Introduction to Adaptive Traces
Learn more about the fundamentals and available features that help you optimize your use of Adaptive Traces.
How it works at a glance
The following diagram gives you an overview of Adaptive Traces and introduces you to some of the fundamental features that are the principles of how Adaptive Traces works.
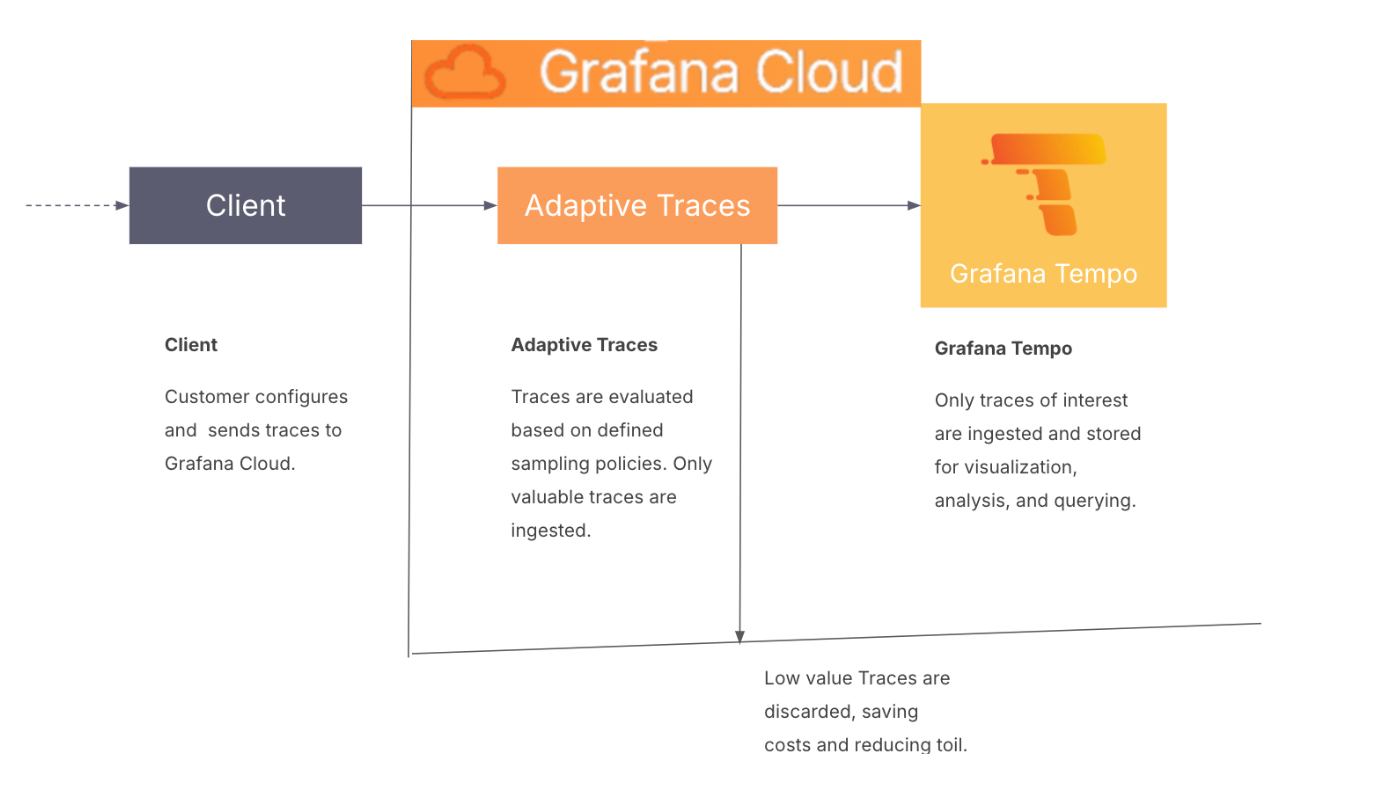
- Adaptive Traces performs what’s referred to as tail sampling, where the decision to sample a trace takes place by considering all or most of the spans within the trace. This sampling method gives you the option to filter your traces based on specific criteria.
- Sampling policies define a set of criteria that evaluates traces and decides which to keep (sample) or not keep (not sampled, or drop).
- Each policy has a type which specifies what information (for example, latency, string attribute) or condition (for example, percentage) is used for evaluation.
Unlike Adaptive Metrics or Adaptive Logs, Adaptive Traces does not currently use query usage as an input in recommendations.
Fundamentals
The following concepts are key to your understanding of how Adaptive Traces works.
Tail sampling
Tail sampling is a technique that delays a sampling decision until enough information about a trace is available. This allows Adaptive Traces to make informed decisions based on trace characteristics such as errors, latency, or attributes.
Adaptive Traces uses a two-stage decision process:
- If a root span is received, Adaptive Traces makes a sampling decision 2 seconds after the root span arrives. This short delay allows slower child spans to be ingested while enabling faster sampling decisions for most traces.
- If no root span is received, Adaptive Traces waits up to 30 seconds before making a sampling decision. This ensures that long-running or delayed traces still have a chance to be evaluated accurately.
This approach improves sampling accuracy for slow traces while allowing the majority of traces to be sampled quickly.
For more information on sampling in general, refer to the Open Telemetry documentation and Sampling documentation.
Recommendation
A recommendation is a suggestion, derived from our best practices and analyzing your trace data, to implement a sampling policy, helping you fine-tune your trace sampling and ensuring you only capture what’s critical and worthy of your attention.
Each recommendation contains a recommended policy; a set of criteria that evaluates traces and decides which to keep (sample) or not keep (not sampled, or drop).
Recommendations typically aim to:
- Sample slow traces: Recommend policies to capture traces that exceed a certain duration (for example, 10 seconds or more), identifying latency issues.
- Sample traces with errors: Recommend policies to sample traces containing spans with an
Errorstatus code, helping to quickly pinpoint and investigate failures. - Sample (keep) a percentage of all traces: Advise on policies to retain a representative sample of all traces (for example, 5%), useful for general trace comparison and maintaining a service graph without excessive data volume.
Review and manage recommendations using the UI and indicate which recommendations you want to apply.
After you have applied recommendations, a policy is created with the recommended type and content.
Policy
Policies define a set of criteria that evaluates traces and decides which to keep (sample) or not keep (not sampled, or drop). Some policies can contain sub-policies to build more advanced logic. Policies also have an optional expiration date.
Policies work in an or relationship by default. This means that if a trace matches the criteria of any of the defined policies, it is sampled.
Example
Imagine you have three policies.
- Capture traces with errors.
- Capture traces with latency over 500ms.
- Capture traces from a specific service.
A trace is sampled if it has an error, OR if it has high latency, OR if it comes from the specified service. It doesn’t need to meet all the conditions.
Policy type
Each policy has a type which specifies what information (for example, latency, string attribute) or condition (for example, percentage) is used for evaluation.
For more information on policy types, refer to Policy types.


