This is documentation for the next version of Grafana Alloy Documentation. For the latest stable release, go to the latest version.
prometheus.exporter.cloudwatch
The prometheus.exporter.cloudwatch component embeds yet-another-cloudwatch-exporter, letting you collect Amazon CloudWatch metrics in a Prometheus-compatible format.
This component lets you scrape CloudWatch metrics in a set of configurations called jobs. There are two kinds of jobs: [discovery][] and [static][].
Authentication
Alloy must be running in an environment with access to AWS. The exporter uses the AWS SDK for Go and provides authentication via the AWS default credential chain. Regardless of the method used to acquire the credentials, some permissions are required for the exporter to work.
"tag:GetResources",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics"The following IAM permissions are required for the Transit Gateway attachment (tgwa) metrics to work.
"ec2:DescribeTags",
"ec2:DescribeInstances",
"ec2:DescribeRegions",
"ec2:DescribeTransitGateway*"The following IAM permission is required to discover tagged API Gateway REST APIs:
"apigateway:GET"The following IAM permissions are required to discover tagged Database Migration Service (DMS) replication instances and tasks:
"dms:DescribeReplicationInstances",
"dms:DescribeReplicationTasks"To use all of the integration features, use the following AWS IAM Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1674249227793",
"Action": [
"tag:GetResources",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"ec2:DescribeTags",
"ec2:DescribeInstances",
"ec2:DescribeRegions",
"ec2:DescribeTransitGateway*",
"apigateway:GET",
"dms:DescribeReplicationInstances",
"dms:DescribeReplicationTasks"
],
"Effect": "Allow",
"Resource": "*"
}
]
}Usage
prometheus.exporter.cloudwatch "queues" {
sts_region = "us-east-2"
discovery {
type = "AWS/SQS"
regions = ["us-east-2"]
search_tags = {
"scrape" = "true",
}
metric {
name = "NumberOfMessagesSent"
statistics = ["Sum", "Average"]
period = "1m"
}
metric {
name = "NumberOfMessagesReceived"
statistics = ["Sum", "Average"]
period = "1m"
}
}
}Arguments
You can use the following arguments with prometheus.exporter.cloudwatch:
If you define the ["name", "type"] under "AWS/EC2" in the discovery_exported_tags argument, it exports the name and type tags and its values as labels in all metrics.
This affects all discovery jobs.
Caution
Starting with Alloy v1.16, the
aws_sdk_version_v2argument is deprecated and has no effect. AWS SDK for Go v2 is always used.
Remove this argument from your configuration. The argument will be removed in a future release.
Blocks
You can use the following blocks with prometheus.exporter.cloudwatch:
No valid configuration blocks found.
Note
The
static,discovery, andcustom_namespaceblocks are marked as not required, but you must configure at least onestatic,discovery, orcustom_namespacejob.
discovery
The discovery block allows the component to scrape CloudWatch metrics with only the AWS service and a list of metrics under that service/namespace.
Alloy finds AWS resources in the specified service, scrapes the metrics, labels them appropriately, and exports them to Prometheus.
The following example configuration, shows you how to scrape CPU utilization and network traffic metrics from all AWS EC2 instances:
prometheus.exporter.cloudwatch "discover_instances" {
sts_region = "us-east-2"
discovery {
type = "AWS/EC2"
regions = ["us-east-2"]
metric {
name = "CPUUtilization"
statistics = ["Average"]
period = "5m"
}
metric {
name = "NetworkPacketsIn"
statistics = ["Average"]
period = "5m"
}
}
}You can configure the discovery block one or multiple times to scrape metrics from different services or with different search_tags.
static
The static block configures the component to scrape a specific set of CloudWatch metrics.
The metrics need to be fully qualified with the following specifications:
namespace: For example,AWS/EC2,AWS/EBS,CoolAppif it were a custom metric, etc.dimensions: CloudWatch identifies a metric by a set of dimensions, which are essentially label / value pairs. For example, allAWS/EC2metrics are identified by theInstanceIddimension and the identifier itself.metric: Metric name and statistics.
The following example configuration shows you how to scrape the same metrics in the discovery example, but for a specific AWS EC2 instance:
prometheus.exporter.cloudwatch "static_instances" {
sts_region = "us-east-2"
static "instances" {
regions = ["us-east-2"]
namespace = "AWS/EC2"
dimensions = {
"InstanceId" = "i01u29u12ue1u2c",
}
metric {
name = "CPUUsage"
statistics = ["Sum", "Average"]
period = "1m"
}
}
}As shown above, static blocks must be specified with a label, which translates to the name label in the exported metric.
static "<LABEL>" {
regions = ["us-east-2"]
namespace = "AWS/EC2"
// ...
}You can configure the static block one or multiple times to scrape metrics with different sets of dimensions.
All dimensions must be specified when scraping single metrics like the example above.
For example, AWS/Logs metrics require Resource, Service, Class, and Type dimensions to be specified.
The same applies to CloudWatch custom metrics, all dimensions attached to a metric when saved in CloudWatch are required.
custom_namespace
The custom_namespace block allows the component to scrape CloudWatch metrics from custom namespaces using only the namespace name and a list of metrics under that namespace.
For example:
prometheus.exporter.cloudwatch "discover_instances" {
sts_region = "eu-west-1"
custom_namespace "customEC2Metrics" {
namespace = "CustomEC2Metrics"
regions = ["us-east-1"]
metric {
name = "cpu_usage_idle"
statistics = ["Average"]
period = "5m"
}
metric {
name = "disk_free"
statistics = ["Average"]
period = "5m"
}
}
}You can configure the custom_namespace block multiple times to scrape metrics from different namespaces.
metric
RequiredRepresents an AWS Metric to scrape.
The metric block may be specified multiple times to define multiple target metrics.
Refer to the View available metrics topic in the Amazon CloudWatch documentation for detailed metrics information.
period and length
period controls primarily the width of the time bucket used for aggregating metrics collected from CloudWatch.
length controls how far back in time CloudWatch metrics are considered during each Alloy scrape.
If both settings are configured, the time parameters when calling CloudWatch APIs works as follows:
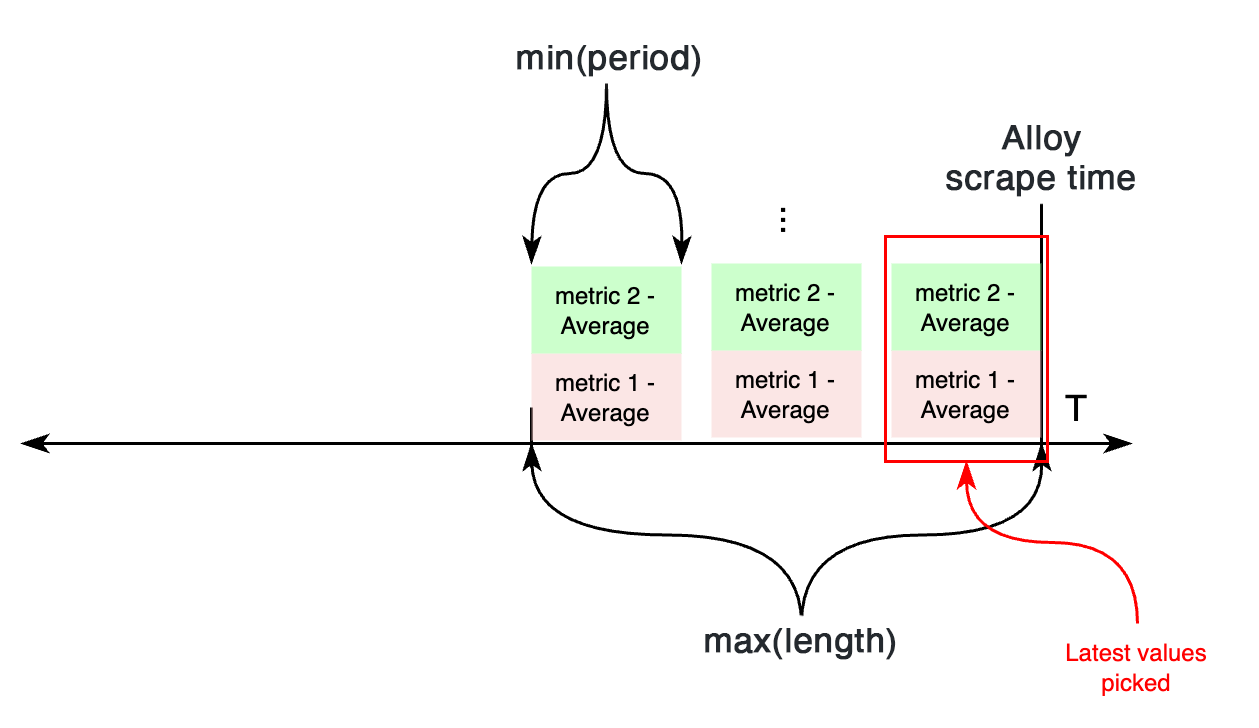
If, across multiple metrics under the same static or discovery job, there’s a different period or length, the minimum of all periods, and maximum of all lengths is configured.
On the other hand, if length isn’t configured, both period and length settings are calculated based on the required period configuration attribute.
If all metrics within a job (discovery or static) have the same period value configured, CloudWatch APIs are requested for metrics from the scrape time, to period seconds in the past.
The values of these are exported to Prometheus.

On the other hand, if metrics with different periods are configured under an individual job, this works differently.
First, two variables are calculated aggregating all periods: length, taking the maximum value of all periods, and the new period value, taking the minimum of all periods.
Then, CloudWatch APIs are requested for metrics from now - length to now, aggregating each in samples for period seconds. For each metric, the most recent sample is exported to CloudWatch.

role
Represents an AWS IAM Role. If omitted, the AWS role that corresponds to the credentials configured in the environment is used.
Multiple roles can be useful when scraping metrics from different AWS accounts with a single pair of credentials. In this case, a different role is configured for Alloy to assume before calling AWS APIs. Therefore, the credentials configured in the system need permission to assume the target role. Refer to Granting a user permissions to switch roles in the AWS IAM documentation for more information about how to configure this.
decoupled_scraping
The decoupled_scraping block configures an optional feature that scrapes CloudWatch metrics in the background on a scheduled interval.
When this feature is enabled, CloudWatch metrics are gathered asynchronously at the scheduled interval instead of synchronously when the CloudWatch component is scraped.
The decoupled scraping feature reduces the number of API requests sent to AWS. This feature also prevents component scrape timeouts when you gather high volumes of CloudWatch metrics.
Exported fields
The following fields are exported and can be referenced by other components.
For example, the targets can either be passed to a discovery.relabel component to rewrite the targets’ label sets or to a prometheus.scrape component that collects the exposed metrics.
The exported targets use the configured in-memory traffic address specified by the run command.
Component health
prometheus.exporter.cloudwatch is only reported as unhealthy if given an invalid configuration.
In those cases, exported fields retain their last healthy values.
Debug information
prometheus.exporter.cloudwatch doesn’t expose any component-specific debug information.
Debug metrics
prometheus.exporter.cloudwatch doesn’t expose any component-specific debug metrics.
Example
For detailed examples, refer to the [discovery][] and [static] sections.
Supported services in discovery jobs
The following AWS services are supported in cloudwatch_exporter discovery jobs.
When you configure a discovery job, make sure the type field of each discovery_job matches the desired job namespace.
- Namespace:
/aws/sagemaker/Endpoints - Namespace:
/aws/sagemaker/InferenceRecommendationsJobs - Namespace:
/aws/sagemaker/ProcessingJobs - Namespace:
/aws/sagemaker/TrainingJobs - Namespace:
/aws/sagemaker/TransformJobs - Namespace:
AmazonMWAA - Namespace:
AWS/ACMPrivateCA - Namespace:
AWS/AmazonMQ - Namespace:
AWS/AOSS - Namespace:
AWS/ApiGateway - Namespace:
AWS/ApplicationELB - Namespace:
AWS/AppRunner - Namespace:
AWS/AppStream - Namespace:
AWS/AppSync - Namespace:
AWS/Athena - Namespace:
AWS/AutoScaling - Namespace:
AWS/Backup - Namespace:
AWS/Bedrock - Namespace:
AWS/Billing - Namespace:
AWS/Cassandra - Namespace:
AWS/CertificateManager - Namespace:
AWS/ClientVPN - Namespace:
AWS/CloudFront - Namespace:
AWS/Cognito - Namespace:
AWS/DataSync - Namespace:
AWS/DDoSProtection - Namespace:
AWS/DMS - Namespace:
AWS/DocDB - Namespace:
AWS/DX - Namespace:
AWS/DynamoDB - Namespace:
AWS/EBS - Namespace:
AWS/EC2 - Namespace:
AWS/EC2CapacityReservations - Namespace:
AWS/EC2Spot - Namespace:
AWS/ECR - Namespace:
AWS/ECS - Namespace:
AWS/EFS - Namespace:
AWS/ElastiCache - Namespace:
AWS/ElasticBeanstalk - Namespace:
AWS/ElasticMapReduce - Namespace:
AWS/ELB - Namespace:
AWS/EMRServerless - Namespace:
AWS/ES - Namespace:
AWS/Events - Namespace:
AWS/Firehose - Namespace:
AWS/FSx - Namespace:
AWS/GameLift - Namespace:
AWS/GatewayELB - Namespace:
AWS/GlobalAccelerator - Namespace:
AWS/IoT - Namespace:
AWS/IPAM - Namespace:
AWS/Kafka - Namespace:
AWS/KafkaConnect - Namespace:
AWS/Kinesis - Namespace:
AWS/KinesisAnalytics - Namespace:
AWS/KMS - Namespace:
AWS/Lambda - Namespace:
AWS/Logs - Namespace:
AWS/MediaConnect - Namespace:
AWS/MediaConvert - Namespace:
AWS/MediaLive - Namespace:
AWS/MediaPackage - Namespace:
AWS/MediaTailor - Namespace:
AWS/MemoryDB - Namespace:
AWS/MWAA - Namespace:
AWS/NATGateway - Namespace:
AWS/Neptune - Namespace:
AWS/Network Manager - Namespace:
AWS/NetworkELB - Namespace:
AWS/NetworkFirewall - Namespace:
AWS/PrivateLinkEndpoints - Namespace:
AWS/PrivateLinkServices - Namespace:
AWS/Prometheus - Namespace:
AWS/QLDB - Namespace:
AWS/QuickSight - Namespace:
AWS/RDS - Namespace:
AWS/Redshift - Namespace:
AWS/Route53 - Namespace:
AWS/Route53Resolver - Namespace:
AWS/RUM - Namespace:
AWS/S3 - Namespace:
AWS/SageMaker - Namespace:
AWS/Sagemaker/ModelBuildingPipeline - Namespace:
AWS/Scheduler - Namespace:
AWS/SecretsManager - Namespace:
AWS/SES - Namespace:
AWS/SNS - Namespace:
AWS/SQS - Namespace:
AWS/States - Namespace:
AWS/StorageGateway - Namespace:
AWS/Timestream - Namespace:
AWS/TransitGateway - Namespace:
AWS/TrustedAdvisor - Namespace:
AWS/Usage - Namespace:
AWS/VpcLattice - Namespace:
AWS/VPN - Namespace:
AWS/WAFV2 - Namespace:
AWS/WorkSpaces - Namespace:
ContainerInsights - Namespace:
CWAgent - Namespace:
ECS/ContainerInsights - Namespace:
Glue
Compatible components
prometheus.exporter.cloudwatch has exports that can be consumed by the following components:
- Components that consume Targets
Note
Connecting some components may not be sensible or components may require further configuration to make the connection work correctly. Refer to the linked documentation for more details.


