
This is documentation for the next version of Grafana Mimir documentation. For the latest stable release, go to the latest version.
About ingest storage architecture
Ingest storage architecture uses Apache Kafka or a Kafka-compatible system as a central pipeline to decouple read and write operations, making Grafana Mimir more reliable and scalable.
Starting with Grafana Mimir 3.0, ingest storage architecture is stable and the preferred architecture for running Grafana Mimir.
Ingest storage architecture enhances reliability, supports growth, and enables larger-scale use cases, helping you to run more robust deployments of Grafana Mimir.
How ingest storage architecture works
Compared with classic architecture, ingest storage architecture fundamentally changes how Mimir handles data. In classic architecture, ingester nodes are highly stateful. They combine in-memory data with local write-ahead logs (WALs) and participate in both writes and reads. This can lead to heavy queries disrupting live writes.
Ingest storage architecture mitigates this issue by decoupling the read and write paths and reducing the statefulness of ingesters. It uses Kafka as a central data transfer pipeline between the write and read paths.
The following diagram shows how ingest storage architecture works:
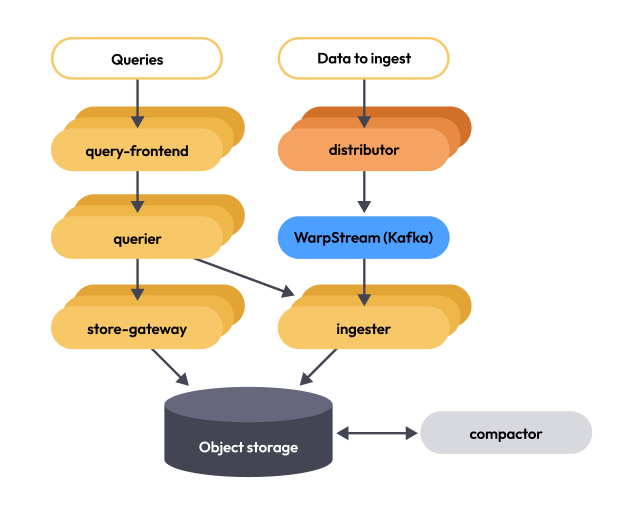
Here’s an overview of how ingest storage architecture works:
- Distributors receive write requests and validate them, apply transformations, and forward samples to the storage layer.
- Distributors connect to a Kafka topic and shard each write request across multiple partitions, briefly buffering requests before sending them to the Kafka broker.
- Kafka brokers persist the write requests durably and optionally replicate them to other brokers before acknowledging the write.
- Distributors acknowledge the write requests back to the client, for example, the OTel collector, after Kafka confirms persistence.
- Ingesters consume write requests from Kafka partitions continuously, with each ingester consuming from a single partition.
- Multiple ingesters across different zones consume from the same partition to provide high availability on the read path.
- Ingesters add the fetched write requests to in-memory state and persist them to disk, making the samples available for queries.
Benefits of ingest storage architecture
Ingest storage architecture offers the following advantages over classic architecture:
- Increased reliability and resilience in the event of sudden spikes in query traffic or ingest volume
- Decoupled read and write paths to prevent performance interference
Grafana Mimir components in ingest storage architecture
Most components are stateless and don’t require persistent data between restarts. Some components are stateful and rely on non-volatile storage to prevent data loss.
For details about each component, refer to Components.
The write path
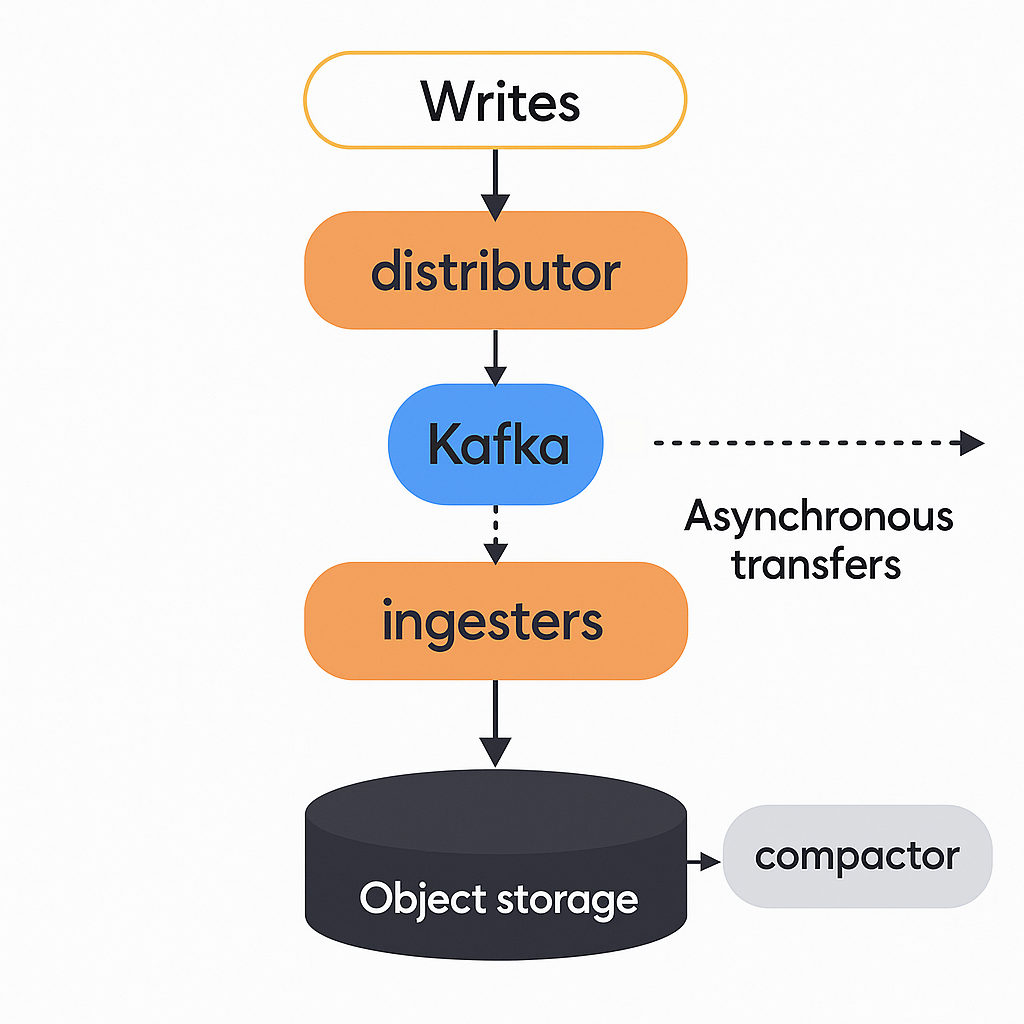
Distributors receive incoming samples in the form of push requests. Each push request belongs to a tenant, and distributors shard incoming push requests across multiple Kafka partitions within the same Kafka topic. Push requests succeed when Kafka brokers confirm that all records are replicated and persisted.
The ingest storage architecture write path ends at Kafka. This differs from classic architecture, where the write path includes ingesters and requires a quorum of ingesters for successful push requests.
Series sharding and replication
By default, Grafana Mimir shards each time series from a push request to a single Kafka partition. Time series from the same push request can fall into multiple partitions.
The Kafka cluster handles replication on the write path. Ingesters consume from partitions, and each ingester writes its own block to long-term storage.
The Compactor merges blocks from multiple ingesters into a single block and removes duplicate samples. This block compaction significantly reduces storage utilization.
For more information, refer to Compactor and Production tips.
The read path
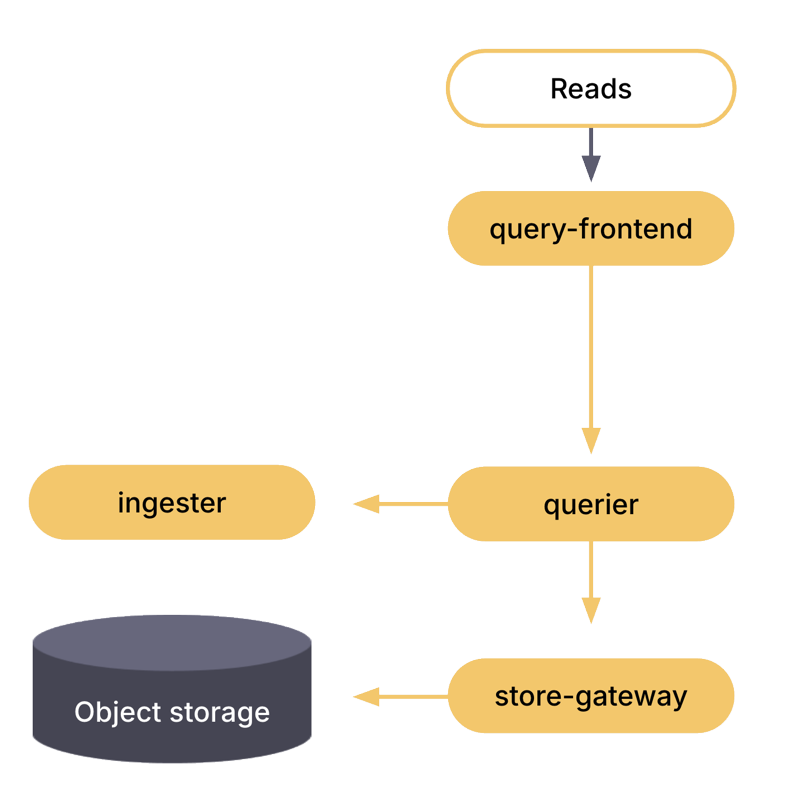
Distributors write samples to Kafka on the write path, and ingesters consume them on the read path. Each partition is assigned to a single ingester from each zone, and each ingester consumes from exactly one partition. Multiple ingester zones provide high availability on the read path.
Partition assignment from instance ID
Ingesters determine their partition assignment from their instance ID, which defaults to the system hostname.
Mimir extracts the partition number by matching the instance ID against the regular expression -([0-9]+)$.
This means the instance ID must end with a hyphen followed by a number.
For example:
- An ingester with instance ID
ingester-zone-a-13consumes from partition 13. - An ingester with instance ID
mimir-write-zone-b-7consumes from partition 7. - An ingester with instance ID
ingester-0consumes from partition 0.
Warning
If the instance ID doesn’t match the required pattern, the ingester fails to start with an error like:
ingester ID <id> doesn't match regular expression "-([0-9]+)$".This can happen in environments where the system hostname returns a fully qualified domain name (FQDN), such as
ingester-zone-a-0.ingester.mimir.svc.cluster.local. In such cases, you must explicitly set the-ingester.ring.instance-idflag to a value that ends with a hyphen followed by the partition number (for example,-ingester.ring.instance-id=ingester-zone-a-0).
Each ingester persists the partition offset up to which it has consumed records in a dedicated Kafka consumer group.
Ingesters continuously consume samples from Kafka and append them to the tenant-specific time series database (TSDB) stored on the local disk. The tenant-specific TSDB is created when the first samples arrive for that tenant. The samples that are received are both kept in-memory and written to a write-ahead log (WAL). If the ingester abruptly terminates, the WAL can help to recover the in-memory series. After the ingester recovers from the downtime and has replayed the local WAL, it resumes consuming from Kafka from the offset stored in its consumer group. Using this technique, the ingester never misses a sample written to Kafka and observes samples in the same order as other ingesters consuming the same partition.
The in-memory samples are periodically flushed to disk, and the WAL is truncated when a new TSDB block is created.
By default, this occurs every two hours.
Each newly created block is uploaded to long-term storage but kept in the ingester until the configured -blocks-storage.tsdb.retention-period expires.
This gives queriers and store-gateways enough time to discover the new block and download its index-header.
To effectively use the WAL and recover in-memory series after abrupt termination, store the WAL on a persistent disk that survives ingester failure.
For cloud deployments, use an AWS EBS volume or a GCP Persistent Disk. For Kubernetes deployments, use a StatefulSet with a persistent volume claim for the ingesters.
The WAL and local TSDB blocks share the same filesystem location and can’t be stored separately.
For more information, refer to timeline of block uploads and Ingester.
The lifecycle of a query
Queries coming into Grafana Mimir arrive at the query-frontend. The query-frontend then splits queries over longer time ranges into multiple, smaller queries.
The query-frontend next checks the results cache. If the result of a query has been cached, the query-frontend returns the cached results. Queries that cannot be answered from the results cache are put into an in-memory queue within the query-frontend.
Note
If you run the optional query-scheduler component, the query-schedule maintains the queue instead of the query-frontend.
For queries requiring strong read consistency, with the X-Read-Consistency: strong HTTP header, the query-frontend retrieves the offsets of each partition from the Kafka topic and propagates it through the read path to ingesters. For more information, refer to Data freshness on the read path.
The queriers act as workers, pulling queries from the queue.
The queriers connect to the store-gateways and the ingesters to fetch all the data needed to execute a query. For more information about how the query is executed, refer to querier.
After the querier executes the query, it returns the results to the query-frontend for aggregation. The query-frontend then returns the aggregated results to the client.
Data freshness on the read path
Ingesters consume from Kafka asynchronously while serving queries. By default, ingesters don’t ensure that samples written to Kafka are appended to the in-memory TSDB and on-disk WAL before receiving a query. This allows ingesters to withstand Kafka outages without rejecting queries. The impact of Kafka outages is that queries that ingesters serve may return stale data and don’t provide a read-after-write guarantee.
During normal operations, the delay in ingesting data in ingesters should be below 1 second. This is also known as the end-to-end latency of ingestion.
While this latency is usually insignificant for interactive queries, it can challenge applications that need queries to observe all previous writes. For example, the Mimir ruler needs samples from earlier rules in a rule group to be available when evaluating later rules in the same group.
To preserve the read-after-write guarantee, clients can add the X-Read-Consistency: strong HTTP header to queries. The ruler automatically adds this header for rules that depend on the results of previous rules within the same rule group. When a query includes this header, the query-frontend fetches the latest offsets from Kafka for all active partitions and propagates these offsets to ingesters. Each ingester waits until it has consumed up to the specified offset for its partition before running the query. This ensures the query observes all samples written to Kafka before the query-frontend received the query, providing strong read consistency at the cost of increased query latency.
By default, the ingester waits up to 20 seconds for the record to be consumed before rejecting the strong read consistency query.
Kafka
Kafka is a central part of ingest storage architecture. It’s responsible for replicating and durably persisting incoming data and for making this data available to ingesters.
The use of the Kafka protocol is limited in Grafana Mimir. This allows you to use many Kafka-compatible solutions.
How Mimir uses Kafka
On the write path, the distributor requires the Kafka cluster to be available for push requests to succeed. The distributor issues direct Produce API calls to the Kafka brokers and doesn’t produce in transactions or need support for idempotent writes.
Both the ingester and the distributor use the Metadata API to discover the leaders for a topic-partition.
The Mimir ingester uses Kafka consumer groups to persist how far an ingester has consumed from its assigned partition. Each ingester maintains its own consumer group. Each Kafka record is consumed at least once by each ingester zone. Records usually aren’t replayed after being consumed, unless the ingester abruptly shuts down before managing to commit to its consumer group.
For more information, refer to Message delivery semantics in the Apache Kafka documentation.
The following exceptions exist:
- Abrupt termination: When an ingester terminates abruptly without persisting its offset in the consumer group, the ingester resumes from where the consumer group offset points.
- Manual configuration: You can configure ingesters to start consuming from the earliest offset, the latest offset, or a specific timestamp of the Kafka topic-partition using the
-ingest-storage.kafka.consume-from-position-at-startupand-ingest-storage.kafka.consume-from-timestamp-at-startupflags. In these cases, the ingester uses the ListOffsets API to discover the target offset.

