

How the Cortex and Thanos projects collaborate to make scaling Prometheus better for all
Cortex and Thanos are two brilliant solutions to scale out Prometheus, and many companies are now running them in production at scale. These two projects, both in the CNCF Sandbox, initially started with different technical approaches and philosophies:
- Cortex has been designed for scalability and high performances since day zero, while Thanos was originally focused on operational simplicity and cost-effectiveness.
- Thanos can be rolled out incrementally, starting with a Thanos sidecar running alongside your Prometheus servers and then adding other components when needed, while Cortex has an all-or-none philosophy.
- Cortex is based on a push-based model (Prometheus servers remote-write to Cortex), while originally Thanos had only a pull-based model (Thanos querier pulls out series from Prometheus at query time).
But over time, the two projects started to learn from and even influence each other – and these differences have been reduced. Thanos now supports a push-based model via its recently introduced receiver component, and many improvements have been done both in terms of scalability and performances. Likewise, Cortex’s operational complexity has been significantly reduced: we introduced the single binary mode, removed some external dependencies, and worked hard to improve the documentation.
At PromCon 2019, Tom Wilkie (co-creator of Cortex) and Bartek Plotka (co-creator of Thanos) gave a beautiful talk about the similarities and differences between Cortex and Thanos. At PromCon Online this week, Bartek and I (a new maintainer for Cortex and Thanos) decided to give a follow-up talk about how the collaboration has been even stronger over the past year.

Here’s a recap.
The first step to a stronger collaboration
Cortex historically required two backend storages for the time series data: an object store for chunks of compressed timestamp-value pairs, and an index store to look up these chunks by series labels matchers.
This architecture works and scales very well; we see massive Cortex clusters storing tens to hundreds of millions of active series with a 99.5 percentile query latency below 2.5s. However, running a large and scalable index store on premise (e.g., Cassandra) may add significant operational complexity, while running it on cloud services (e.g., AWS DynamoDB or Google Bigtable) may impose significant operational costs.
Nearly a year ago, in the Cortex community, we started brainstorming about removing the need to run an index store at all, instead storing all the time series data in the object store.
We set out to design it independently, but always liked how Thanos solved this problem in their store component. So instead of reinventing the wheel and competing with Thanos, why not collaborate with them and help them to further improve it?
That is how the Cortex blocks storage, which is an alternative storage engine for Cortex, was born – and stronger collaboration with Thanos started.
Collaboration, oh my!
Collaborating with Thanos has been an amazing experience so far. People are nice, open, and skilled. There are strong opinions involved, but they’re loosely held, and at the end of the day, decisions are taken in the best interests of Cortex and Thanos.
But let’s be honest! Collaborating and sharing are also tough sometimes, and the specter of competition is always around the corner.
Reaching a consensus takes a long time, and you have to convince a wider group of people. The two projects also have some differences in strategy, so any changes we propose to Thanos must make sense for both projects, without bringing any significant downside in terms of performance or maintenance burden.
Moreover, some changes end up being a two-step process: You first submit changes into Thanos, and then, once they’re merged, you backport these changes into Cortex. Not to mention any contribution to Prometheus, where the chain is one step longer. And you know that Grafana Loki depends on Cortex? The chain for them is even longer, and yes, I feel their pain sometimes.
It is very tempting to pick the shortest path. Maybe you get things done without upstreaming your improvements or fixes. Maybe you will just postpone them (and we all know that once you postpone something you will never do it). Or maybe you take the extreme approach of forking an entire package to move faster.
But we’re not collaborating for the sake of collaborating. We are collaborating and sharing because we care for each other, and we believe that what each project gets back is greater than the sum of our individual contributions.
We constantly share ideas, success and failure stories, production issues, optimization techniques, or design principles. We don’t necessarily agree on everything, but this open conversation we have on multiple aspects of the projects helps us open our minds, widen our horizons, and learn. Sharing is learning.
What do you say? Want some examples? Oh, I’m here for this!
Caching for the win!
Cortex has quite a long history of aggressive caching. Everything computationally or operationally expensive is cached in Cortex. Tom’s mantra is: if something is slow, probably it’s because you don’t have enough caching in front of it.
When we started building the Cortex blocks storage, we realized that the Thanos store didn’t support a shared cache and that there was some room for improvement here.
Over the past few months, we’ve introduced in Thanos the memcached support for index cache, chunks cache, and metadata cache (bucket objects content, attributes, and listing). We’ve seen tremendous benefits from it when testing the Cortex blocks storage at scale, both in terms of query performances and bucket API calls reduction.
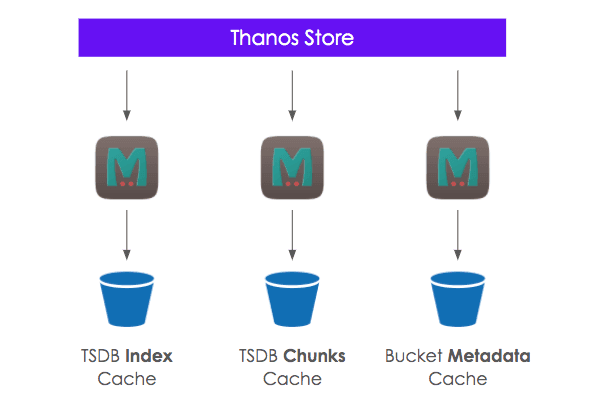
Damn, Thanos is so elegant!
Thanos configuration is elegant. It’s compact, consistent, and easy to consume. Coming from different design principles, Cortex configuration allows you to fine-tune every single bit, which turns out to be quite powerful when you set up a large production cluster, but makes it more difficult to start with.
We learned a lot from Thanos, and we significantly improved and simplified the Cortex configuration in Cortex 1.0, though it’s still a work in progress. We worked on better defaults, documentation, and consistency.
An example is the way Cortex runs DNS service discovery (e.g., memcached cluster nodes). Before, there wasn’t a common solution for this, and service discovery supported by different Cortex components was configured differently on a case-by-case basis. Recently we started migrating to the Thanos DNS service discovery, which has a simple yet effective way to configure it.
Gimme speed!
Optimization is a never-ending process. You may spend an entire career optimizing a piece of code and you will still discover new techniques on your last day of work. That’s why sharing learnings is very important, and we do share a lot.
Did you know that labels regex matching is slow when running it over a very high cardinality label name, and that there are some common use cases with literals within the regex – like .*foo or foo.* – that can be significantly optimized with a simple strings.HasPrefix() or strings.HasSuffix()? We didn’t, but we learned it from Loki!
Or did you know that the commonly used ioutil.ReadAll() is very bad in terms of memory allocations if you know in advance the size of the input Reader, but there’s a simple solution to fix it? We learned that from Loki as well. Honestly, when it comes to performance optimizations, the Loki team is top notch. Much respect!
These are just a few examples. But it’s not about a single optimization. It’s all about sharing what you learn and backporting your findings to other projects.
The Cortex blocks storage
Last but not least, the Cortex blocks storage has been built on top of a few core Thanos components: blocks shipper, bucket store, and compactor.
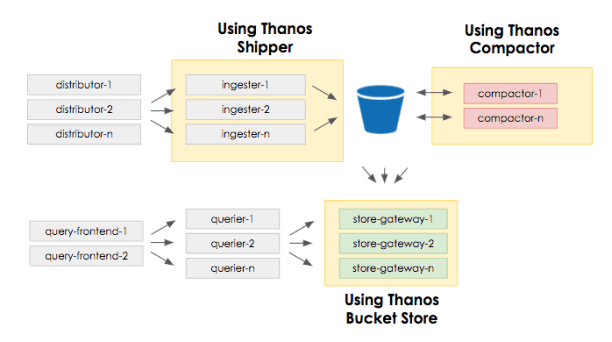
Leveraging Thanos allowed us to get a working proof of concept quickly and avoid making some early-stage mistakes. If we had built everything from scratch, I’m pretty sure I wouldn’t be here today mentioning how cool the new Cortex blocks storage is. It’s very likely we would still be building it.
On the other hand, Thanos got their code exercised more, we found and fixed a few issues here and there, and – as previously mentioned – we contributed back with some speed improvements, like caching.
And given Thanos storage is based on Prometheus TSDB, and thus the Cortex blocks storage is as well, we helped exercise and stress-test TSDB too. We found and fixed bugs and bottlenecks, and we’ll obviously continue to do it because we care. A lot!
Wrapping up
Open source is amazing.
To me, open source is one of most beautiful expressions of collaboration. A group of very diverse people, from all over the world, join together to build something for a wider community.
Collaboration is not easy, but definitely worth it. It’s hard to foresee a future where we will collaborate less between Cortex and Thanos. After all, one does not change a winning team.
Take care, stay safe, and join us if you want to build something even greater together!

