Reduce metrics costs by filtering collected and forwarded metrics
Relabel Prometheus metrics to reduce usage
This guide describes several techniques you can use to reduce your Prometheus metrics usage on Grafana Cloud.
Before applying these techniques, ensure that you’re deduplicating any samples sent from high-availability Prometheus clusters. This will cut your active series count in half. To learn how to do this, please see Sending data from multiple high-availability Prometheus instances.
You can reduce the number of active series sent to Grafana Cloud in two ways:
Allowlisting: This involves keeping a set of “important” metrics and labels that you explicitly define, and dropping everything else. To allowlist metrics and labels, you should identify a set of core important metrics and labels that you’d like to keep. To enable allowlisting in Prometheus, use the
keepandlabelkeepactions with any relabeling configuration.Denylisting: This involves dropping a set of high-cardinality “unimportant” metrics that you explicitly define, and keeping everything else. Denylisting becomes possible once you’ve identified a list of high-cardinality metrics and labels that you’d like to drop. To learn how to discover high-cardinality metrics, please see Analyze metrics usage with Grafana Explore. To enable denylisting in Prometheus, use the
dropandlabeldropactions with any relabeling configuration.
Both of these methods are implemented through Prometheus’s metric filtering and relabeling feature, relabel_config. This feature allows you to filter through series labels using regular expressions and keep or drop those that match. You can also manipulate, transform, and rename series labels using relabel_config.
Prom Labs’s Relabeler tool may be helpful when debugging relabel configs. Relabeler allows you to visually confirm the rules implemented by a relabel config.
This guide expects some familiarity with regular expressions. To learn more, please see Regular expression on Wikipedia. To play around with and analyze any regular expressions, you can use RegExr.
Relabel_config syntax
You can filter series using Prometheus’s relabel_config configuration object. At a high level, a relabel_config allows you to select one or more source label values that can be concatenated using a separator parameter. The result can then be matched against using a regex, and an action operation can be performed if a match occurs.
You can perform the following common action operations:
keep: Keep a matched target or series, drop all othersdrop: Drop a matched target or series, keep all othersreplace: Replace or rename a matched label with a new one defined by thetarget_labelandreplacementparameterslabelkeep: Match theregexagainst all label names, drop all labels that don’t match (ignoressource_labelsand applies to all label names)labeldrop: Match theregexagainst all label names, drop all labels that match (ignoressource_labelsand applies to all label names)
For a full list of available actions, please see relabel_config from the Prometheus documentation.
Any relabel_config must have the same general structure:
- source_labels = [source_label_1, source_label_2, ...]
separator: ;
action: replace
regex: (.*)
replacement: $1These default values should be modified to suit your relabeling use case.
source_labels: Select one or more labels from the available setseparator: Concatenate selected label values using this characterregex: Match this regular expression on concatenated dataaction: Execute the specified relabel actionreplacement: If using one ofreplaceorlabelmap, define the replacement value. You can use regex match groups to access data captured by theregex. To learn more about regex match groups, please see this StackOverflow answer.target_label: Assign the extracted and modified label value defined byreplacementto this label name.
Parameters that aren’t explicitly set will be filled in using default values. For readability it’s usually best to explicitly define a relabel_config. To learn more about the general format for a relabel_config block, please see relabel_config from the Prometheus docs.
Here’s an example:
- source_labels: [ instance_ip ]
separator: ;
action: replace
regex: (.*)
replacement: $1
target_label: host_ipThis minimal relabeling snippet searches across the set of scraped labels for the instance_ip label. If it finds the instance_ip label, it renames this label to host_ip. Since the (.*) regex captures the entire label value, replacement references this capture group, $1, when setting the new target_label. Since we’ve used default regex, replacement, action, and separator values here, they can be omitted for brevity. However, it’s usually best to explicitly define these for readability.
To drop a specific label, select it using source_labels and use a replacement value of "". To bulk drop or keep labels, use the labelkeep and labeldrop actions.
You can use a relabel_config to filter through and relabel:
- Scrape targets
- Samples and labels to ingest into Prometheus storage
- Samples and labels to ship to remote storage
You’ll learn how to do this in the next section.
Relabel_config in a Prometheus configuration file
You can apply a relabel_config to filter and manipulate labels at the following stages of metric collection:
- Target selection in the
relabel_configssection of ascrape_configsjob. This allows you to use arelabel_configobject to select targets to scrape and relabel metadata created by any service discovery mechanism. - Metric selection in the
metric_relabel_configssection of ascrape_configsjob. This allows you to use arelabel_configobject to select labels and series that should be ingested into Prometheus storage. - Remote Write in the
write_relabel_configssection of aremote_writeconfiguration. This allows you to use arelabel_configto control which labels and series Prometheus ships to remote storage.
This sample configuration file skeleton demonstrates where each of these sections lives in a Prometheus config:
global:
. . .
rule_files:
. . .
scrape_configs:
- job_name: sample_job_1
kubernetes_sd_configs:
- . . .
relabel_configs:
- source_labels: [. . .]
. . .
- source_labels: [. . .]
. . .
metric_relabel_configs:
- source_labels: [. . .]
. . .
- source_labels: [. . .]
. . .
- job_name: sample_job_2
static_configs:
- targets: [. . .]
metric_relabel_configs:
- source_labels: [. . .]
. . .
. . .
remote_write:
- url: . . .
write_relabel_configs:
- source_labels: [. . .]
. . .
- source_labels: [. . .]
. . .Use relabel_configs in a given scrape job to select which targets to scrape. This is often useful when fetching sets of targets using a service discovery mechanism like kubernetes_sd_configs, or Kubernetes service discovery. To learn more about Prometheus service discovery features, please see Configuration from the Prometheus docs.
Use metric_relabel_configs in a given scrape job to select which series and labels to keep, and to perform any label replacement operations. This occurs after target selection using relabel_configs.
Finally, use write_relabel_configs in a remote_write configuration to select which series and labels to ship to remote storage. This configuration does not impact any configuration set in metric_relabel_configs or relabel_configs. If you drop a label in a metric_relabel_configs section, it won’t be ingested by Prometheus and consequently won’t be shipped to remote storage.
Scrape target selection using relabel_configs
A relabel_configs configuration allows you to keep or drop targets returned by a service discovery mechanism like Kubernetes service discovery or AWS EC2 instance service discovery. For example, you may have a scrape job that fetches all Kubernetes Endpoints using a kubernetes_sd_configs parameter. By using the following relabel_configs snippet, you can limit scrape targets for this job to those whose Service label corresponds to app=nginx and port name to web:
scrape_configs:
- job_name: kubernetes_nginx
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- default
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_app]
regex: nginx
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: web
action: keepThe initial set of endpoints fetched by kuberentes_sd_configs in the default namespace can be very large depending on the apps you’re running in your cluster. Using the __meta_kubernetes_service_label_app label filter, endpoints whose corresponding services do not have the app=nginx label will be dropped by this scrape job.
Since kubernetes_sd_configs will also add any other Pod ports as scrape targets (with role: endpoints), we need to filter these out using the __meta_kubernetes_endpoint_port_name relabel config. For example, if a Pod backing the Nginx service has two ports, we only scrape the port named web and drop the other.
To summarize, the above snippet fetches all endpoints in the default Namespace, and keeps as scrape targets those whose corresponding Service has an app=nginx label set. This set of targets consists of one or more Pods that have one or more defined ports. We drop all ports that aren’t named web.
Using relabeling at the target selection stage, you can selectively choose which targets and endpoints you want to scrape (or drop) to tune your metric usage.
Metric and label selection using metric_relabel_configs
Relabeling and filtering at this stage modifies or drops samples before Prometheus ingests them locally and ships them to remote storage. This relabeling occurs after target selection. Once Prometheus scrapes a target, metric_relabel_configs allows you to define keep, drop and replace actions to perform on scraped samples:
- job_name: monitoring/kubelet/1
honor_labels: true
honor_timestamps: false
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics/cadvisor
scheme: https
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- kube-system
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_k8s_app]
regex: kubelet
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: https-metrics
action: keep
. . .
metric_relabel_configs:
- source_labels: [__name__]
regex: container_(network_tcp_usage_total|network_udp_usage_total|tasks_state|cpu_load_average_10s)
action: dropThis sample piece of configuration instructs Prometheus to first fetch a list of endpoints to scrape using Kubernetes service discovery (kubernetes_sd_configs). Endpoints are limited to the kube-system namespace. Next, using relabel_configs, only Endpoints with the Service Label k8s_app=kubelet are kept. Furthermore, only Endpoints that have https-metrics as a defined port name are kept. This reduced set of targets corresponds to Kubelet https-metrics scrape endpoints.
After scraping these endpoints, Prometheus applies the metric_relabel_configs section, which drops all metrics whose metric name matches the specified regex. You can extract a sample’s metric name using the __name__ meta-label. In this case Prometheus would drop a metric like container_network_tcp_usage_total(. . .). Prometheus keeps all other metrics. You can add additional metric_relabel_configs sections that replace and modify labels here.
metric_relabel_configs are commonly used to relabel and filter samples before ingestion, and limit the amount of data that gets persisted to storage. Using metric_relabel_configs, you can drastically reduce your Prometheus metrics usage by throwing out unneeded samples.
If shipping samples to Grafana Cloud, you also have the option of persisting samples locally, but preventing shipping to remote storage. To do this, use a relabel_config object in the write_relabel_configs subsection of the remote_write section of your Prometheus config. This can be useful when local Prometheus storage is cheap and plentiful, but the set of metrics shipped to remote storage requires judicious curation to avoid excess costs.
Controlling remote write behavior using write_relabel_configs
Relabeling and filtering at this stage modifies or drops samples before Prometheus ships them to remote storage. Using this feature, you can store metrics locally but prevent them from shipping to Grafana Cloud. To learn more about remote_write, please see remote_write from the official Prometheus docs.
Prometheus applies this relabeling and dropping step after performing target selection using relabel_configs and metric selection and relabeling using metric_relabel_configs.
The following snippet of configuration demonstrates an “allowlisting” approach, where the specified metrics are shipped to remote storage, and all others dropped. Recall that these metrics will still get persisted to local storage unless this relabeling configuration takes place in the metric_relabel_configs section of a scrape job.
remote_write:
- url: <Your Metrics instance remote_write endpoint>
remote_timeout: 30s
write_relabel_configs:
- source_labels: [__name__]
regex: "apiserver_request_total|kubelet_node_config_error|kubelet_runtime_operations_errors_total"
action: keep
basic_auth:
username: <your_remote_endpoint_username_here>
password: <your_remote_endpoint_password_here>
queue_config:
capacity: 500
max_shards: 1000
min_shards: 1
max_samples_per_send: 100
batch_send_deadline: 5s
min_backoff: 30ms
max_backoff: 100msThis piece of remote_write configuration sets the remote endpoint to which Prometheus will push samples. The write_relabel_configs section defines a keep action for all metrics matching the apiserver_request_total|kubelet_node_config_error|kubelet_runtime_operations_errors_total regex, dropping all others. You can additionally define remote_write-specific relabeling rules here.
Finally, this configures authentication credentials and the remote_write queue. To learn more about remote_write configuration parameters, please see remote_write from the Prometheus docs.
Conclusion
In this guide, we’ve presented an overview of Prometheus’s powerful and flexible relabel_config feature and how you can leverage it to control and reduce your local and Grafana Cloud Prometheus usage.
Choosing which metrics and samples to scrape, store, and ship to Grafana Cloud can seem quite daunting at first. Curated sets of important metrics can be found in Mixins. Mixins are a set of preconfigured dashboards and alerts. The PromQL queries that power these dashboards and alerts reference a core set of “important” observability metrics. There are Mixins for Kubernetes, Consul, Jaeger, and much more. To learn more about them, please see Prometheus Monitoring Mixins. Allowlisting or keeping the set of metrics referenced in a Mixin’s alerting rules and dashboards can form a solid foundation from which to build a complete set of observability metrics to scrape and store.
References
- Life of Label
- relabel_configs vs metric_relabel_configs
- Advanced Service Discovery in Prometheus 0.14.0
- How relabeling in Prometheus works
- Some gists: this one and this one
- Configuration from the Prometheus docs
Reduce Kubernetes metrics usage
This guide describes some specific methods you can use to control your usage when shipping Prometheus metrics from a Kubernetes cluster.
Default deployments of preconfigured Prometheus-Grafana-Alertmanager stacks like kube-prometheus scrape and store tens of thousands of active series when launched into a K8s cluster.
A vanilla deployment of kube-prometheus in an unloaded 3-Node cluster, configured to remote_write to Grafana Cloud will count towards roughly ~50,000 active series of metrics usage.
Using the methods in this guide, you can reduce this significantly by either allowlisting metrics to ship to Grafana Cloud, or denylisting high-cardinality unneeded metrics.
If you installed the Kubernetes integration, your metrics usage should already be relatively low as these are only configured to scrape the cadvisor and kubelet endpoints of your cluster nodes.
Enabling additional scrape jobs and shipping more metrics will increase active series usage.
If you’ve installed the kube-prometheus stack using Helm, please see Migrating a Kube-Prometheus Helm stack for a metrics allowlist specific to that stack.
Before you begin
This guide assumes some familiarity with Kubernetes concepts and assumes that you have a Prometheus deployment running inside of your cluster, configured to remote_write to Grafana Cloud.
To learn how to configure remote_write to ship Prometheus metrics to Cloud, please see Prometheus metrics.
Steps to modify Prometheus’s configuration vary depending on how you deployed Prometheus into your cluster. This guide will use a default kube-prometheus installation with Prometheus Operator to demonstrate the metrics reduction methods. The steps in this guide can be modified to work with Helm installations of Prometheus, vanilla Prometheus Operator deployments, and other custom Prometheus deployments.
Deduplicating metrics data sent from high-availability Prometheus pairs
Note
Depending on the architecture of your metrics and logs collectors, you may not need to deduplicate metrics data. Be sure to confirm that you are shipping multiple copies of the same metrics before enabling deduplication.
This section shows you how to deduplicate samples sent from high-availability Prometheus deployments.
By default, kube-prometheus deploys 2 replicas of Prometheus for high-availability, shipping duplicates of scraped metrics to remote storage. Grafana Cloud can deduplicate metrics, reducing your metrics usage and active series by 50% with a small configuration change. This section implements this configuration change with the kube-prometheus stack. Steps are similar for any Prometheus Operator-based deployment.
Begin by navigating into the manifests directory of the kube-prometheus code repository.
Locate the manifest file for the Prometheus Custom Resource, prometheus-prometheus.yaml.
Prometheus Custom Resources are created and defined by Prometheus Operator, a sub-component of the kube-prometheus stack.
To learn more about Prometheus Operator, refer to its GitHub repository.
Scroll to the bottom of prometheus-prometheus.yaml and append the following three lines:
replicaExternalLabelName: "__replica__"
externalLabels:
cluster: "your_cluster_identifier"The replicaExternalLabelName parameter changes the default prometheus_replica external label name to __replica__ .
Grafana Cloud uses the __replica__ and cluster external labels to identify replicated series to deduplicate.
The value for __replica__ corresponds to a unique Pod name for the Prometheus replica.
To learn more about external labels and deduplication, please see Sending data from multiple high-availability Prometheus instances. To learn more about these parameters and the Prometheus Operator API, consult API Docs from the Prometheus Operator GitHub repository.
For a Prometheus HA deployment without Prometheus Operator, it’s sufficient to create a unique __replica__ label for each HA Prometheus instance, and a cluster label shared across both HA instances in your Prometheus configuration.
After saving and rolling out these changes, you should see your active series usage decrease by roughly 50%. It may take some time for data to propagate into your Billing and Usage Grafana dashboards, but you should see results fairly quickly in the Ingestion Rate (DPM) panel.
You can also drastically reduce metrics usage by keeping a limited set of metrics to ship to Grafana Cloud, instead of all metrics scraped by kube-prometheus in its default configuration.
Filtering and keeping kubernetes-mixin metrics (allowlisting)
This section shows you how to keep a limited set of core metrics to ship to Grafana Cloud, storing the rest locally.
The Prometheus Monitoring Mixin for Kubernetes contains a curated set of Grafana dashboards and Prometheus alerts to gain visibility into and alert on your cluster’s operations. The Mixin dashboards and alerts are designed by DevOps practitioners who’ve distilled their experience and knowledge managing Kubernetes clusters into a set of reusable core dashboards and alerts.
By default, kube-prometheus deploys Grafana into your cluster, and populates it with a core set of kubernetes-mixin dashboards. It also sets up the alerts and recording rules defined in the Kubernetes Mixin. To reduce your Grafana Cloud metric usage, you can selectively ship metrics essential for populating kubernetes-mixin dashboards to Grafana Cloud. These metrics will then be available for long-term storage and analysis, with all other metrics stored locally in your cluster Prometheus instances.
In this guide, we’ve extracted metrics found in kubernetes-mixin dashboards. You may want to include other metrics, such as those found in the mixin alerts.
To begin allowlisting metrics, navigate into the manifests directory of the kube-prometheus code repository.
Locate the manifest file for the Prometheus Custom Resource, prometheus-prometheus.yaml.
Prometheus Custom Resources are created and defined by Prometheus Operator, a sub-component of the kube-prometheus stack.
To learn more about Prometheus Operator, please see the prometheus-operator GitHub repository.
Scroll to the bottom of prometheus-prometheus.yaml and append the following to your existing remoteWrite configuration:
remoteWrite:
- url: "<Your Metrics instance remote_write endpoint>"
basicAuth:
username:
name: your_grafanacloud_secret
key: your_grafanacloud_secret_username_key
password:
name: your_grafanacloud_secret
key: your_grafanacloud_secret_password_key
writeRelabelConfigs:
- sourceLabels:
- "__name__"
regex: "apiserver_request_total|kubelet_node_config_error|kubelet_runtime_operations_errors_total|kubeproxy_network_programming_duration_seconds_bucket|container_cpu_usage_seconds_total|kube_statefulset_status_replicas|kube_statefulset_status_replicas_ready|node_namespace_pod_container:container_memory_swap|kubelet_runtime_operations_total|kube_statefulset_metadata_generation|node_cpu_seconds_total|kube_pod_container_resource_limits_cpu_cores|node_namespace_pod_container:container_memory_cache|kubelet_pleg_relist_duration_seconds_bucket|scheduler_binding_duration_seconds_bucket|container_network_transmit_bytes_total|kube_pod_container_resource_requests_memory_bytes|namespace_workload_pod:kube_pod_owner:relabel|kube_statefulset_status_observed_generation|process_resident_memory_bytes|container_network_receive_packets_dropped_total|kubelet_running_containers|kubelet_pod_worker_duration_seconds_bucket|scheduler_binding_duration_seconds_count|scheduler_volume_scheduling_duration_seconds_bucket|workqueue_queue_duration_seconds_bucket|container_network_transmit_packets_total|rest_client_request_duration_seconds_bucket|node_namespace_pod_container:container_memory_rss|container_cpu_cfs_throttled_periods_total|kubelet_volume_stats_capacity_bytes|kubelet_volume_stats_inodes_used|cluster_quantile:apiserver_request_duration_seconds:histogram_quantile|kube_node_status_allocatable_memory_bytes|container_memory_cache|go_goroutines|kubelet_runtime_operations_duration_seconds_bucket|kube_statefulset_replicas|kube_pod_owner|rest_client_requests_total|container_memory_swap|node_namespace_pod_container:container_memory_working_set_bytes|storage_operation_errors_total|scheduler_e2e_scheduling_duration_seconds_bucket|container_network_transmit_packets_dropped_total|kube_pod_container_resource_limits_memory_bytes|node_namespace_pod_container:container_cpu_usage_seconds_total:sum_rate|storage_operation_duration_seconds_count|node_netstat_TcpExt_TCPSynRetrans|node_netstat_Tcp_OutSegs|container_cpu_cfs_periods_total|kubelet_pod_start_duration_seconds_count|kubeproxy_network_programming_duration_seconds_count|container_network_receive_bytes_total|node_netstat_Tcp_RetransSegs|up|storage_operation_duration_seconds_bucket|kubelet_cgroup_manager_duration_seconds_count|kubelet_volume_stats_available_bytes|scheduler_scheduling_algorithm_duration_seconds_bucket|kube_statefulset_status_replicas_current|code_resource:apiserver_request_total:rate5m|kube_statefulset_status_replicas_updated|process_cpu_seconds_total|kube_pod_container_resource_requests_cpu_cores|kubelet_pod_worker_duration_seconds_count|kubelet_cgroup_manager_duration_seconds_bucket|kubelet_pleg_relist_duration_seconds_count|kubeproxy_sync_proxy_rules_duration_seconds_bucket|container_memory_usage_bytes|workqueue_adds_total|container_network_receive_packets_total|container_memory_working_set_bytes|kube_resourcequota|kubelet_running_pods|kubelet_volume_stats_inodes|kubeproxy_sync_proxy_rules_duration_seconds_count|scheduler_scheduling_algorithm_duration_seconds_count|apiserver_request:availability30d|container_memory_rss|kubelet_pleg_relist_interval_seconds_bucket|scheduler_e2e_scheduling_duration_seconds_count|scheduler_volume_scheduling_duration_seconds_count|workqueue_depth|:node_memory_MemAvailable_bytes:sum|volume_manager_total_volumes|kube_node_status_allocatable_cpu_cores"
action: "keep"The first chunk of this configuration defines remote_write parameters like authentication and the Cloud Metrics Prometheus endpoint URL to which Prometheus ships scraped metrics.
To learn more about remote_write, please see the Prometheus docs.
To learn about the API implemented by Prometheus Operator, please see the API Docs from the Prometheus Operator GitHub repository.
The writeRelabelConfigs section instructs Prometheus to check the __name__ meta-label (the metric name) of a scraped time series, and match it against the regex defined by the regex parameter.
This regex contains a list of all metrics found in the kubernetes-mixin dashboards.
Note
This guide is updated infreqently and this allowlist may grow stale as the mixin evolves. Also note that this allowlist was generated from the kubernetes-mixin dashboards only and does not include metrics referenced in alerting or recording rules.
The keep action instructs Prometheus to “keep” these metrics for shipping to Grafana Cloud, and drop all others.
Note that this configuration applies only to the remote_write section of your Prometheus configuration, so Prometheus will continue to store all scraped metrics locally.
If you have additional metrics you’d like to keep, you can append them to the regex parameter or in an additional relabel_config section.
When you’re done modifying prometheus-prometheus.yaml, save and close the file.
Deploy the changes in your cluster using kubectl apply -f or your preferred Kubernetes management tool.
You may need to restart or bring up new Prometheus instances to pick up the modified configuration.
After saving and rolling out these changes, you should be pushing far fewer active series. It may take some time for data to propagate into your Billing and Usage Grafana dashboards, but you should see results fairly quickly in the Ingestion Rate (DPM) panel. Any kubernetes-mixin dashboards imported into Grafana Cloud should continue to function correctly.
To test this, you can import a kubernetes-mixin dashboard into Grafana Cloud manually.
Importing a kubernetes-mixin dashboard into Grafana Cloud
Run the following command to get access to the Grafana instance running in your cluster:
kubectl --namespace monitoring port-forward svc/grafana 3000In your web browser, navigate to http://localhost:3000 and locate the API Server dashboard, which contains panels to help you understand the behavior of the Kubernetes API server.
In the top-right corner of the dashboard, click Export > Export as JSON. Next, in the Export dashboard JSON drawer that opens, click Copy to clipboard.
On Grafana Cloud, log in to Grafana, then to Manage Dashboards. Click Import and in the Import via dashboard JSON model field, paste in the dashboard JSON you just copied. Then, click Load. Optionally name and organize your dashboard, change the UID, and then click Import.
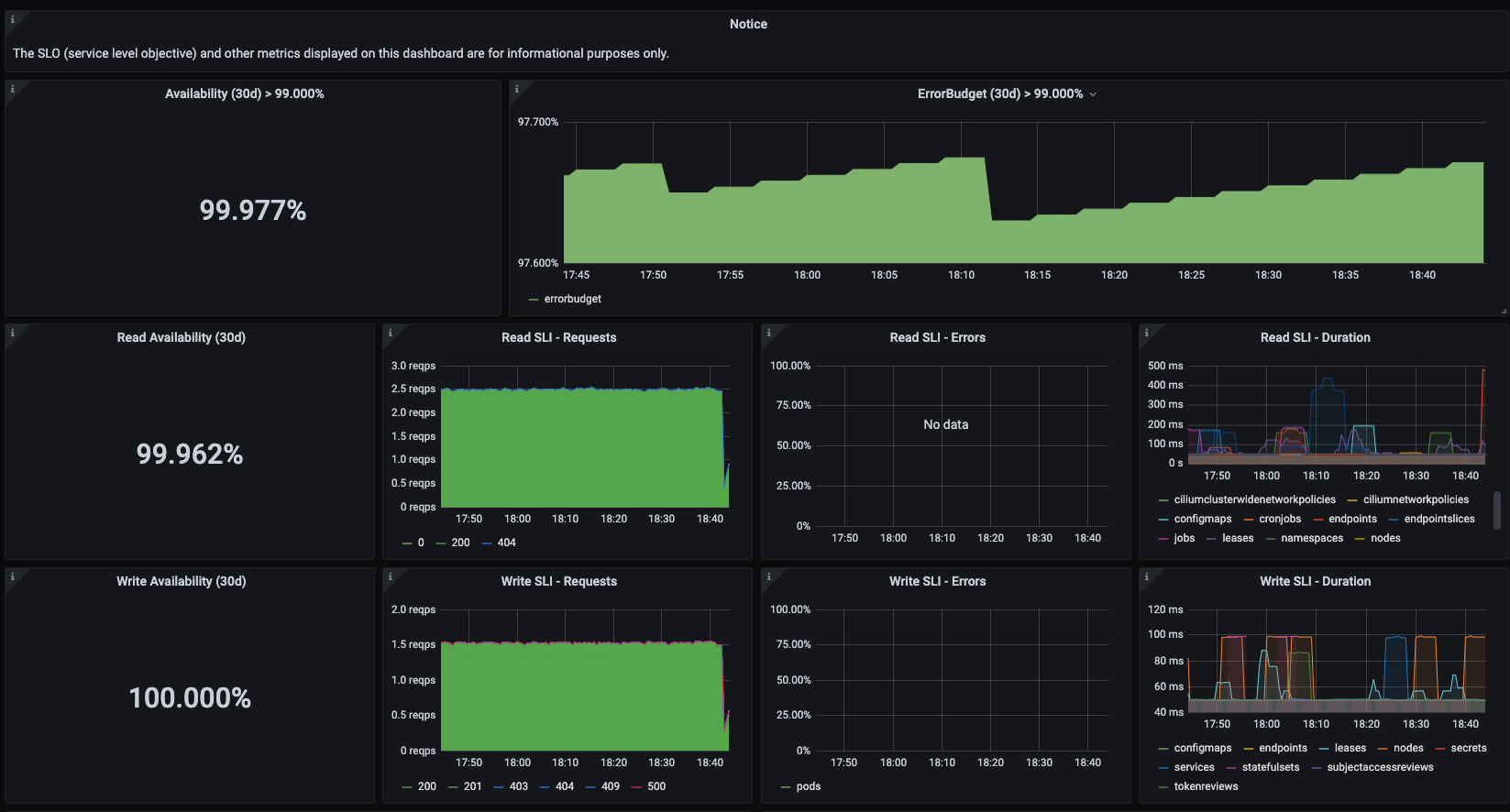
You should see your allowlisted metrics populating the dashboard panels. These metrics and this dashboard will be available in Grafana Cloud for long-term storage and efficient querying across all of your Kubernetes clusters.
You can also reduce metric usage by explicitly dropping high-cardinality metrics in your relabel_config.
Filtering and dropping high-cardinality metrics (denylisting)
You can also selectively drop high-cardinality metrics and labels that you don’t anticipate needing to warehouse in Grafana Cloud.
To analyze your metrics usage and learn how to identify potential high-cardinality metrics and labels to drop, refer to Analyze metrics usage with Grafana Explore.
The following sample write_relabel_configs drops a metric called alertmanager_build_info.
This is not a high-cardinality metric, and is only used here for demonstration purposes.
Using similar syntax, you can drop high-cardinality labels that you don’t need.
write_relabel_configs:
- source_labels: [__name__]
regex: "alertmanager_build_info"
action: dropThis config looks at the __name__ series meta-label, corresponding to a metric’s name, and checks that it matches the regex set in the regex field.
If it does, all matched series are dropped.
Note that if you add this snippet to the remote_write section of your Prometheus configuration, you will continue to store the metric locally, but prevent it from being shipped to Grafana Cloud.
You can expand this snippet to capture other high-cardinality metrics or labels that you do not wish to ship to Grafana Cloud for long-term storage. Note that this example does not use the Kubernetes Prometheus Operator API and is standard Prometheus configuration.
To learn more about write_relabel_configs, please see relabel_config from the Prometheus docs.
Conclusion
This guide describes three methods for reducing Grafana Cloud metrics usage when shipping metric from Kubernetes clusters:
- Deduplicating metrics sent from HA Prometheus deployments
- Keeping “important” metrics
- Dropping high-cardinality “unimportant” metrics
This guide has purposefully avoided making statements about which metrics are “important” or “unimportant” — this will depend on your use case and production monitoring needs. To learn more about some metrics you may wish to visualize and alert on, please see the Kubernetes Mixin, created by experience DevOps practitioners and contributors to the Prometheus and Grafana ecosystem.


