

Introdução ao monitoramento do Kubernetes
Kubernetes transformou como as equipes modernas de operações implementam e escalonam as aplicações. Embora o Kubernetes tenha simplificado muito o uso de contêineres em produção, isso não elimina a necessidade de um sistema de monitoramento robusto que permita interrogar o estado de seus sistemas.
Monitorar o Kubernetes é essencial para que você possa acompanhar métricas de desempenho, auditar mudanças nos ambientes implementados e recuperar logs que ajudam a depurar falhas de aplicativos. Solucionar problemas no Kubernetes sem uma solução de monitoramento é tedioso e propenso a erros, permitindo que os problemas se intensifiquem, pois muitas vezes passam despercebidos.
Vamos cobrir os conceitos básicos de monitoramento de clusters Kubernetes e explicar como maximizar a visibilidade de suas cargas de trabalho, identificando oportunidades chave para coletar métricas Kubernetes. Isso permitirá a detecção precoce de erros no ciclo de vida de seu sistema.
5 motivos para monitorar o Kubernetes
Aplicações em produção precisam ser monitoradas para que você possa detectar erros, otimizar o uso de recursos e gerenciar custos. O Kubernetes não é diferente: o monitoramento muitas vezes faz a diferença entre um cluster eficaz e um que é subutilizado e tem desempenho ruim.
![]()
1. Alertas em tempo real e detecção precoce de erros
Monitorar proativamente seus clusters Kubernetes ajuda a detectar erros precocemente, antes que afetem seus usuários. Arquivos de log, rastros e métricas de desempenho oferecem visibilidade do que está acontecendo em seu cluster, dando a você um aviso prévio de picos de uso e aumento nas taxas de erro. Alertas em tempo real podem informá-lo assim que os problemas começarem, evitando conversas constrangedoras que podem ocorrer quando os usuários são os primeiros a encontrar uma falha. Isso reduz o tempo de restauração do serviço, o que protege a reputação da sua marca.
![]()
2. Melhor gerenciamento de carga de trabalho e otimização
O monitoramento abrangente facilita o melhor gerenciamento da carga de trabalho e o uso mais ótimo de seus recursos. Monitorar seu cluster Kubernetes pode revelar que há muita contenda de recursos, ou distribuição irregular de pods de aplicativos através de seus nós. Ajustes simples de agendamento, como definir afinidades e anti-afinidades, podem melhorar significativamente o desempenho e a confiabilidade, mas você perderá essas oportunidades sem insights sobre o uso real do cluster.
![]()
3. Resolução de problemas mais fácil
O monitoramento oferece assistência quando você está solucionando problemas. Acessar logs do seu aplicativo e componentes do Kubernetes é muitas vezes a melhor maneira de descobrir passos para reprodução e trabalhar para descobrir as causas raízes. Sem uma solução de monitoramento, você teria que hipotetizar prováveis fontes de problemas e então usar tentativa e erro para testar correções. Isso aumenta a carga de trabalho para os desenvolvedores, especialmente aqueles novatos que não estão familiarizados com o sistema. Ser capaz de identificar problemas mais cedo minimiza o tempo de inatividade e encoraja todos a contribuir.
![]()
4. Visibilidade de custos em tempo real
O choque de conta do Kubernetes é real. Arquiteturas de autoescalamento permitem adaptar-se em tempo real à demanda variável, mas isso também pode criar custos que aumentam rapidamente. O monitoramento é essencial para que você possa visualizar o número de nós, balanceadores de carga e volumes persistentes que estão atualmente implementados em sua conta na nuvem. Cada um desses objetos geralmente incorrerá em um custo separado do seu provedor.
![]()
5. Insights poderosos
O monitoramento do Kubernetes pode gerar insights únicos que destacam oportunidades para aprimorar seu serviço. Além de métricas simples de desempenho, o monitoramento ajuda a revelar como os usuários interagem com seu aplicativo, o que pode informar decisões futuras do produto. Dados de componentes, como controladores de ingresso, revelarão os endpoints que são mais chamados, bem como a quantidade de dados que fluem por sua infraestrutura. Essas informações fornecem um ponto de partida quando procurar por recursos que precisam de mais expansão, seja devido ao engajamento ativo ou baixo uso por causa da difícil descoberta.
Monitoramento no Kubernetes: componentes-chave
Um cluster Kubernetes compõe-se de diversos componentes que trabalham juntos para dar suporte a workloads containerizados. Você encontrará alguns desses durante a administração do dia a dia, mas outros coordenam operações nos bastidores.
A arquitetura básica do Kubernetes é que as aplicações são executadas como contêineres dentro de pods. Os pods são distribuídos por diversos nodes, que representam as máquinas físicas em seu cluster. Os nodes são coordenados pelo plano de controle, que inclui o servidor API para interagir com seu cluster e vários controladores. Controladores observam por mudanças no seu cluster e tomam ação para alcançar o novo estado desejado, como iniciar contêineres quando você adiciona um objeto pod.
A complexidade de um cluster Kubernetes significa que uma abordagem multifacetada para o monitoramento sempre será necessária. Cada item no seguinte diagrama deve ser observado, para que você possa acompanhar o desempenho de toda a sua infraestrutura:
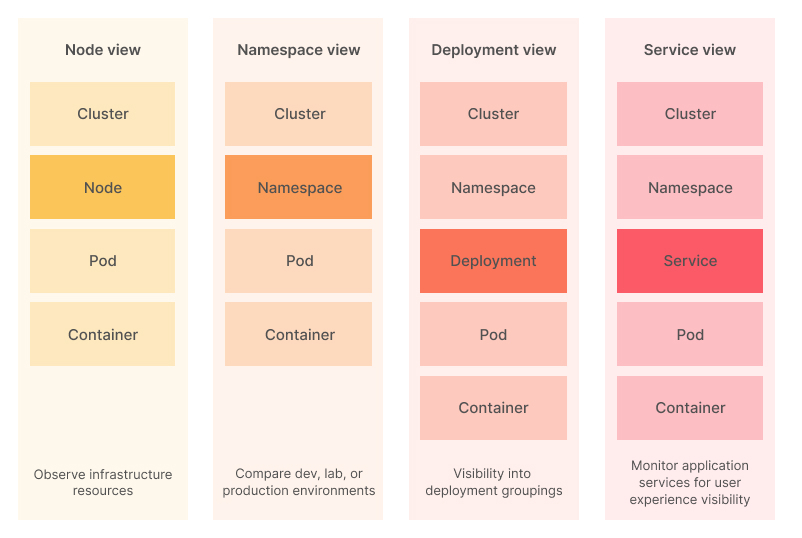
A seguir, revisaremos alguns desses componentes e como você pode coletar métricas a partir deles.
Métricas de desempenho
O monitoramento de desempenho permite investigar questões de capacidade do cluster e identificar quando é hora de adicionar mais recursos. As métricas recolhidas permitirão identificar tendências de consumo de recursos, possibilitando antecipar lentidões notáveis para os usuários.
Métricas de utilização de recursos do node
Métricas de utilização de recursos do node, como consumo de CPU e memória, podem ser obtidas usando vários mecanismos. O mais comum é executar um agente como o Prometheus Node Exporter em cada node. O agente de métricas periodicamente coleta as métricas atuais do node e envia os dados para sua plataforma de observabilidade.
Alternativamente, quando você tem a API de Métricas instalada em seu cluster, o próprio Kubernetes pode coletar esses dados. Usar a API de Métricas permite acessar métricas de node em seu terminal usando o comando kubectl top. Ele fornece monitoramento de recursos de forma conveniente, sem qualquer dependência externa.
Clusters Kubernetes implementados pelos principais provedores de nuvem geralmente têm seus próprios dashboards de monitoramento também. Você pode ser capaz de fazer login na sua conta de nuvem para visualizar gráficos básicos de métricas-chave sem configurar nada por conta própria. Isso oferece uma opção conveniente de início rápido, mas pode não necessariamente mostrar tudo o que você precisa saber.
Monitorar essas métricas fundamentais de utilização de hardware essencialmente permite antecipar o uso futuro e aumentar a capacidade antes da demanda. Um consumo regularmente alto de CPU e memória reduz a margem de desempenho do seu serviço. Isso pode levar a interrupções e instabilidade se ocorrer um pico de uso.
Métricas de capacidade e saúde de objetos
O serviço kube-state-metrics (KSM) ouve eventos do servidor API do Kubernetes e expõe métricas no Prometheus que documentam o estado dos objetos do seu cluster. Mais de mil métricas diferentes fornecem o status, capacidade e saúde de contêineres individuais, pods, deployments e outros recursos.
Você pode usar essa instrumentação para interrogar profundamente os objetos em seu cluster. A API de Métricas de Pod, por exemplo, fornece mais de 40 pontos de dados individuais sobre cada pod, incluindo o status do pod, o tempo decorrido desde sua última transição de estado, o número de reinícios que ocorreram e os limites de recursos que se aplicam a ele. APIs individuais estão disponíveis para todos os outros tipos de objetos incorporados do Kubernetes.
Monitorar essas métricas pode alertá-lo tanto para problemas do cluster quanto para problemas de aplicativos. Pods com contagens altas de reinício podem sugerir que há contenção de recursos no cluster ou um bug em seu aplicativo que está causando falhas. Métricas expostas pelo KSM são fornecidas de forma bruta, conforme coletadas pelo plano de controle do Kubernetes, permitindo que você as processe e analise sem preparação.
Saúde do Armazenamento
Kube-state-metrics (KSM) também pode ser usado para monitorar a saúde do armazenamento. Ele inclui APIs que expõem métricas para classes de armazenamento, volumes persistentes e reclamações de volume persistente, como a capacidade dos volumes, se estão atualmente disponíveis e a quantidade de espaço solicitada por cada reivindicação.
Outra maneira de revisar a saúde do armazenamento é com o sistema de Monitoramento de Saúde do Volume. Esse recurso alpha está embutido no Kubernetes e fornece métricas que descrevem a saúde geral dos seus volumes persistentes. Ele inclui um controlador dedicado que observa condições anormais de volume que podem indicar um problema com seu armazenamento. O controlador também define eventos em seus volumes quando pods que acessam-nos são programados para nodes com falha. Isso permite verificar se os pods que reivindicaram um volume estão realmente operacionais.
Kubelet metrics
The Kubelet process that runs on your Kubernetes nodes provides detailed metrics that can be scraped using Prometheus. These are accessed via the /metrics endpoint on port 10255.
First discover your node’s IP address inside your cluster:
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
minikube Ready control-plane,master 74d v1.23.3 192.168.49.2 <none> Ubuntu 20.04.2 LTS 5.4.0-122-generic docker://20.10.12This node has the IP address 192.168.49.2. Now you can query its metrics data by accessing port 10255:
curl http://192.168.49.2:10255/metrics
# HELP apiserver_audit_event_total [ALPHA] Counter of audit events generated and sent to the audit backend.
# TYPE apiserver_audit_event_total counter
apiserver_audit_event_total 0
# HELP apiserver_audit_requests_rejected_total [ALPHA] Counter of apiserver requests rejected due to an error in audit logging backend.
# TYPE apiserver_audit_requests_rejected_total counter
apiserver_audit_requests_rejected_total 0
# HELP apiserver_client_certificate_expiration_seconds [ALPHA] Distribution of the remaining lifetime on the certificate used to authenticate a request.
# TYPE apiserver_client_certificate_expiration_seconds histogram
apiserver_client_certificate_expiration_seconds_bucket{le="0"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="1800"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="3600"} 0
...The Kubelet metrics endpoint can be used to interrogate your node’s performance inside your cluster. The data exposes statistics that relate to Kubelet’s interactions with the Kubernetes control plane, such as the number of tasks in the work queue and the time taken to fulfill API requests.
Kubelet also provides cAdvisor metrics at the /metrics/cadvisor endpoint. cAdvisor (Container Advisor) is a tool that analyzes the resource usage and performance characteristics of your containers.
curl http://192.168.49.2:10255/metrics/cadvisor
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="",cadvisorVersion="",dockerVersion="",kernelVersion="5.4.0-122-generic",osVersion="Ubuntu 20.04.2 LTS"} 1
# HELP container_blkio_device_usage_total Blkio Device bytes usage
# TYPE container_blkio_device_usage_total counter
container_blkio_device_usage_total{container="",device="/dev/nvme0n1",id="/",image="",major="259",minor="0",name="",namespace="",operation="Async",pod=""} 0 1660656772812
container_blkio_device_usage_total{container="",device="/dev/nvme0n1",id="/",image="",major="259",minor="0",name="",namespace="",operation="Discard",pod=""} 0 1660656772812
container_blkio_device_usage_total{container="",device="/dev/nvme0n1",id="/",image="",major="259",minor="0",name="",namespace="",operation="Read",pod=""} 778240 1660656772812
...These metrics facilitate analysis of CPU, memory, disk, and network utilization at the container level. Once you’ve identified a busy node using the cluster-level metrics discussed above, you can use the node’s cAdvisor output to find containers that are using too many resources and causing contention with other objects. High utilization could be down to an increase in user activity, suggesting you need to scale your service with more pods, or missing optimizations within the container that are causing elevated load.
Logs do Kubernetes
Além de métricas de desempenho e utilização de recursos, é importante capturar e reter logs do Kubernetes para que você possa consultá-los no futuro. Vários componentes do Kubernetes escrevem eventos e erros diretamente em arquivos de log no sistema de arquivos do host. Aqui estão alguns caminhos comuns para inspeção.
No nó do plano de controle do Kubernetes, olhe os seguintes logs:
/var/log/kube-apiserver.log: Este log contém eventos que ocorreram dentro do servidor da API do Kubernetes./var/log/kube-scheduler.log: Um registro das decisões de agendamento, criado quando o Kubernetes decide em qual nó colocar um pod./var/log/kube-controller-manager.log: O log do gerenciador de controle do Kubernetes, responsável por executar todos os controladores integrados que observam a atividade em seu cluster.
Nos nós de trabalho individuais, veja os seguintes logs:
/var/log/kubelet.log: O processo kubelet é responsável por manter a comunicação entre os nós e o servidor do plano de controle do Kubernetes. Este arquivo de log deve ser seu ponto de partida quando você estiver solucionando por que um nó se tornou indisponível./var/log/kube-proxy.log: Aqui estão armazenados os logs do processokube-proxy. O processokube-proxyé responsável por rotear o tráfego por meio de serviços para pods no nó.
Você pode acessar esses arquivos de log usando um coletor de dados como o Promtail ou o Grafana Agent para transmitir novas linhas diretamente para sua plataforma de monitoramento. Instalar um desses agentes em seus nós automatizará a coleta de logs. Isso permite você visualizar logs ao lado de suas métricas de desempenho e elimina a necessidade de conectar manualmente a um nó para acessar seus logs usando ferramentas Unix como cat e tail.
O Promtail também funciona com logs em nível de contêiner escritos por suas aplicações. O Kubernetes cria logs de contêiner a partir dos dados que seu processo escreve em suas saídas padrão e de erro. Você deve configurar suas aplicações para suportar esse mecanismo, já que logs que são diretamente escritos no sistema de arquivos do contêiner serão destruídos quando ele for reiniciado. Isso pode tornar muito mais difícil investigar bugs e falhas, pois você perderá acesso a mensagens de erro registradas e rastreamentos de pilha.
Usar um agente para coletar logs de contêineres e enviá-los para uma plataforma de monitoramento torna seu conteúdo mais acessível. Você será capaz de pesquisar e filtrar linhas de log em vez de depender da saída cronológica simples que o comando o kubectl logs fornece. A maioria das soluções de agregação de logs, como o Grafana Loki, também suporta o arquivamento de logs a longo prazo, permitindo revisitá-los após os contêineres terem sido reiniciados ou substituídos.
Rastros
O rastreamento é uma forma de registro que captura detalhes precisos sobre eventos que ocorrem durante a execução de um programa. Embora a distinção entre rastreamento e registro às vezes seja vaga, rastros brutos podem ser esperados para serem verbosos, barulhentos e projetados para fornecer máxima fidelidade aos desenvolvedores. Geralmente, os rastros consistem na sequência de camadas da pilha de código que levam a um evento.
Por contrast, mensagens de log geralmente contêm informações mais centradas no humano. Elas documentam que um evento ocorreu sem explicar o que levou a isso. Uma mensagem de log pode ser “falha ao processar pagamento.” O rastro correspondente deve mostrar o passo a passo pelo código, desde o ponto de entrada da aplicação até tentar chamar um provedor de pagamento externo e receber um erro em resposta.
Operações individuais dentro dos rastros são referidas como spans. No exemplo acima, o rastro é toda a operação, desde o usuário iniciar o pagamento até o resultado ser determinado. Dentro do rastro, poderia haver os seguintes spans:
- Validar a entrada do usuário, como detalhes do cartão e códigos de voucher.
- Recuperar o conteúdo da cesta do usuário.
- Enviar os dados para o provedor de pagamento backend.
- Armazenar o resultado da transação.
- Enviar um e-mail de confirmação de pedido.
Spans geralmente têm seus próprios metadados associados a eles, como seu pai imediato, duração e a operação que foi realizada. Essa distinção permite que você se aprofunde em partes específicas de eventos individuais, reduzindo sua busca por problemas.
A capacidade de revisar os caminhos de código tomados por solicitações pode ser inestimável quando você está depurando problemas relatados por usuários. Nem todo problema é facilmente reproduzível em desenvolvimento; rastros permitem que você veja exatamente o que aconteceu durante a sessão do usuário, tornando a resolução de problemas mais eficiente. Sem um rastro, você teria que pedir ao usuário para confirmar os passos exatos que eles tomaram antes do bug ocorrer. Isso nem sempre é possível e não necessariamente levará a uma reprodução bem sucedida. Rastros fornecem todos os dados necessários, permitindo que você vá diretamente para a remediação.
O Kubernetes também tem rastreamento integrado. Vários componentes do sistema expõem rastros para que você possa entender melhor as operações internas do seu cluster e medir o desempenho. O rastreamento integrado em nível de cluster pode ser útil quando você está diagnosticando um problema geral que afeta todas as suas aplicações, mas o rastreamento implantado pelo usuário no nível da aplicação é mais eficaz quando você está analisando precisamente a execução do seu código.
Eventos do Kubernetes
O Kubernetes mantém um histórico abrangente de todos os eventos que ocorrem no seu cluster. Você pode visualizar os eventos no seu terminal usando o kubectl:
$ kubectl get events
LAST SEEN TYPE REASON OBJECT MESSAGE
1m Normal Criado pod/demo-pod Created container demo-pod
1m Normal Iniciado pod/demo-pod Started container demo-podCada evento inclui o nome do objeto ao qual se refere, a ação que ocorreu, o estado do objeto (como “Normal” ou “Falha”) e uma mensagem que descreve brevemente o que aconteceu. Isso fornece um histórico abrangente da atividade no seu cluster, incluindo eventos gerados pelo plano de controle do Kubernetes, bem como aqueles produzidos em resposta às ações do usuário.
Você pode obter os eventos associados a um objeto específico filtrando com a bandeira --field-selector. Este exemplo recupera os eventos para o pod demo-pod combinando os campos involvedObject.kind e involvedObject.name em objetos de evento:
$ kubectl get events \
--field-selector involvedObject.kind=Pod \
--field-selector involvedObject.name=demo-pod
LAST SEEN TYPE REASON OBJECT MESSAGE
1m Normal Criado pod/demo-pod Created container demo-pod
1m Normal Iniciado pod/demo-pod Started container demo-podVocê pode modificar este exemplo para suportar qualquer outro objeto, substituindo o campo involvedObject.kind pelo nome do tipo de objeto que está procurando, como Deployment, ReplicaSet ou Job.
Os eventos podem ser inestimáveis para entender a sequência de ações que levaram a um problema específico. Praticamente todas as ações relacionadas a um objeto aparecerão na lista, desde a criação bem-sucedida de um contêiner até jobs falhos, erros de extração de imagem e condições de memória baixa.
O Kubernetes trata os eventos como registros transitórios que são automaticamente limpos logo após ocorrerem. Na maioria dos casos, os eventos são deletados após apenas uma hora. Você deve usar um coletor de dados baseado em agente para transmitir eventos para uma solução de observabilidade como o Grafana. Isso permitirá que você recupere, pesquise e arquive eventos muito tempo após eles terem ocorrido, fornecendo outro ponto de referência ao solucionar problemas futuros.
Métricas de aplicativos conteinerizados
É importante monitorar suas cargas de trabalho conteinerizadas juntamente com a saúde do seu cluster. A criação da sua própria API de métricas de aplicativos que exporta dados compatíveis com o Prometheus permitirá que você raspe estatísticas de desempenho usando sua solução de observabilidade.
O Prometheus tem bibliotecas oficiais do lado do cliente para Go, Java/Scala, Python, Ruby e Rust. Opções suportadas pela comunidade estão disponíveis para a maioria das outras linguagens populares também. Essas bibliotecas permitem definir e expor métricas de aplicativos personalizados usando um ponto de extremidade HTTP na instância do seu aplicativo.
Como exemplo, você pode querer acompanhar quanto tempo leva para realizar funções de negócios específicas, como lidar com um login ou completar uma transação de pagamento. O Prometheus simplifica a medição dessas durações e a exposição delas como métricas que você pode raspar, minimizando a quantidade de código que você precisa escrever.
Tomar o tempo para instrumentar suas cargas de trabalho fortalece a observabilidade, permitindo analisar o desempenho no nível do aplicativo. É, em última análise, o tempo necessário para processar funções do aplicativo que mais importa para os usuários, e não o consumo absoluto de CPU ou a utilização do cluster. Acompanhar tendências em medições específicas do negócio revela oportunidades para melhorar a experiência do usuário e permite detectar problemas de desempenho emergentes antes de se tornarem um problema no nível do node ou do cluster.
Conclusão
O Kubernetes tem mais partes móveis do que soluções de implantação tradicionais e requer uma abordagem nova para monitoramento e observabilidade. Além de métricas básicas de login, saúde da aplicação e utilização de recursos, você também precisa avaliar o desempenho dos componentes individuais dentro do plano de controle do Kubernetes.
Neste artigo, analisamos os componentes que devem ser considerados ao criar uma solução abrangente de monitoramento do Kubernetes. Focar nas áreas listadas acima fornecerá insights que revelam a operação interna do seu cluster e suas cargas de trabalho. Você poderá identificar problemas emergentes cedo, bem como novas oportunidades para melhorar e aprimorar o uso do seu cluster.
Comece com o Monitoramento do Kubernetes no Grafana Cloud
Seja você um desenvolvedor de aplicativos implementando novas mudanças, um SRE buscando uma maneira melhor de solucionar incidentes de infraestrutura, ou um administrador DevOps mantendo os servidores de metal que executam os clusters, Grafana Labs está aqui para ajudar. Conheça o Kubernetes Monitoring, a solução completa para todos os níveis de uso do Kubernetes com acesso direto às métricas da infraestrutura do Kubernetes, logs e eventos do Kubernetes, bem como painéis e alertas pré-construídos. Kubernetes Monitoring está disponível para todos os usuários do Grafana Cloud, incluindo aqueles no generoso nível gratuito para sempre.