
Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Heatmap Panel

New panel only available in Grafana v4.3+
The Heatmap panel allows you to view histograms over time. To fully understand and use this panel you need understand what Histograms are and how they are created. Read on below to for a quick introduction to the term Histogram.
Histograms and buckets
A histogram is a graphical representation of the distribution of numerical data. You group values into buckets (some times also called bins) and then count how many values fall into each bucket. Instead of graphing the actual values you then graph the buckets. Each bar represents a bucket and the bar height represents the frequency (i.e. count) of values that fell into that bucket’s interval.
Example Histogram:
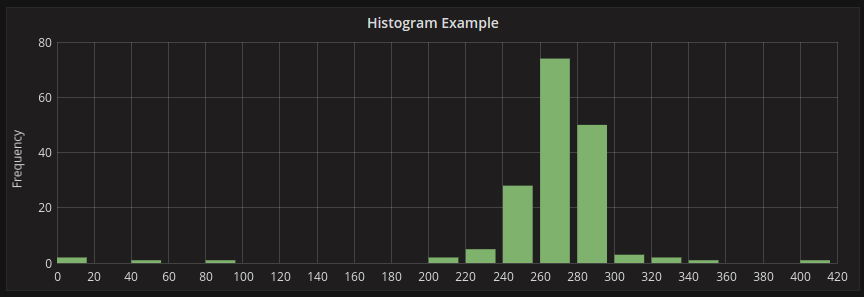
The above histogram shows us that most value distribution of a couple of time series. We can easily see that most values land between 240-300 with a peak between 260-280. Histograms just look at value distributions over specific time range. So you cannot see any trend or changes in the distribution over time, this is where heatmaps become useful.
Heatmap
A Heatmap is like a histogram but over time where each time slice represents its own histogram. Instead of using bar height as a representation of frequency you use cells and color the cell proportional to the number of values in the bucket.
Example:
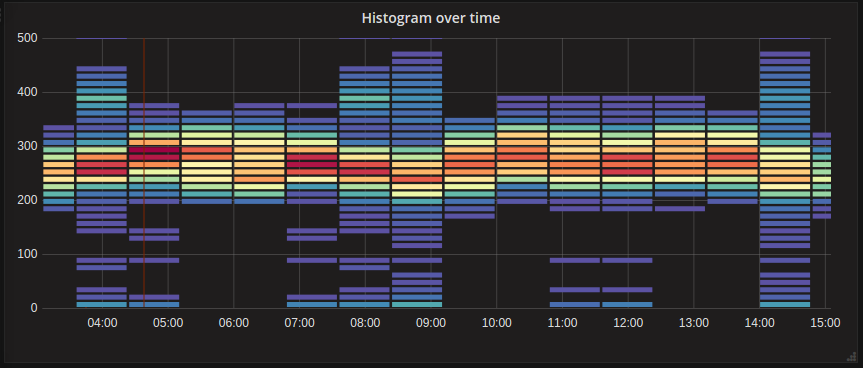
Here we can clearly see what values are more common and how they trend over time.
Data Options
Data and bucket options can be found in the Axes tab.
Data Formats
Bucket bound
When Data format is Time series buckets datasource returns series with names representing bucket bound. But depending on datasource, a bound may be upper or lower. This option allows to adjust a bound type. If Auto is set, a bound option will be chosen based on panels’ datasource type.
Bucket Size
The Bucket count & size options are used by Grafana to calculate how big each cell in the heatmap is. You can
define the bucket size either by count (the first input box) or by specifying a size interval. For the Y-Axis
the size interval is just a value but for the X-bucket you can specify a time range in the Size input, for example,
the time range 1h. This will make the cells 1h wide on the X-axis.
Pre-bucketed data
If you have a data that is already organized into buckets you can use the Time series buckets data format. This format
requires that your metric query return regular time series and that each time series has a numeric name that represent
the upper or lower bound of the interval.
There are a number of datasources supporting histogram over time like Elasticsearch (by using a Histogram bucket aggregation) or Prometheus (with histogram metric type and Format as option set to Heatmap). But generally, any datasource could be used if it meets the requirements: returns series with names representing bucket bound or returns sereis sorted by the bound in ascending order.
With Elasticsearch you control the size of the buckets using the Histogram interval (Y-Axis) and the Date Histogram interval (X-axis).

With Prometheus you can only control X-axis by adjusting Min step and Resolution options.

Display Options
In the heatmap Display tab you define how the cells are rendered and what color they are assigned.
Color Mode & Spectrum

The color spectrum controls the mapping between value count (in each bucket) and the color assigned to each bucket. The left most color on the spectrum represents the minimum count and the color on the right most side represents the maximum count. Some color schemes are automatically inverted when using the light theme.
You can also change the color mode to Opacity. In this case, the color will not change but the amount of opacity will
change with the bucket count.
Raw data vs aggregated
If you use the heatmap with regular time series data (not pre-bucketed). Then it’s important to keep in mind that your data is often already by aggregated by your time series backend. Most time series queries do not return raw sample data but include a group by time interval or maxDataPoints limit coupled with an aggregation function (usually average).
This all depends on the time range of your query of course. But the important point is to know that the Histogram bucketing that Grafana performs may be done on already aggregated and averaged data. To get more accurate heatmaps it is better to do the bucketing during metric collection or store the data in Elasticsearch, or in the other data source which supports doing Histogram bucketing on the raw data.
If you remove or lower the group by time (or raise maxDataPoints) in your query to return more data points your heatmap will be more accurate but this can also be very CPU & Memory taxing for your browser and could cause hangs and crashes if the number of data points becomes unreasonably large.


