How shuffle sharding in Cortex leads to better scalability and more isolation for Prometheus
For many years, it has been possible to scale Cortex clusters to hundreds of replicas. The relatively simple Dynamo-style replication relies on quorum consistency for reads and writes. But as such, more than a single replica failure can lead to an outage for all tenants. Shuffle sharding solves that issue by automatically picking a random “replica set” for each tenant, allowing you to isolate tenants and reduce the chance of an outage.
In this blog post, we do a deep dive into how shuffle sharding in Cortex achieves better scalability and more isolation for Prometheus, both in theory and in practice. We will also walk through the design on both the read and write path of Cortex, as I did at KubeCon + CloudNativeCon Europe last week.
But first, let’s take a look at Cortex and its ability to centralize your observability in a single cluster and also review how load distribution worked before implementing shuffle sharding.
Scalability with Cortex
Five years ago, we started looking for a different way of running Prometheus at scale. This is when we built Cortex. Cortex replaces the need for a global federation server with a centralized architecture that allows all your edge locations to push all their raw samples directly to one horizontally scalable Cortex cluster.
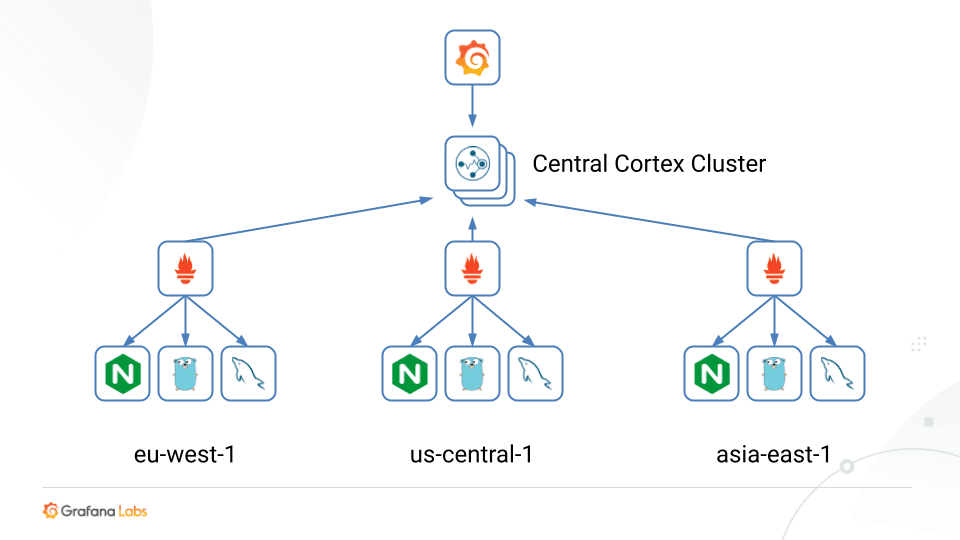
This is good for two reasons:
- This is push, not pull. In many ways, this is more sympathetic towards how a lot of organizations have their networks organized and simplifies the process of opening up and securing your monitoring stack.
- The Cortex cluster is scalable. As you add more clusters or more metrics in individual locations, you can scale up the Cortex cluster to take all the raw data. That also translates into easier ad hoc queries because you’ve got all the data that you can drill down within the central Cortex cluster.
Also because Cortex centralizes your data, there’s now one place to add additional features such as long-term storage, to invest in query performance, and to encourage your users to go to for all their answers.
Cortex is not only horizontally scalable. It’s also highly available. We replicate data in Cortex between nodes, which means that if a node fails, there will not be any gaps in your graphs.
Finally, one of the things that makes Cortex quite different compared to a lot of systems is that, from day one, it was built to be multi-tenant and support different isolated tenants on the same cluster. So if you’re an internal observability team providing a service to the rest of your organization, Cortex is really easy to deploy, and you can add lots of different isolated teams within your organization without having to spin up a separate cluster per team.
Cortex in a nutshell is a time series database that uses the same storage engine and query engine as Prometheus. All we’ve done in Cortex is add the distributed systems glue to turn those single node solutions into something that works in a horizontally scalable, clustered fashion.
What is shuffle sharding?
First things first: We did not invent shuffle sharding.
I was introduced to the concept of shuffle sharding thanks to an article in Amazon’s builders’ library about how they improved the isolation in Route 53’s DNS service using this technique. The article got passed around internally at Grafana Labs, and we thought this would be a really interesting piece of work to do on Cortex.
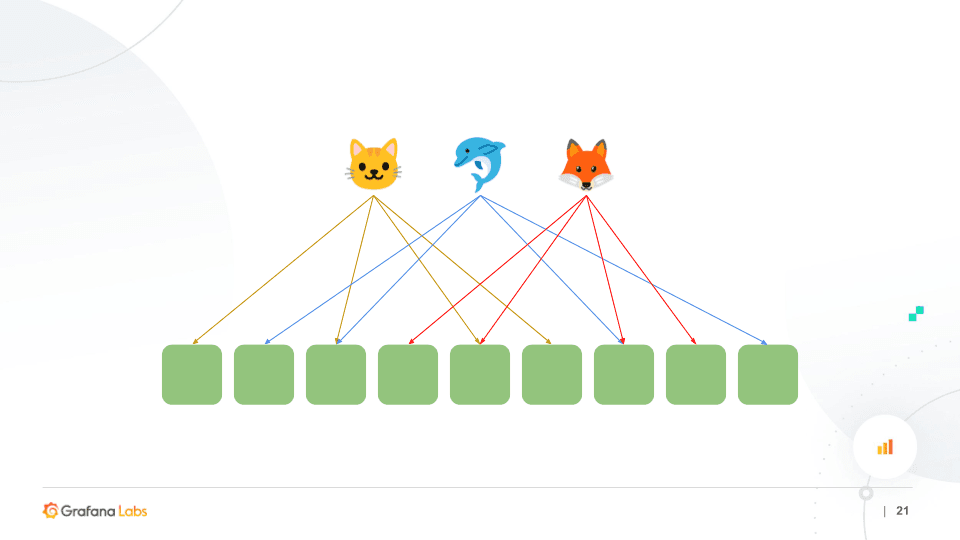
For a Cortex system to be horizontally scalable, we need to be able to take in data, shard it, and spread it amongst the nodes in a cluster. Cortex does this by hashing the labels within the samples that get written. This is how we make a cluster capable of coping with more writes and more reads in aggregate than any single node in that cluster. This all happens automatically, so the user doesn’t have to configure anything. As you add new nodes, we can scale up, and we can scale down as you remove nodes.
The challenge, however, is a single node outage can potentially impact all of the tenants on the cluster. (In the diagram below, the tenants are the Cat, the Dolphin, and the Fox.)
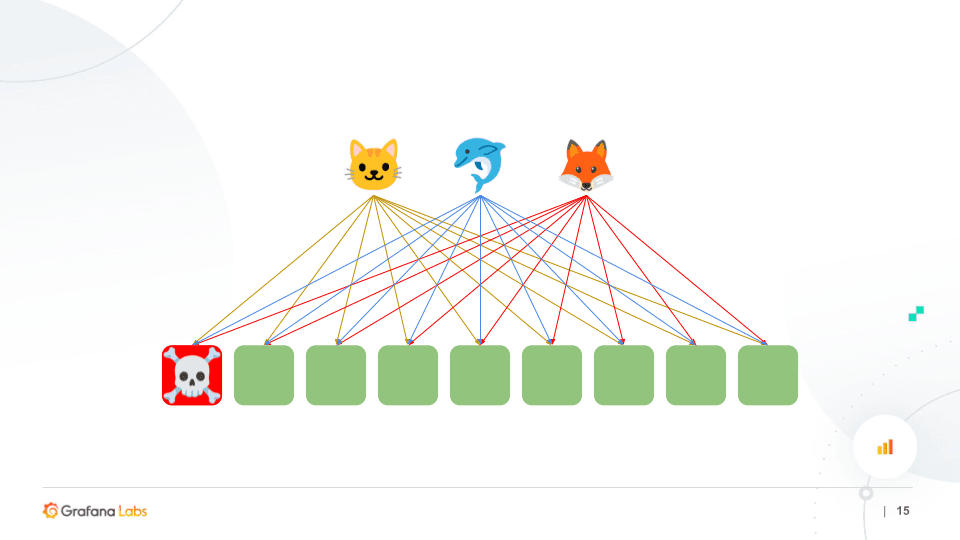
To avoid an outage from a single-node failure, we replicate the data between nodes using a replication factor of three and a quorum of reads and writes. What this means is when you write data, we write to three nodes, but we only wait for a positive response from two of them. So even when there’s a node outage, you can continue to write uninterrupted to the cluster because we’ll still be getting a positive response from two of the nodes.
But if a second node fails, even with a replication factor of three, we would then experience an outage because we’re not getting the positive response on writes and we don’t know that they’ve succeeded. In this case, there will be an outage for all of your tenants.
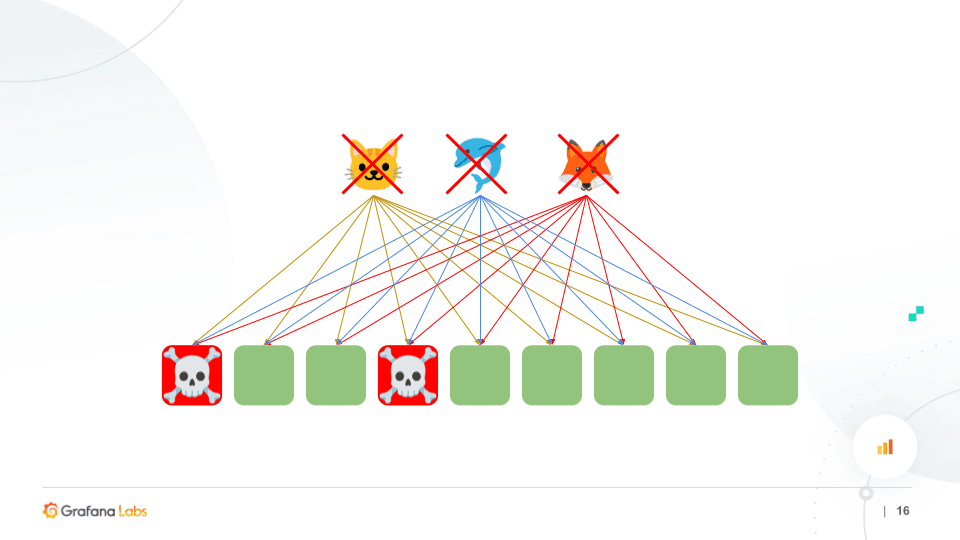
As an organization scales and adds more nodes, the chance of a random two-node failure is higher; therefore, the chance of a total outage on the cluster also increases. About five years ago, Grafana Labs was running smaller clusters. Then we grew to 10 and 20 node clusters. Now we’re running hundreds of node clusters.
Even more worrisome? If there’s a bug in Cortex or if there’s a misconfiguration and the tenant finds a way to exploit that, a poison request or a bad query could take out an entire cluster for all the tenants.
Here’s where shuffle sharding comes in. Shuffle sharding effectively picks a random sub-cluster within the cluster for each tenant. We hashed the tenant ID to select the nodes in the sub-cluster. Then within that set of nodes in the sub-cluster that the tenant is using, we use the normal Cortex replication scheme to distribute writes among those nodes. This allows you to have tenants of different sizes using the same cluster, and you can control the isolation between tenants, depending on how many nodes you allocate to each tenant.
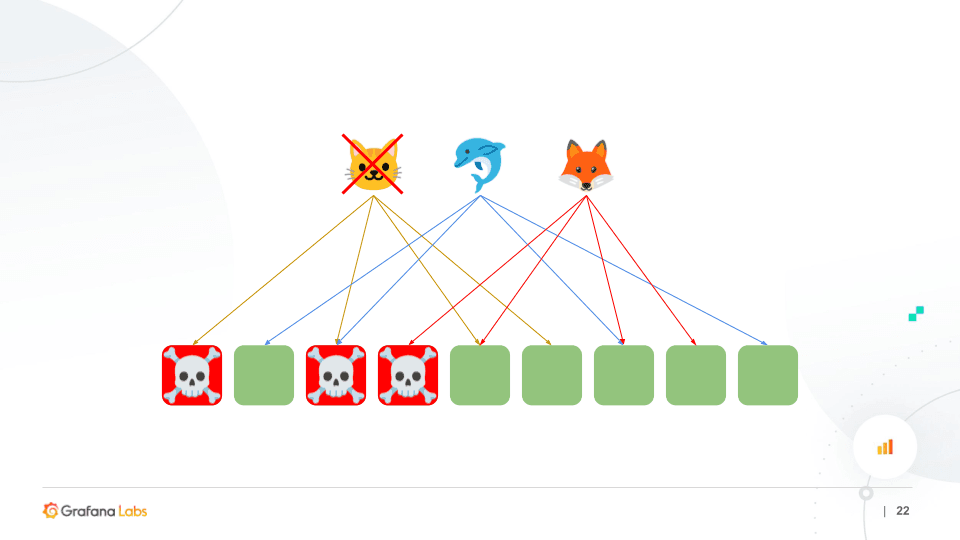
For example, in the three-node outage outlined in the diagram below, we can see that only one tenant was affected because both the Dolphin and the Fox only had one node impacted by the outage. As a result, shuffle sharding gives you much better tolerance to failure even with a partially degraded state.
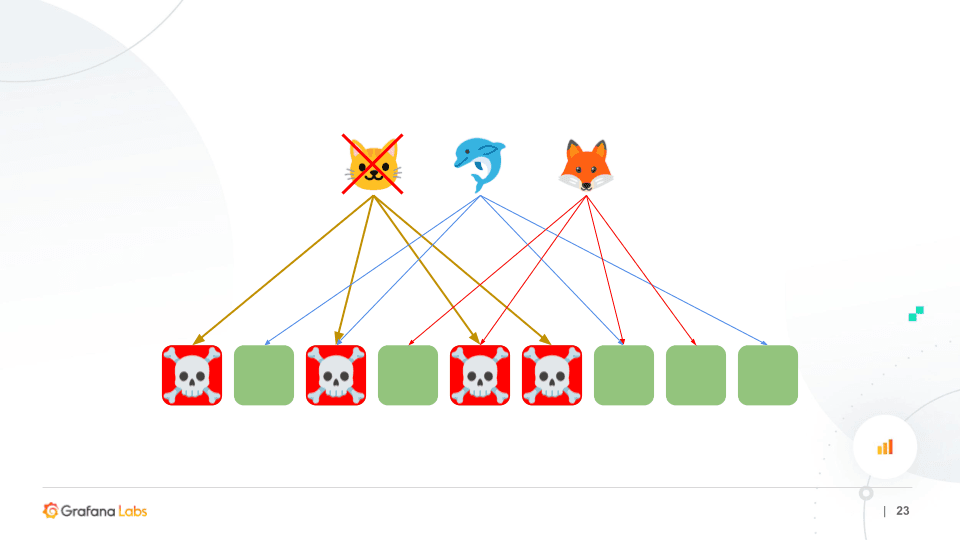
Another example would be if the Cat were to do a poison request, you can see how the Dolphin and the Fox are not affected because they’ve only got one node that’s been poisoned.
The trade-offs
The big question around shuffle sharding in Cortex is: How do you determine how many nodes to give each tenant? How do we trade off isolation and load balancing?
Imagine we had a 52-node cluster, and had to pick random 4-node “sub-clusters.” There would be roughly 270,000 possible combinations. But out of those, how many will share one node? Or how many have two nodes in common? There’s a Stack Overflow article about how to work it out, but in short, almost 75% of these permutations will not have any nodes in common. Almost 25% of them will share one node. Finally, only about 2.5% will share two nodes.
So in a 52-node cluster where all the shuffle shards are size four, a two-node outage would impact less than 2.5% of the tenants.
Now when we’re picking how many nodes to give each tenant, there’s a trade-off to consider: Fewer nodes mean we’re going to have better isolation. But if I give tenants more nodes, I’m going to be able to spread that load more evenly. That’s important because in a Cortex cluster, the tenants aren’t all the same sizes. We have some very large tenants, we have some very small tenants, and we have everything in between.
At Grafana Labs, better load balancing is not just considered a “nice to have.” Better load balancing can lead to higher utilization of resources, which translates to a lower cost of running the cluster. If you run Cortex as your SaaS platform like we do in Grafana Cloud, this is very important.
So we propose a simple algorithm that gives tenants the number of shuffle shards that are proportional to the number of series.
We built a simulator that simulated a Cortex cluster of about 60 to 70 nodes and a set of tenants comparable to the distribution of sizes that we observe in our production clusters at Grafana Labs. We then simulated picking shuffle shard sizes, distributing the samples to each of the virtual nodes, and measuring the variance in loads based on the number of series that they have and the number of tenants that were impacted by a two-node outage. The goal was to determine what proportion of tenants would be impacted by two nodes.
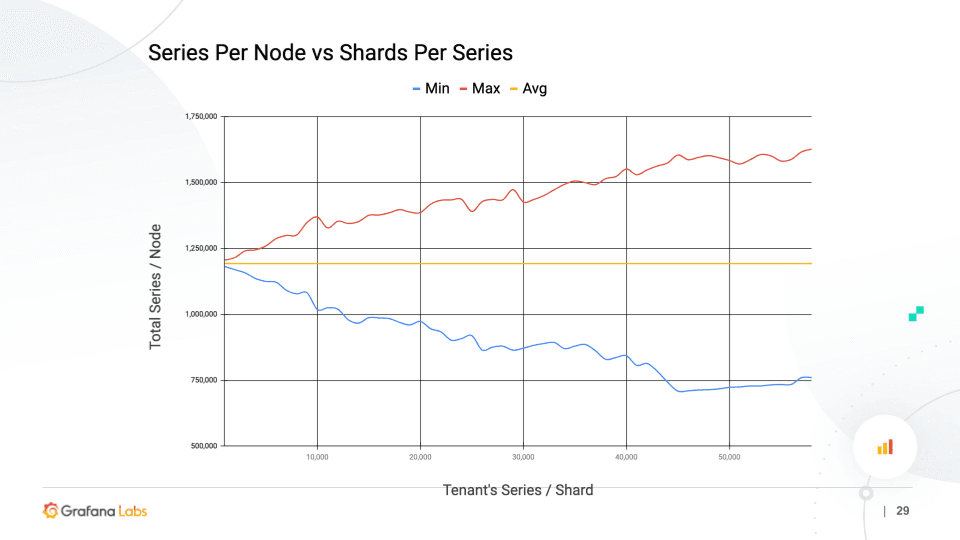
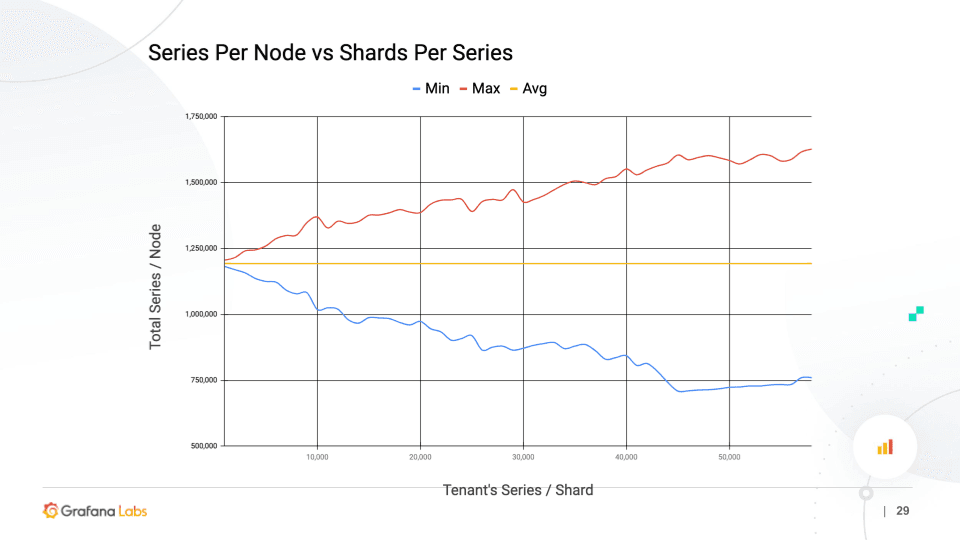
The above graph shows how well the load is distributed within the cluster (Y-axis) versus the size of each shuffle shard (X-axis). As you increase the number of series per “shuffle shard,” the distribution of your load gets worse, as we predicted. We can also see the load variance starts to flatten out. I believe this happens as the small tenants start to hit the minimum number of shuffle shards, which is three for replication.
For a shuffle shard size of 40,000 series, the maximum number of series on a single node is about 1.5 million, and the minimum is about 750,000. That’s a factor of two difference, which we wouldn’t want in the size of our nodes because that will make it very hard to optimize utilization.
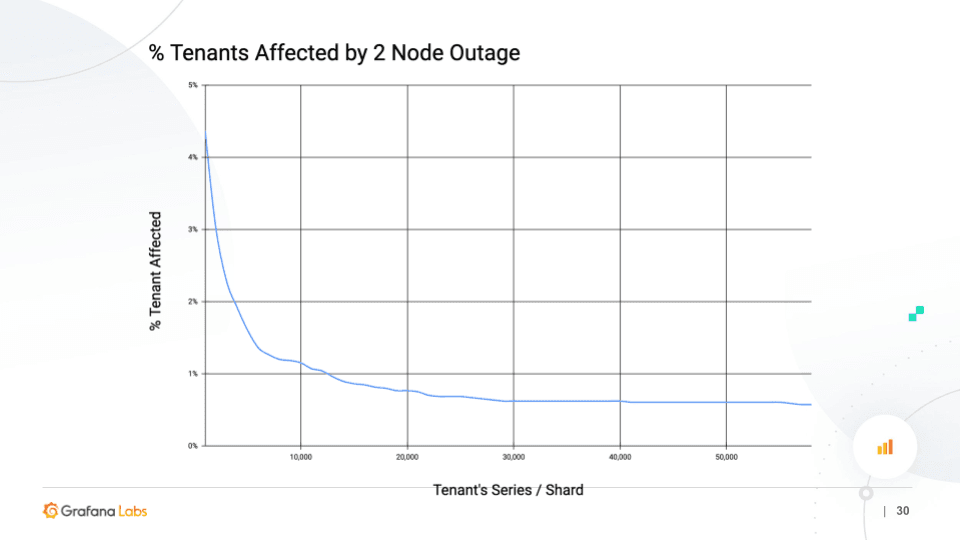
By contrast, as you increase the size of the “shuffle shard,” the isolation — measured as the percentage of tenants affected by a two-node outage – starts to fall and eventually plateaus. At 30-40,000 series per shard, less than 1% of tenants in your cluster will be affected by a two-node outage.
This was modeled with 1,000 tenants, and we’re averaging 100,000 series per tenant. (Note: One of the key things this simulation took into account was replication factor.)
After looking at the graphs and debating internally, we came up with one good rule of thumb: At around 20,000 series per shard, we have a roughly 20% variance in the series per node, and about 2% of the tenants are affected by a two-node outage. The production conflict that we run on our larger Cortex clusters at Grafana Labs matches this. (We run 20,000 to 30,000 series per shard internally.)
Ultimately what this means is that we’ve been able to reduce the chance of an outage for most tenants when there are two nodes suffering problems, and we’ve been able to scale up to even larger Cortex clusters with hundreds of nodes. We’ve also managed to better isolate tenants from each other so there’ll be fewer noisy neighbor issues and a smaller chance of a poison pill affecting other tenants.
An added bonus: We’ve managed to do all of this while keeping the variants in load among these nodes relatively bound, and therefore, not increasing the cost of running this cluster and not passing on any kind of cost to the customer for this.
Cortex: past, present, and future
Early on in the life of the Cortex project, we started focusing on query performance with query caching, parallelization, and sharding.
We joined the CNCF sandbox in 2018, and since then we put a lot of effort in making Cortex easier to use and building our community, by launching the website and with our 1.0 release.
More recently, we’ve been focusing on new and exciting features in Cortex. We added a system called block storage, which is similar to what Thanos does. Other new features include query federation, relaxing some multi-tenancy isolation features so you can query data in multiple different tenants, and a per tenant retention so different tenants can have different amounts of data stored for different lengths of time. Then, of course, we included shuffle sharding at the end of 2020.
If you’re interested in trying out Cortex in your organization, you can sign up for a free 30-day Grafana Cloud trial.