Configure the Databricks data source
This document describes configuration options for the Databricks data source in Grafana.
Before you begin
You must install the Databricks plugin before adding the data source. Refer to Install a plugin for instructions on how to add the plugin. For general information on adding and managing plugins refer to Plugin management. Grafana recommends keeping your plugin up-to-date to access all current features.
You must have the
Organization administratorrole to configure the Databricks data source. Organization administrators can also configure the data source via YAML with the Grafana provisioning system.Familiarize yourself with your Databricks security configuration and gather any necessary security certificates and client keys. You will need this information to set up your connection.
Note
This plugin uses dynamic links for Credentials authentication (deprecated). Grafana suggests using Token authentication instead. The plugin does not work with Credentials authentication when run on bare Alpine Linux. If Token based authentication is not an option and Alpine Linux is a requirement, Grafana recommends using Alpine images.
Configure the data source using the UI
To add the Databricks data source, complete the following steps:
- Install the Databricks plugin.
- Click Connections in the left-side menu.
- Under Connections, click Add new connection.
- Enter
Databricksin the search bar. - Select Databricks under the Data Source section.
- Click Add new data source in the upper right.
You are taken to the Settings tab where you will set up your Databricks configuration.
Configuration options
Following is a list of configuration options for Databricks.
Authentication type: Choose an authentication type. The configuration options displayed will vary according to the selected authentication method.
Personal Access Token (PAT): Enter the token generated in your Databricks workspace. For additional information, refer to Manage personal access token permissions in the Databricks documentation.
PAT specific fields:
OAuth Machine-to-Machine (M2M): Service-to-service authentication with no human interaction. With OAuth M2M, Grafana uses a registered application (a service principal) in Databricks. This means authentication is tied to an application identity, not a user, which is more secure and easier to manage long term.
OAuth M2M specific fields:
OAuth Passthrough: Passes through the user’s existing OAuth credentials.
OAuth Passthrough–specific fields:
Azure On-behalf-of (OBO) Authentication: This method of authentication allows Grafana to act on behalf of individual users using their own Azure Active Directory (Microsoft Entra ID) credentials.
Azure On-behalf-of (OBO) Authentication–specific fields:
Private data source connect - Only for Grafana Cloud users.
Private data source connect, or PDC, allows you to establish a private, secured connection between a Grafana Cloud instance, or stack, and data sources secured within a private network.
Click the drop-down to locate the URL for PDC. For more information regarding Grafana PDC, refer to Private data source connect (PDC) and Configure Grafana private data source connect (PDC) for instructions on setting up a PDC connection.Click Manage private data source connect to open your PDC connection page to view your configuration details.
After configuring your Databricks data source options, click Save & test at the bottom to test the connection. You should see a confirmation dialog box that says:
Data source is working.
OAuth Passthrough with Microsoft Entra ID
If you are using OAuth Passthrough with Microsoft Entra ID (formerly Azure Active Directory), complete the following steps:
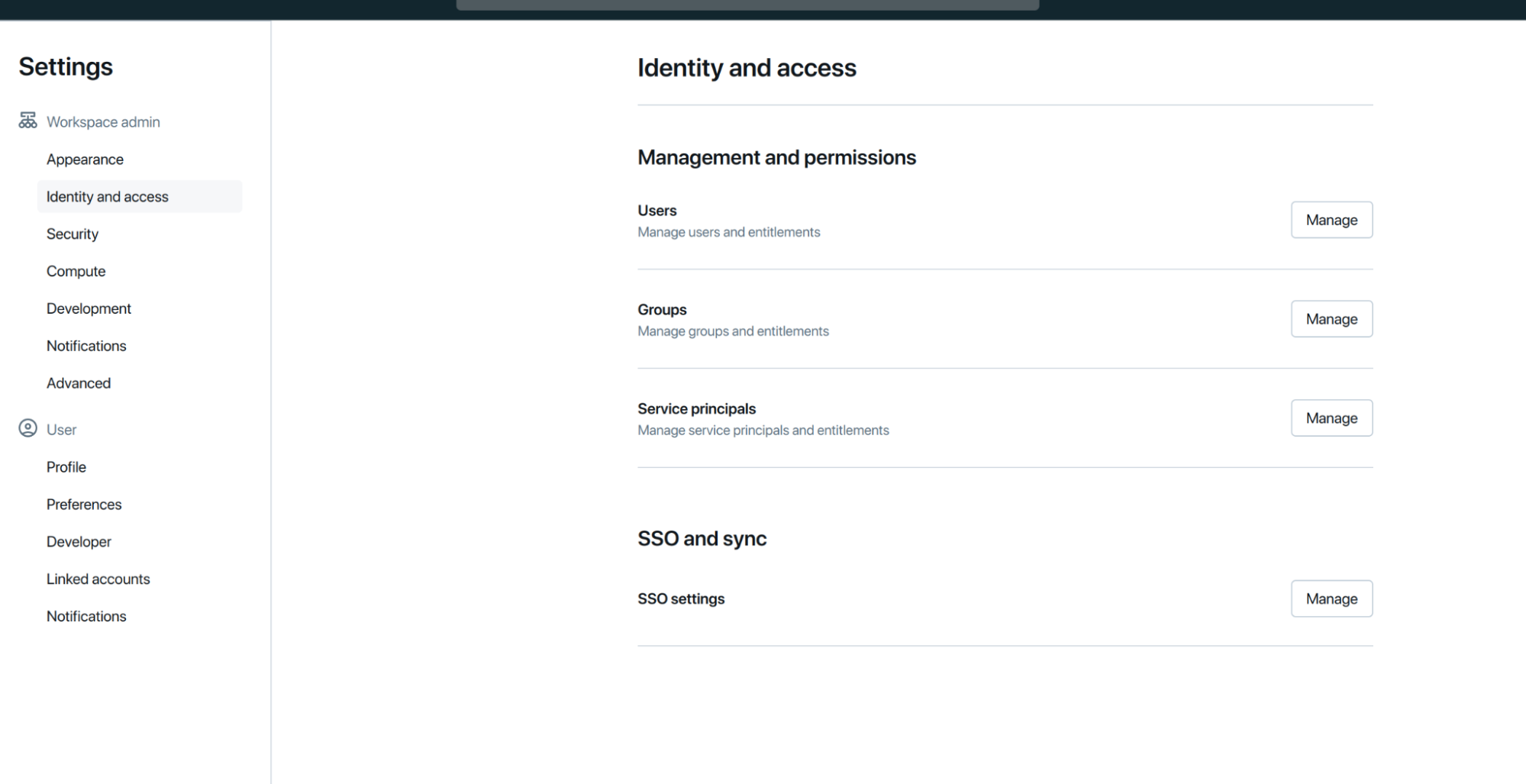
- In your Databricks workspace, navigate to Settings > Identity and access > SSO and sync > SSO Settings, then click Manage.
![Databricks dashboard]()
- Copy the Databricks SAML URL. Don’t close this tab.
![Databricks dashboard]()
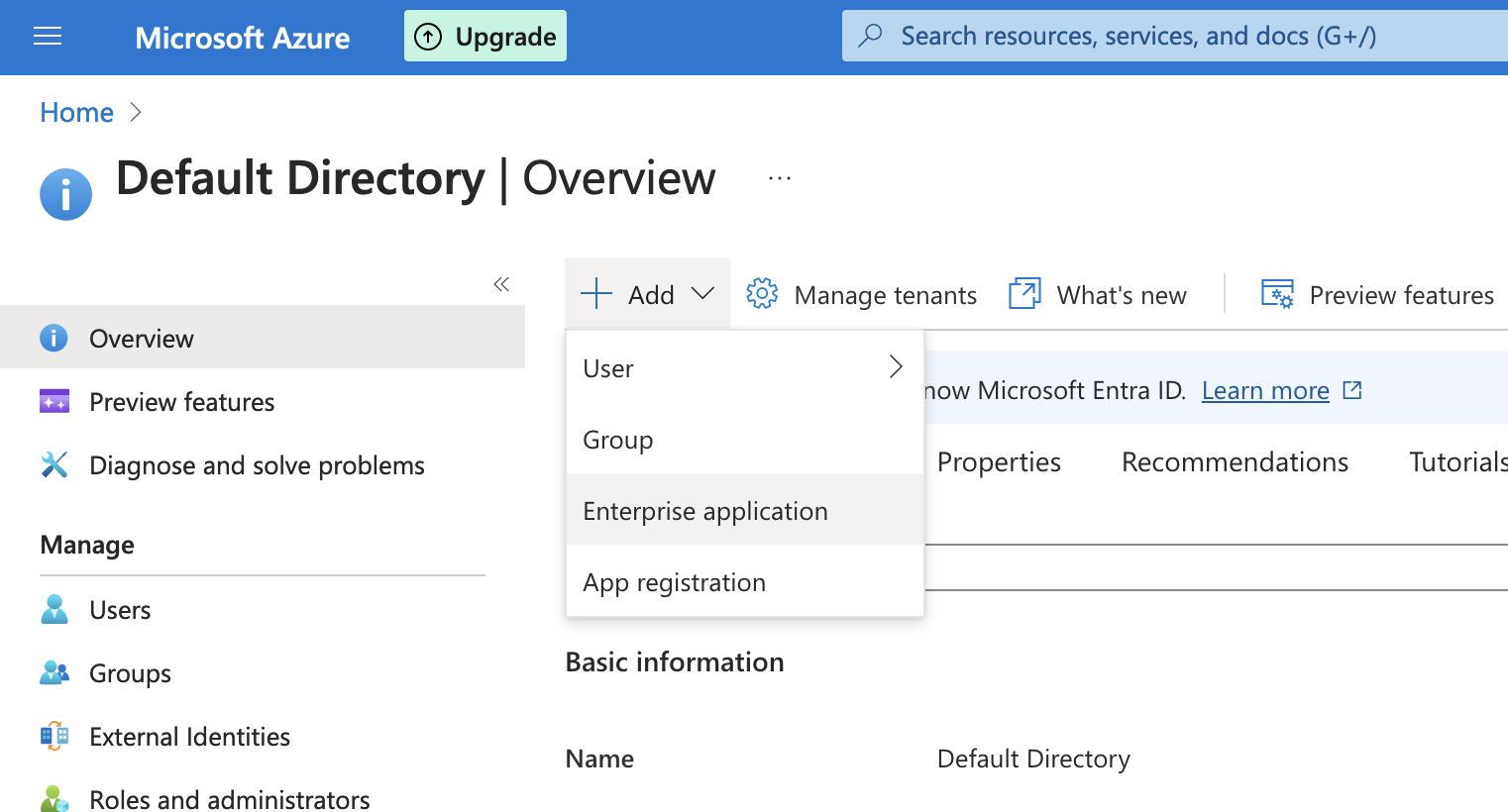
- In a new tab, open the Azure Portal.
- Go to Microsoft Entra ID > Add > Enterprise Application.
![Microsoft Entra ID Add Enterprise Application screen]()
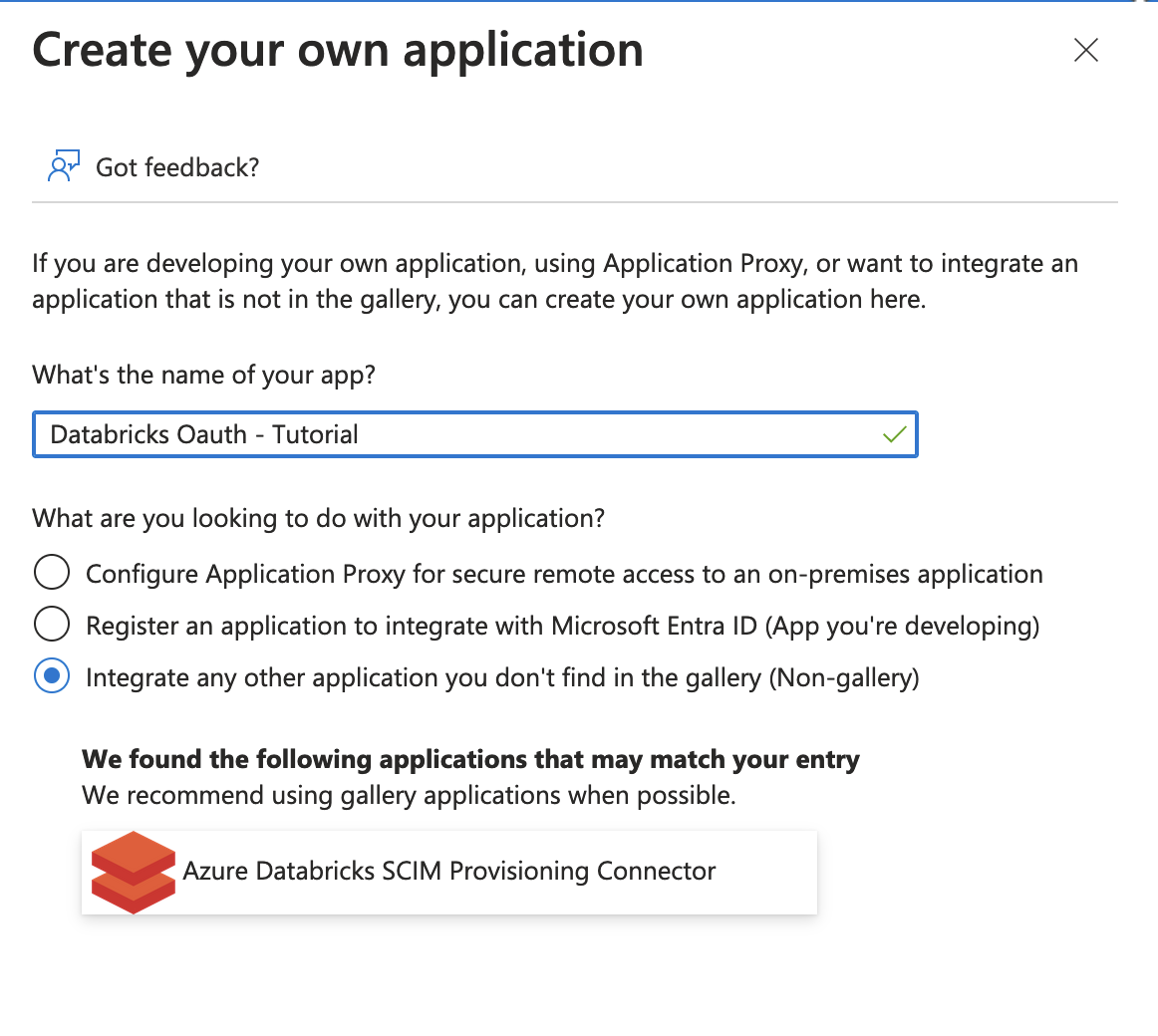
- Enter a name for the application. When prompted with “What are you looking to do with your application?”, select Integrate any other application you don’t find in the gallery.
![Databricks create application screen]()
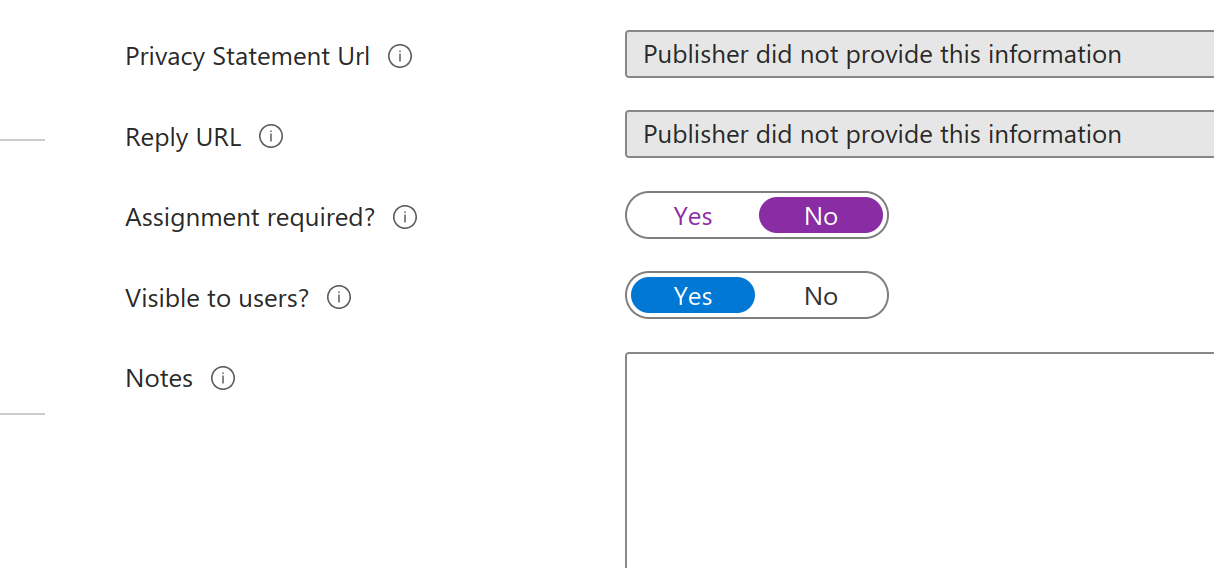
- Under Properties, set Assignment required to No.
![Databricks create application screen]()
- Under Single sign-on, click SAML, then under Basic SAML Configuration, click Edit.
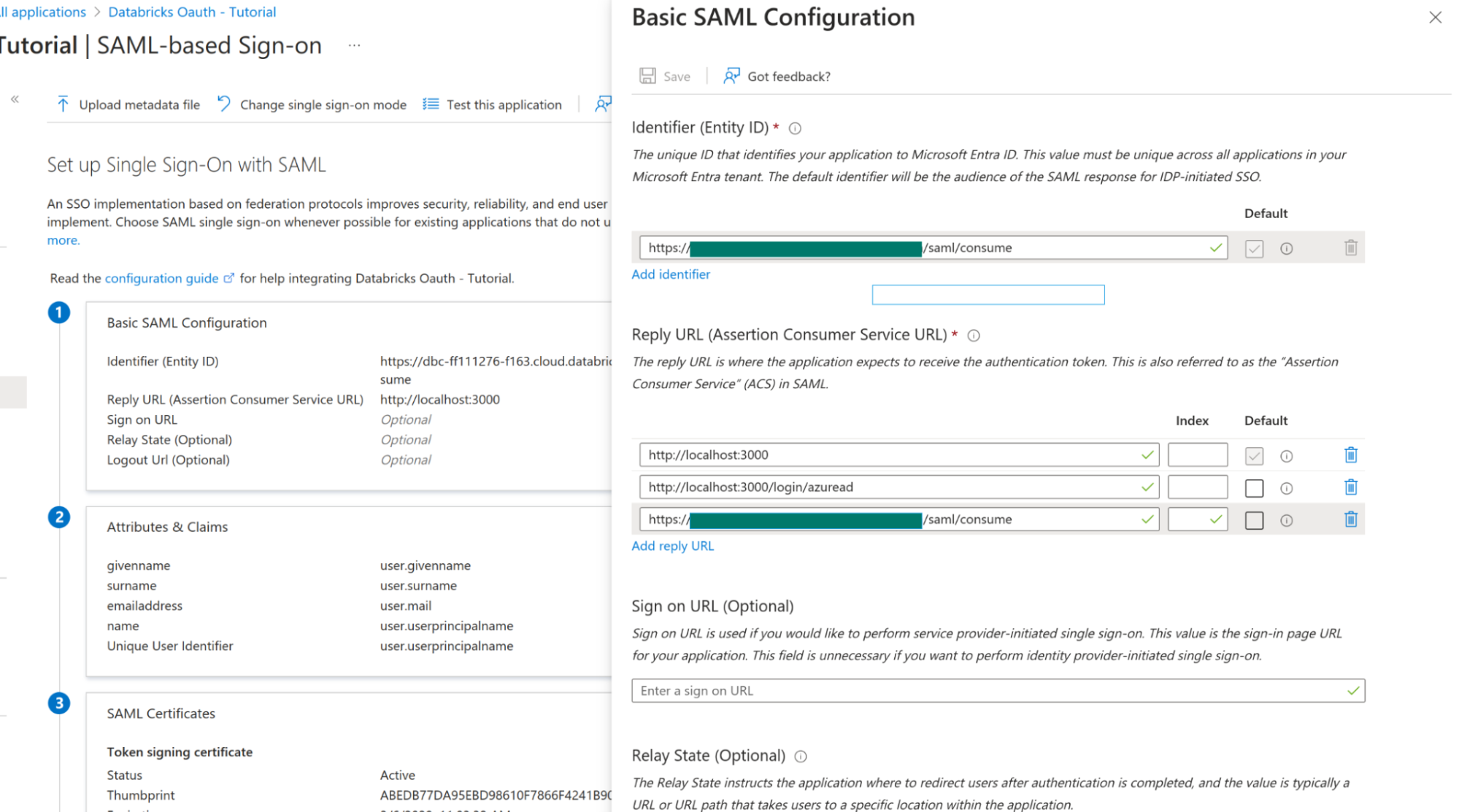
- Set Identifier (Entity ID) to the Databricks SAML URL you copied earlier.
For Reply URLs, enter both:- The same Databricks SAML URL, and
- The
Grafana redirect URLs.
![Basic SAML Configuration]()
- Under SAML Signing Certificate, click Edit.
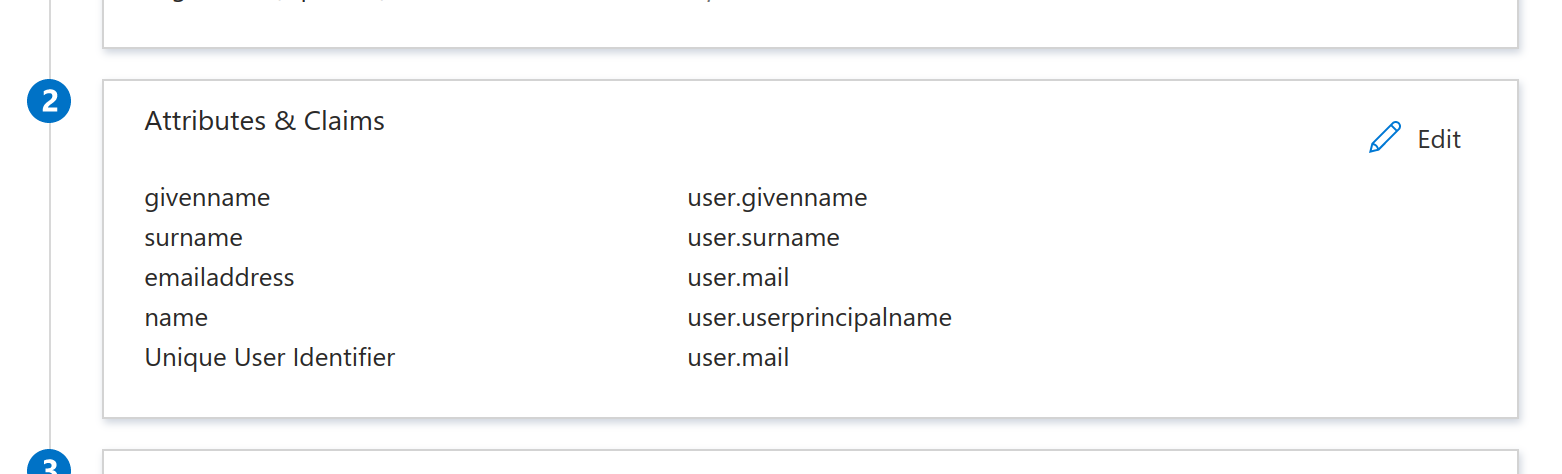
Set Sign-in option to Sign SAML response and assertion, then click Save. - Under Attributes & Claims, click Edit.
Set the Unique User Identifier (Name ID) field touser.mail.![Basic SAML Configuration]()
- Under SAML Certificates, next to Certificate (Base64), click Download.
This downloads a.cerfile. Copy its contents for later use in Databricks. - Also save the Login URL and Microsoft Entra ID Identifier for your Databricks configuration.
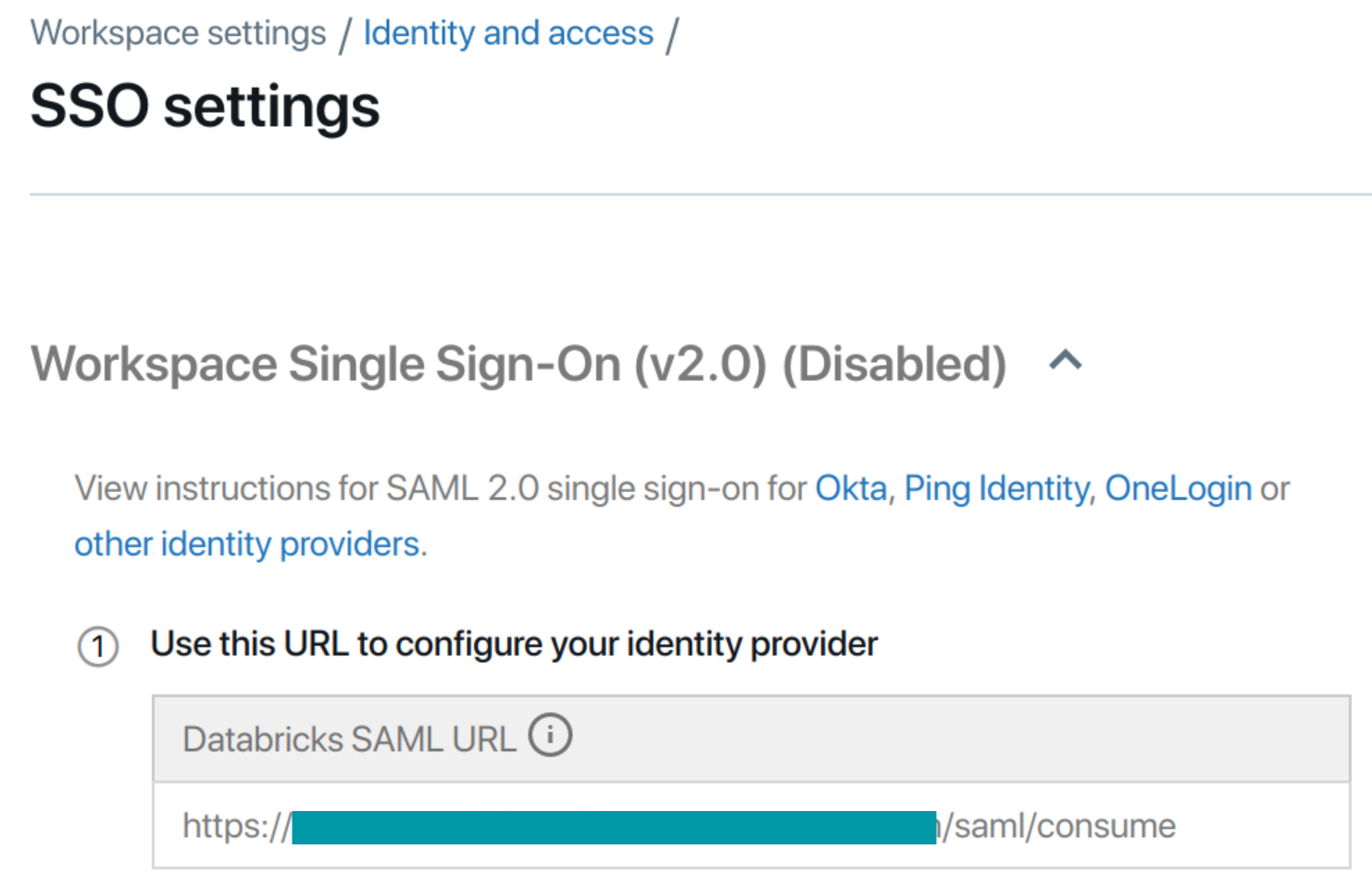
- Return to your Databricks SSO Settings tab and update the following fields:
- Single Sign-On URL → enter the Login URL (from the previous step).
- Identity Provider Entity ID → enter the Microsoft Entra ID Identifier (from the previous step).
- X.509 Certificate → paste the contents of the downloaded certificate.
Complete Grafana OAuth setup
To complete the Grafana OAuth setup, follow these steps:
In the Azure Portal, go to App registrations > All applications, and select your application.
On the Overview page, note the following values:
- Application (client) ID – Used as the OAuth client ID in your
conf.inifile. - Directory (tenant) ID – Also required in your Grafana configuration.
- Application (client) ID – Used as the OAuth client ID in your
Click Endpoints, and note the following URLs:
- OAuth 2.0 authorization endpoint (v2) – This is your Authorization URL.
- OAuth 2.0 token endpoint (v2) – This is your Token URL.
Navigate to Certificates & secrets. Under Client secrets, click New client secret.
Create a new client secret with the following configuration:
- Description:
Grafana OAuth - Expires:
Never
- Description:
Click Add, then copy the Value of the newly created secret. This value is your OAuth client secret.
Define required roles
To enable secure access control and manage which users can query Databricks data through Grafana, you must define the appropriate roles in Microsoft Entra ID. This ensures that Grafana can properly authenticate and authorize users based on their assigned roles.
- In the Microsoft Entra ID portal, navigate to Enterprise applications.
- Search for your application and select it.
- Go to Users and groups.
- Click Add user/group to assign users or groups to the Grafana roles.
- Return to Microsoft Entra ID, then navigate to App registrations. Search for your application and select it.
- Go to App roles and configure the roles as described in the Configure application roles for Grafana in the Azure portal.
- Configure Azure AD OAuth in the Grafana configuration file as described in Configure Azure AD authentication using the Grafana configuration file.
Forward token to users
To ensure user authentication tokens are securely forwarded to the Databricks data source, update your Grafana configuration file.
In your grafana.ini file, add or update the following setting:
[azure]
forward_settings_to_plugins = grafana-azure-monitor-datasource, prometheus, grafana-azure-data-explorer-datasource, mssql, grafana-databricks-datasourceThis setting allows Grafana to forward Azure authentication tokens to supported data sources, including Databricks.
After saving your configuration, return to the Grafana data source settings page and set Authentication type to OAuth Passthrough.
Azure On-behalf-of authentication
On-behalf-of authentication is only applicable to Azure Databricks clusters. It allows individual users to be authenticated using their own credentials via an App Registration configured in Azure with access to Databricks resources.
On-behalf-of authentication isn’t currently supported for private clouds (Azure China Cloud, Azure Government Cloud).
Warning
Avoid configuring alerts if your data source is configured to use on-behalf-of authentication. Alert rules cannot run because there is no user context available to provide credentials for the query.
To configure On-behalf-of authentication complete the following steps:
Configure Grafana to use OAuth2 with Microsoft Entra ID as documented. Ensure that the
[auth.azuread]scopes(or$GF_AUTH_AZUREAD_SCOPES) includes “openid email profile offline_access”.In the Azure Portal, go to App registrations → your application → Manage → Authentication. Enable ID tokens by selecting the corresponding checkbox.
In the Azure Portal, navigate to App registrations → your application → Manage → API permissions. Add the following permissions:
- Microsoft Graph:
User.Read - Azure Databricks:
user_impersonation
- Microsoft Graph:
In the Azure Portal, navigate to App registrations → your application → Security → Permissions. Enable Admin consent to grant consent on behalf of all users in the tenant. This prevents individual users from being prompted for consent when using the application.
When configuring the data source for an Azure Databricks cluster, navigate to your Databricks workspace: SQL Warehouses → Connection details → Server hostname and HTTP path.
Use these values when setting up the data source in Grafana.Use the Tenant ID, Client ID, and Client secret from the application registration you created in step 1.
Provision the data source
You can define and configure the data source in YAML files as part of the Grafana provisioning system. For general information about provisioning in Grafana, refer to Provision data sources.
Following is a provisioning example for the Databricks data source using basic authentication:
apiVersion: 1
datasources:
- name: Databricks
type: grafana-databricks-datasource
jsonData:
host: community.cloud.databricks.com
httpPath: path-from-databricks-odbc-settings
secureJsonData:
token: password/personal-tokenUse Terraform to configure the Databricks data source
You can automate the configuration of the Databricks data source in Grafana using Terraform.
terraform {
required_providers {
grafana = {
source = "grafana/grafana"
version = "~> 2.0"
}
}
}
provider "grafana" {
url = var.grafana_url
auth = var.grafana_auth
}
variable "grafana_url" {
description = "Grafana instance URL"
type = string
default = "http://localhost:3000"
}
variable "grafana_auth" {
description = "Grafana API key or service account token"
type = string
sensitive = true
}
variable "databricks_host" {
description = "Databricks workspace URL"
type = string
}
variable "databricks_token" {
description = "Databricks personal access token"
type = string
sensitive = true
}
variable "databricks_http_path" {
description = "HTTP path for Databricks SQL warehouse or cluster"
type = string
}
resource "grafana_data_source" "databricks" {
name = "Databricks"
type = "grafana-databricks-datasource"
json_data_encoded = jsonencode({
host = var.databricks_host
httpPath = var.databricks_http_path
})
secure_json_data_encoded = jsonencode({
token = var.databricks_token
})
# Optional: Set as default data source
is_default = false
# Optional: Basic auth settings if needed
basic_auth_enabled = false
}
output "datasource_id" {
description = "The ID of the created Databricks data source"
value = grafana_data_source.databricks.id
}
output "datasource_uid" {
description = "The UID of the created Databricks data source"
value = grafana_data_source.databricks.uid
}To deploy this configuration:
Create a terraform.tfvars file with your specific values:
hclgrafana_url = "https://your-grafana.com"
grafana_auth = "your-api-key"
databricks_host = "https://your-workspace.cloud.databricks.com"
databricks_token = "your-databricks-token"
databricks_http_path = "/sql/1.0/warehouses/your-warehouse-id"Initialize and apply the configuration:
bashterraform init
terraform plan
terraform applyThe configuration uses the Grafana Terraform provider to create the data source with secure storage of credentials. You can adjust the is_default setting to true if you want this to be your default data source in Grafana.


