
Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Provisioning Grafana
In previous versions of Grafana, you could only use the API for provisioning data sources and dashboards. But that required the service to be running before you started creating dashboards and you also needed to set up credentials for the HTTP API. In v5.0 we decided to improve this experience by adding a new active provisioning system that uses config files. This will make GitOps more natural as data sources and dashboards can be defined via files that can be version controlled. We hope to extend this system to later add support for users, orgs and alerts as well.
Config File
Checkout the configuration page for more information on what you can configure in grafana.ini
Config File Locations
- Default configuration from
$WORKING_DIR/conf/defaults.ini - Custom configuration from
$WORKING_DIR/conf/custom.ini - The custom configuration file path can be overridden using the
--configparameter
Note. If you have installed Grafana using the
deborrpmpackages, then your configuration file is located at/etc/grafana/grafana.ini. This path is specified in the Grafana init.d script using--configfile parameter.
Using Environment Variables
All options in the configuration file (listed below) can be overridden using environment variables using the syntax:
GF_<SectionName>_<KeyName>Where the section name is the text within the brackets. Everything
should be upper case and . should be replaced by _. For example, given these configuration settings:
# default section
instance_name = ${HOSTNAME}
[security]
admin_user = admin
[auth.google]
client_secret = 0ldS3cretKeyOverriding will be done like so:
export GF_DEFAULT_INSTANCE_NAME=my-instance
export GF_SECURITY_ADMIN_USER=true
export GF_AUTH_GOOGLE_CLIENT_SECRET=newS3cretKeyConfiguration Management Tools
Currently we do not provide any scripts/manifests for configuring Grafana. Rather than spending time learning and creating scripts/manifests for each tool, we think our time is better spent making Grafana easier to provision. Therefore, we heavily relay on the expertise of the community.
Datasources
This feature is available from v5.0
It’s possible to manage datasources in Grafana by adding one or more yaml config files in the provisioning/datasources directory. Each config file can contain a list of datasources that will be added or updated during start up. If the datasource already exists, Grafana will update it to match the configuration file. The config file can also contain a list of datasources that should be deleted. That list is called deleteDatasources. Grafana will delete datasources listed in deleteDatasources before inserting/updating those in the datasource list.
Running Multiple Grafana Instances
If you are running multiple instances of Grafana you might run into problems if they have different versions of the datasource.yaml configuration file. The best way to solve this problem is to add a version number to each datasource in the configuration and increase it when you update the config. Grafana will only update datasources with the same or lower version number than specified in the config. That way, old configs cannot overwrite newer configs if they restart at the same time.
Example Datasource Config File
# config file version
apiVersion: 1
# list of datasources that should be deleted from the database
deleteDatasources:
- name: Graphite
orgId: 1
# list of datasources to insert/update depending
# what's available in the database
datasources:
# <string, required> name of the datasource. Required
- name: Graphite
# <string, required> datasource type. Required
type: graphite
# <string, required> access mode. proxy or direct (Server or Browser in the UI). Required
access: proxy
# <int> org id. will default to orgId 1 if not specified
orgId: 1
# <string> url
url: http://localhost:8080
# <string> database password, if used
password:
# <string> database user, if used
user:
# <string> database name, if used
database:
# <bool> enable/disable basic auth
basicAuth:
# <string> basic auth username
basicAuthUser:
# <string> basic auth password
basicAuthPassword:
# <bool> enable/disable with credentials headers
withCredentials:
# <bool> mark as default datasource. Max one per org
isDefault:
# <map> fields that will be converted to json and stored in jsonData
jsonData:
graphiteVersion: "1.1"
tlsAuth: true
tlsAuthWithCACert: true
# <string> json object of data that will be encrypted.
secureJsonData:
tlsCACert: "..."
tlsClientCert: "..."
tlsClientKey: "..."
version: 1
# <bool> allow users to edit datasources from the UI.
editable: falseCustom Settings per Datasource
Please refer to each datasource documentation for specific provisioning examples.
Json Data
Since not all datasources have the same configuration settings we only have the most common ones as fields. The rest should be stored as a json blob in the jsonData field. Here are the most common settings that the core datasources use.
Secure Json Data
{"authType":"keys","defaultRegion":"us-west-2","timeField":"@timestamp"}
Secure json data is a map of settings that will be encrypted with secret key from the Grafana config. The purpose of this is only to hide content from the users of the application. This should be used for storing TLS Cert and password that Grafana will append to the request on the server side. All of these settings are optional.
Dashboards
It’s possible to manage dashboards in Grafana by adding one or more yaml config files in the provisioning/dashboards directory. Each config file can contain a list of dashboards providers that will load dashboards into Grafana from the local filesystem.
The dashboard provider config file looks somewhat like this:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
updateIntervalSeconds: 10 #how often Grafana will scan for changed dashboards
options:
path: /var/lib/grafana/dashboardsWhen Grafana starts, it will update/insert all dashboards available in the configured path. Then later on poll that path and look for updated json files and insert those update/insert those into the database.
Making changes to a provisioned dashboard
It’s possible to make changes to a provisioned dashboard in Grafana UI, but there’s currently no possibility to automatically save the changes back to the provisioning source.
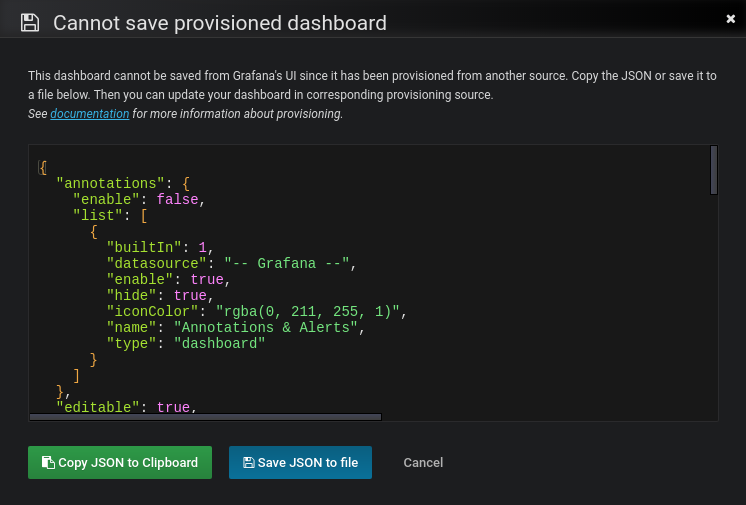
However, if you make changes to a provisioned dashboard you can Save the dashboard which will bring up a Cannot save provisioned dashboard dialog like seen in the screenshot below.
Here available options will let you Copy JSON to Clipboard and/or Save JSON to file which can help you synchronize your dashboard changes back to the provisioning source.
Note: The JSON shown in input field and when using Copy JSON to Clipboard and/or Save JSON to file will have the id field automatically removed to aid the provisioning workflow.
Reusable Dashboard Urls
If the dashboard in the json file contains an uid, Grafana will force insert/update on that uid. This allows you to migrate dashboards betweens Grafana instances and provisioning Grafana from configuration without breaking the urls given since the new dashboard url uses the uid as identifier.
When Grafana starts, it will update/insert all dashboards available in the configured folders. If you modify the file, the dashboard will also be updated.
By default Grafana will delete dashboards in the database if the file is removed. You can disable this behavior using the disableDeletion setting.
Note. Provisioning allows you to overwrite existing dashboards which leads to problems if you re-use settings that are supposed to be unique. Be careful not to re-use the same
titlemultiple times within a folder oruidwithin the same installation as this will cause weird behaviours.


