts, navigate to the Alerts tab.
To see a recommendation for alert resolution, click the tooltip in the row of the Summary column.
In the Alert column, click the alert to view the dashboard for that service.


