
What's new from Grafana Labs
Grafana Labs products, projects, and features can go through multiple release stages before becoming generally available. These stages in the release life cycle can present varying degrees of stability and support. For more information, refer to release life cycle for Grafana Labs.
Loading...
Area of interest:
Cloud availability:
Cloud editions:
Self-managed availability:
Self-managed editions:
No results found. Please adjust your filters or search criteria.
There was an error with your request.
Apply this transformation to any dataset to add a trendline as a new series, fitted to your data using linear regression. This allows you to infer what the data was at a point that may not be exactly represented in the original dataset, or plot predicted values in the future. Trendlines are great for spotting patterns in fluctuating or inconsistent time series. This transformation is extra useful because trendlines can be styled and used just like any other series in your visualization. The Trendline transformation supports both linear and polynomial regression models.
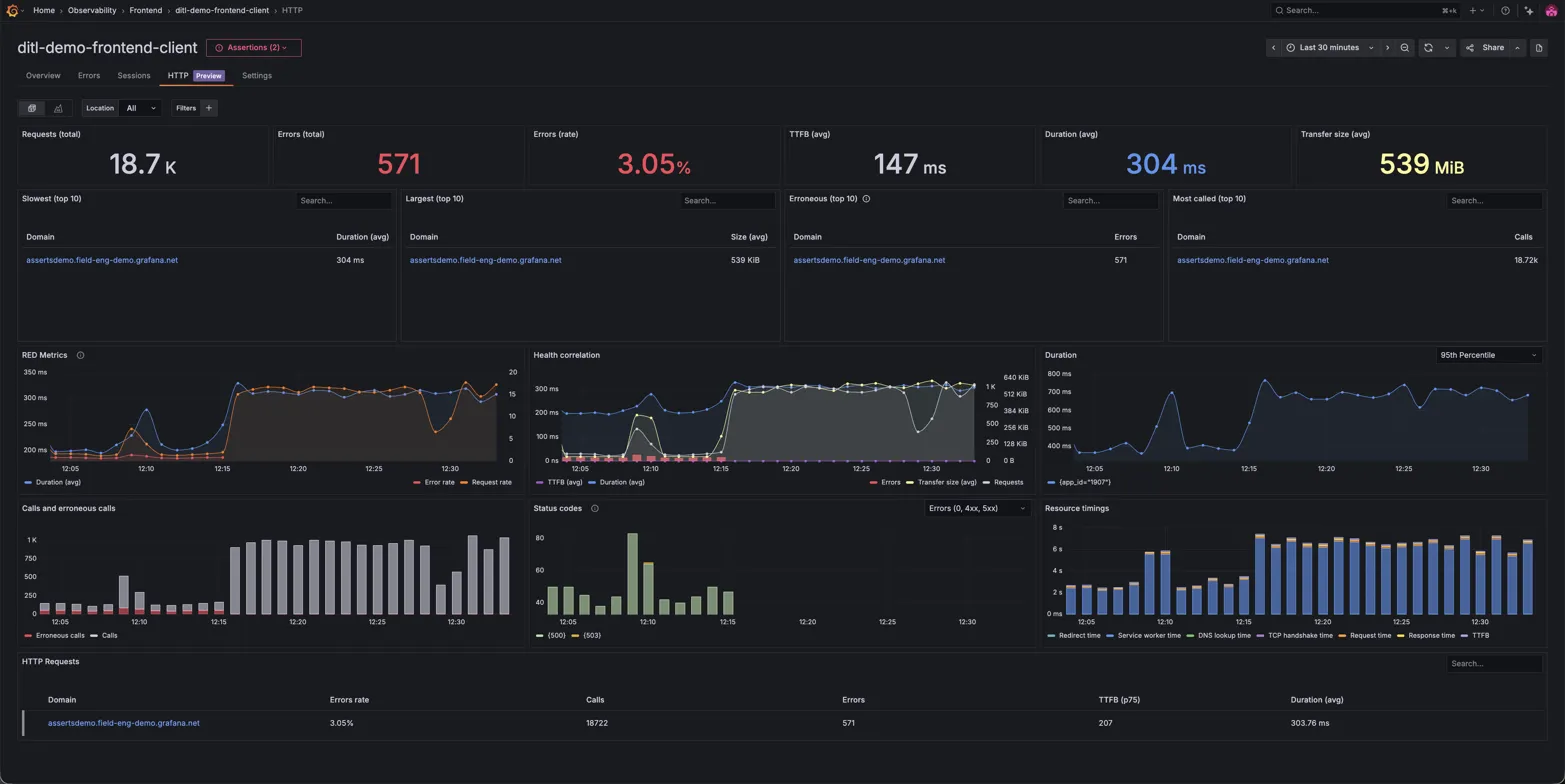
You can now visualize HTTP Performance Insights in Grafana Cloud Frontend Observability. This feature provides a unified view of your slowest endpoints, largest requests, and most error-prone calls, helping you quickly identify and resolve application performance issues.
No more hunting through scattered logs or custom dashboards. These views and breakdowns help you discover insights and gauge impact. You can understand:
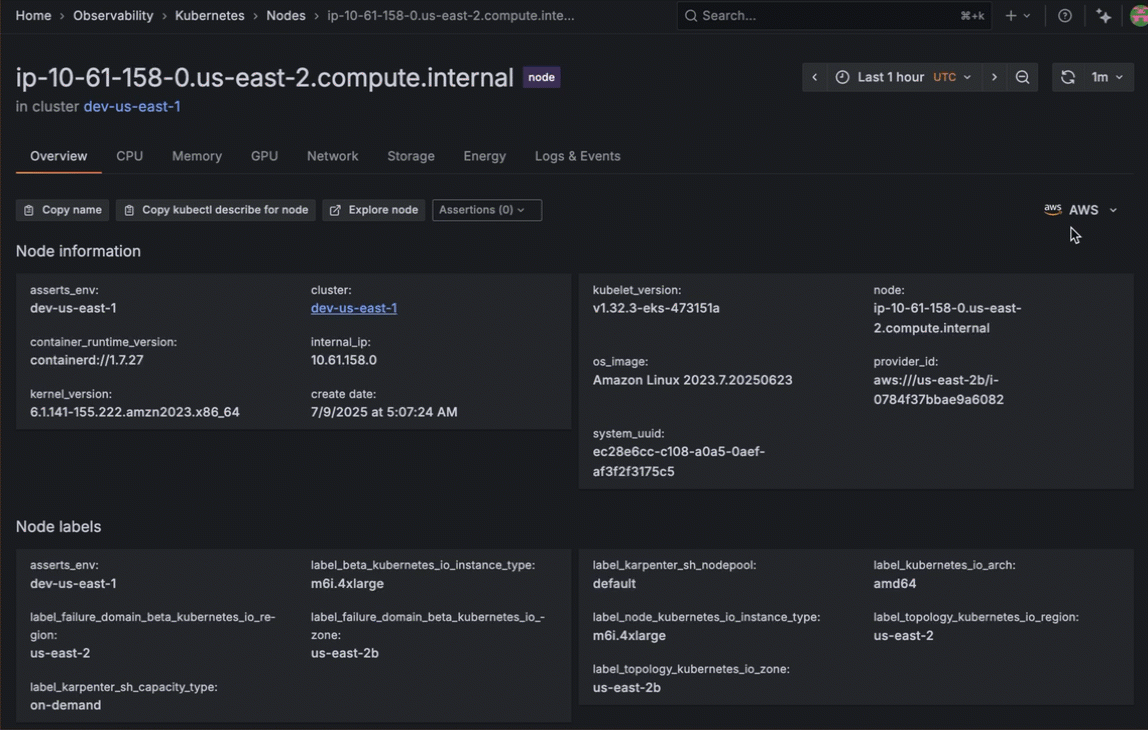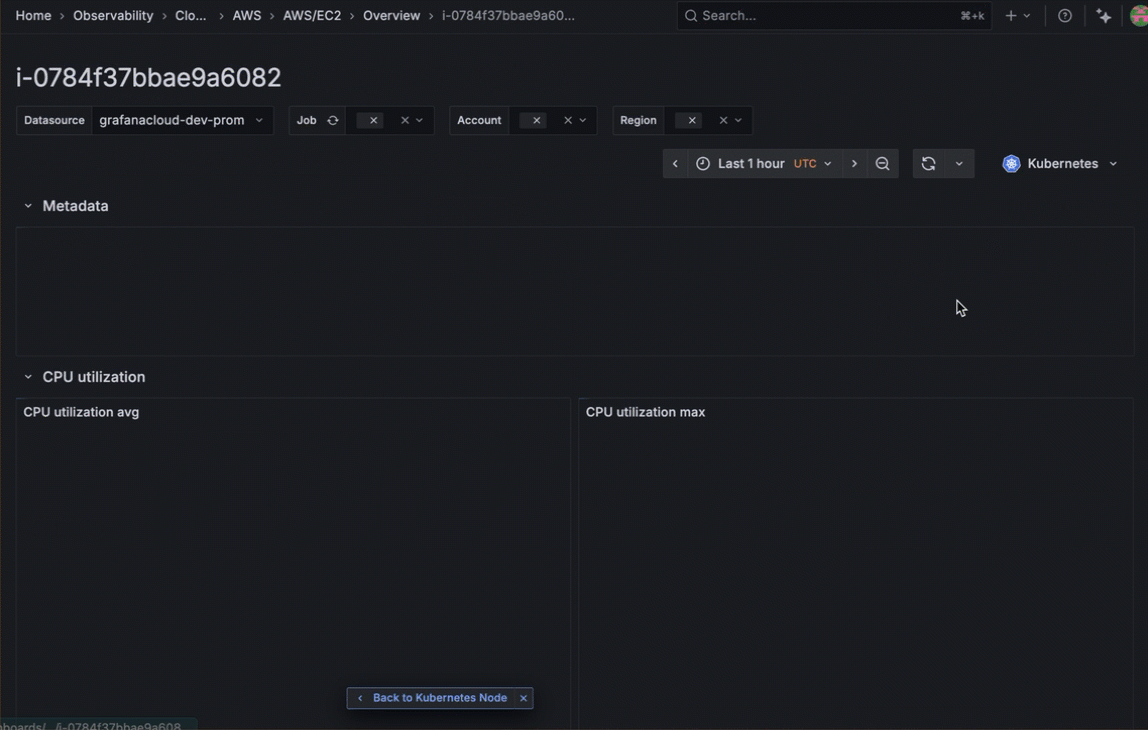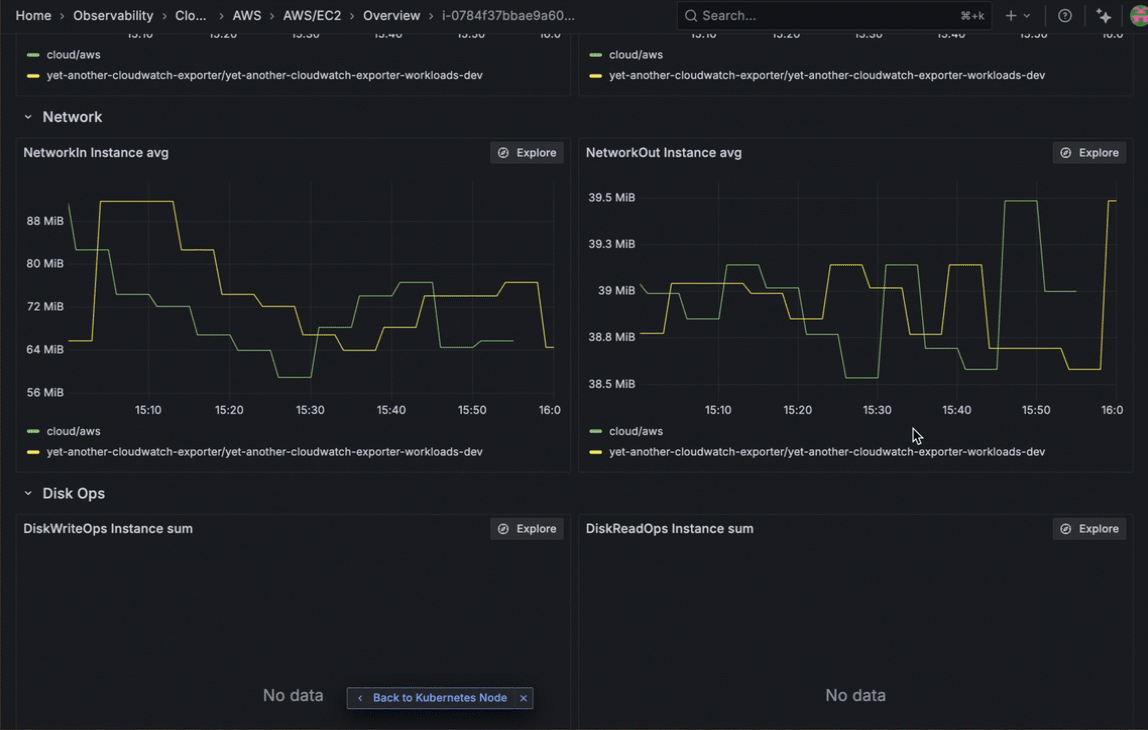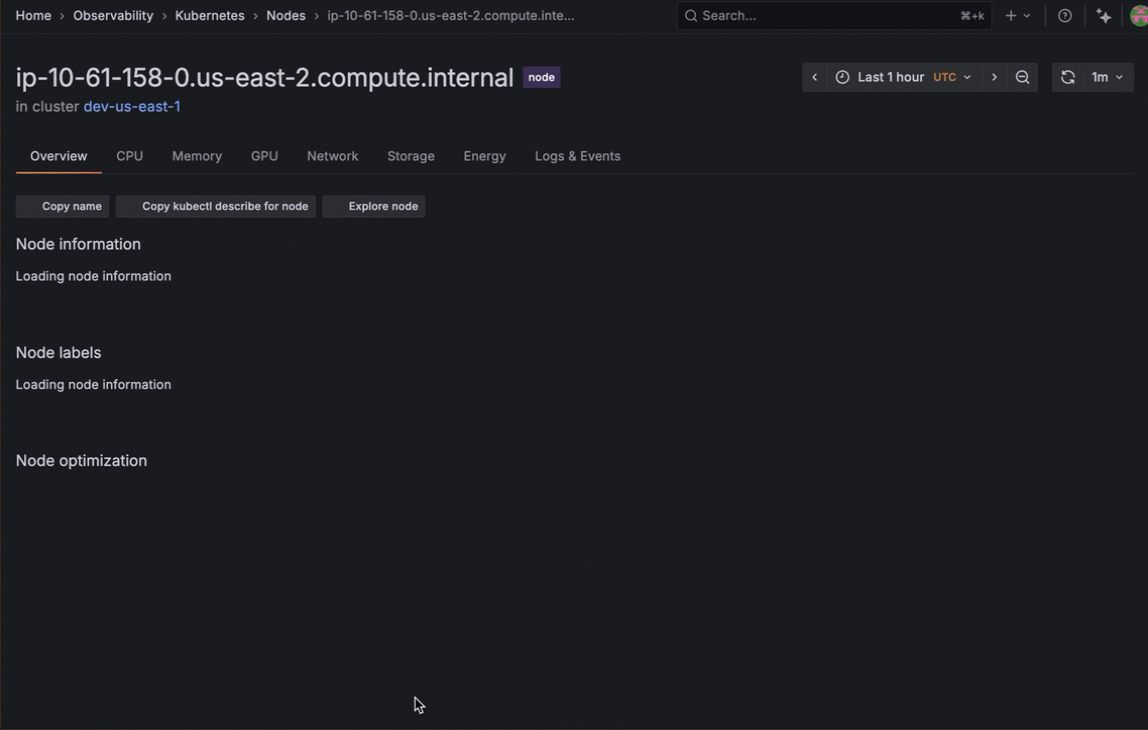
Instantly pivot from Kubernetes Monitoring to the exact EC2 instance in Cloud Provider Observability that’s impacting performance or stability. Whether it’s a failing node, resource exhaustion, or an unreachable instance, this seamless cross-layer visibility removes manual guesswork and eliminates the need for context-switching.
Segmentation makes it easy for you to manage Adaptive Logs by team, business unit, or any other logical division.
Using segmentation, you can decentralize log management. Shift responsibility from a central team to smaller units, empowering each to manage their own Adaptive Logs rules and control log intake with confidence.
Grafana Assume Role is now Generally Available (GA) for CloudWatch and Athena data sources! Grafana Assume Role allows you to authenticate with AWS without having to create and maintain long-term AWS users or rotate their access and secret keys. Instead, you can create an IAM role that has permissions to access CloudWatch or Athena and a trust relationship with Grafana’s AWS account. Grafana’s AWS account then makes an STS request to AWS to create temporary credentials to access your AWS data. More information can be found in the AWS authentication docs.
On-call engineers need to be instantly aware when critical incidents occur, even in noisy environments or during deep sleep. The Grafana IRM Mobile App now includes five new high-intensity alarm sounds specifically designed to cut through ambient noise and grab your attention when it matters most.
The Google Sheets data source just got more powerful! Our 2.2.0 release adds support for template variables, making it easier to build interactive and adaptable dashboards directly from your spreadsheets.

Grafana now supports Entra Workload Identity, significantly enhancing authentication capabilities with federated credentials. This update simplifies the OAuth flow and improves security for Grafana instances leveraging Microsoft Azure, and was a valuable contribution from an external contributor. Thank you mehiglow.
We’re excited to announce that you can now define custom variables within visualization actions. When you trigger an action (such as an API request), you’ll be prompted to provide input for those variables. This makes actions more dynamic and interactive, allowing you to tailor requests in real time without modifying the dashboard configuration.
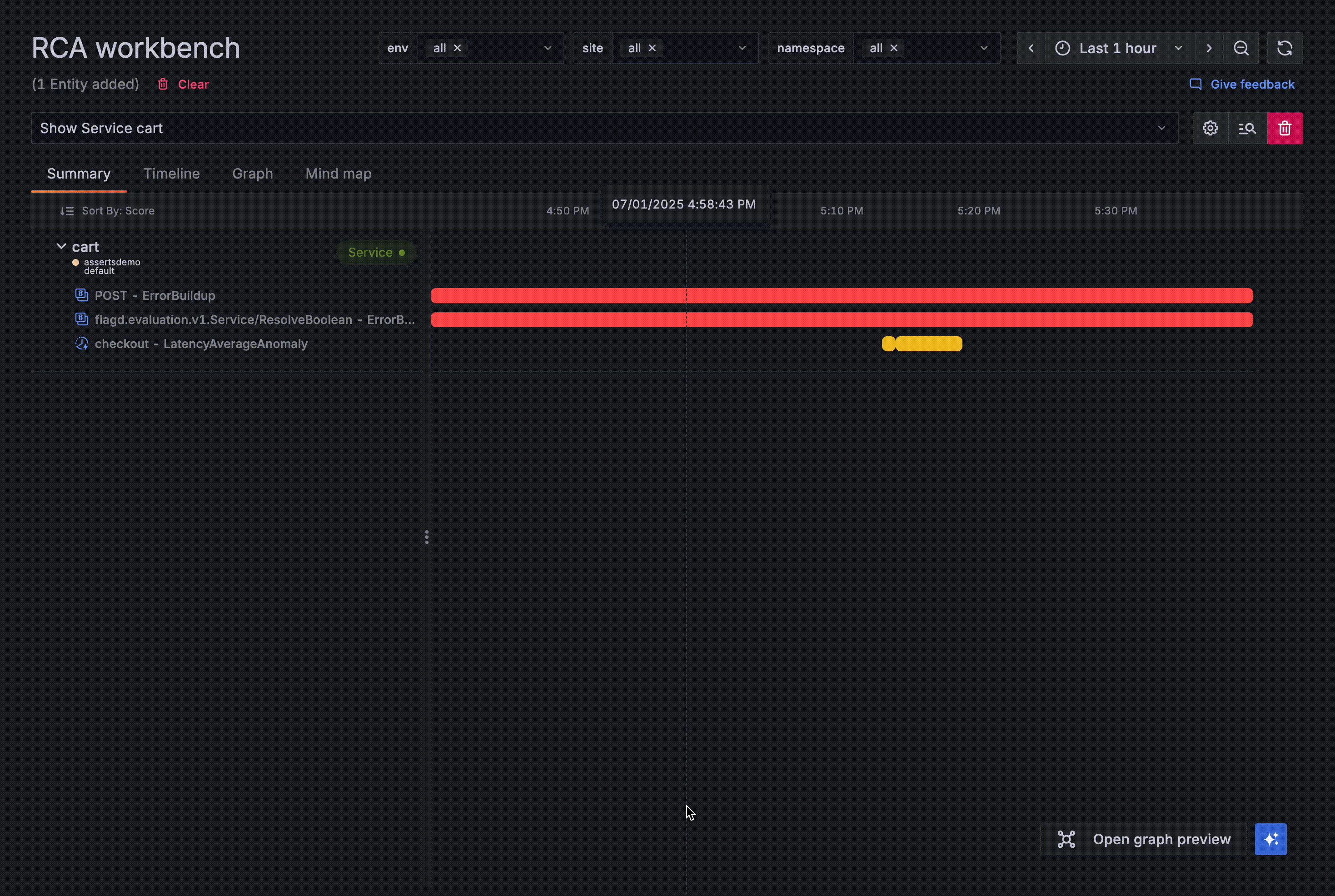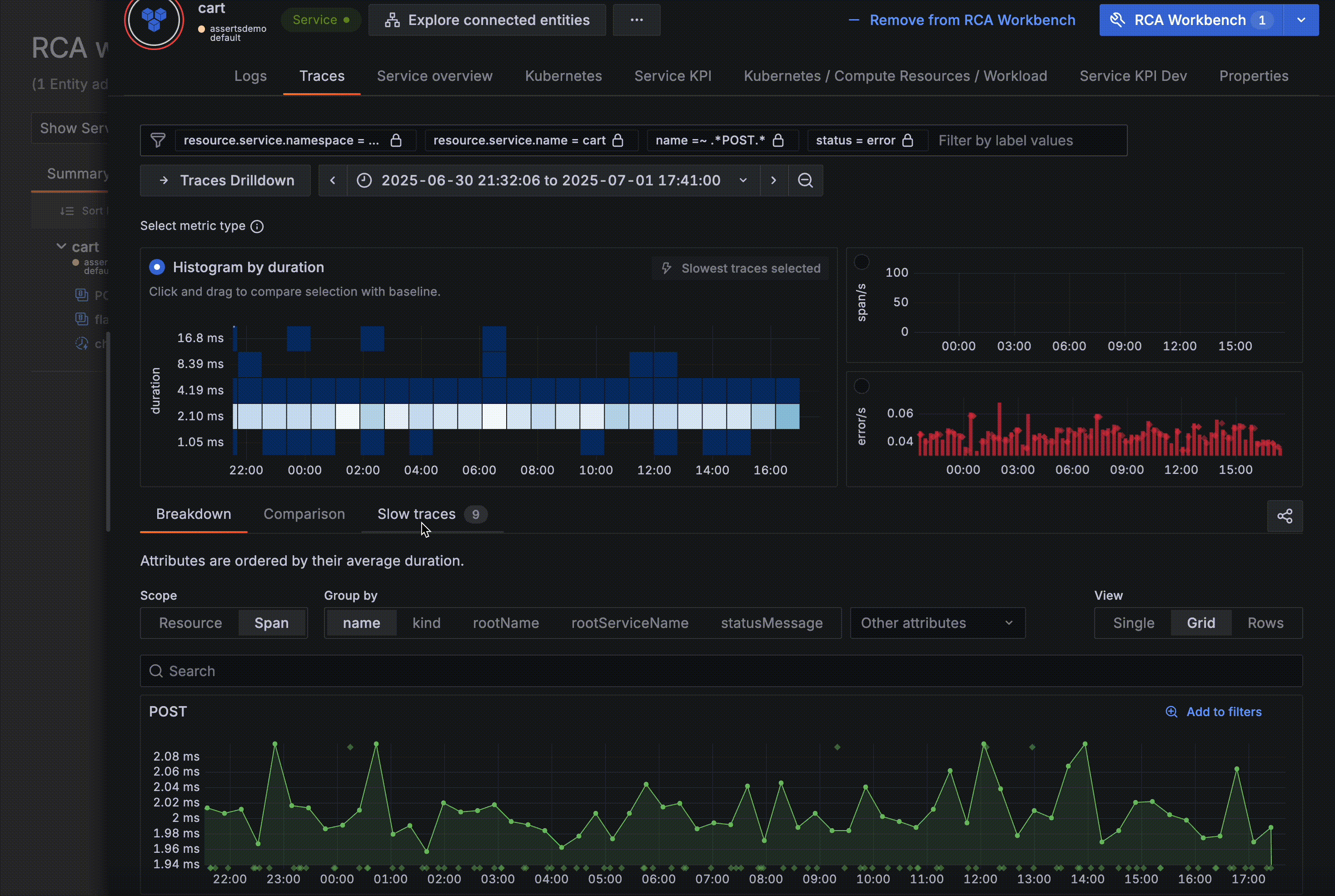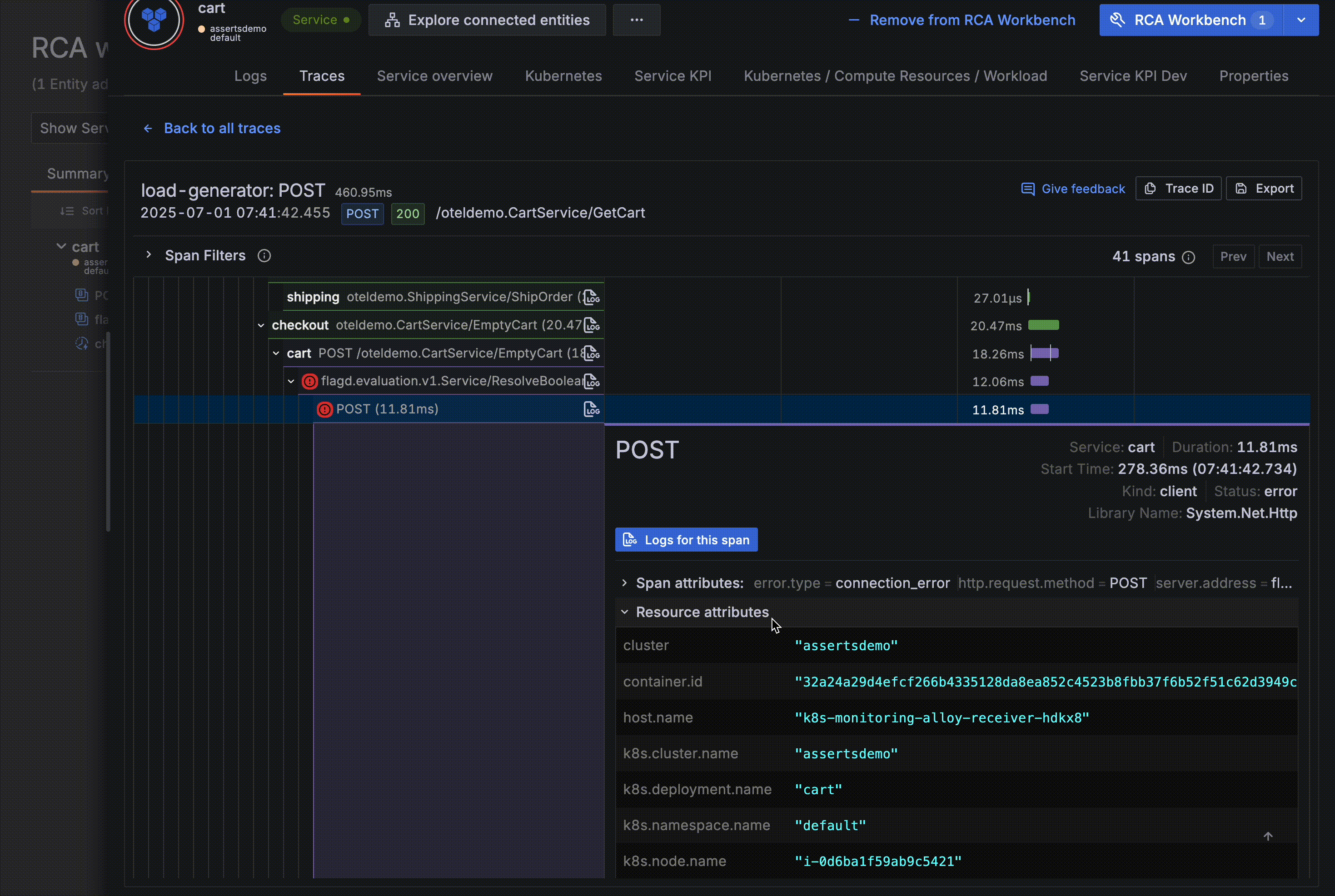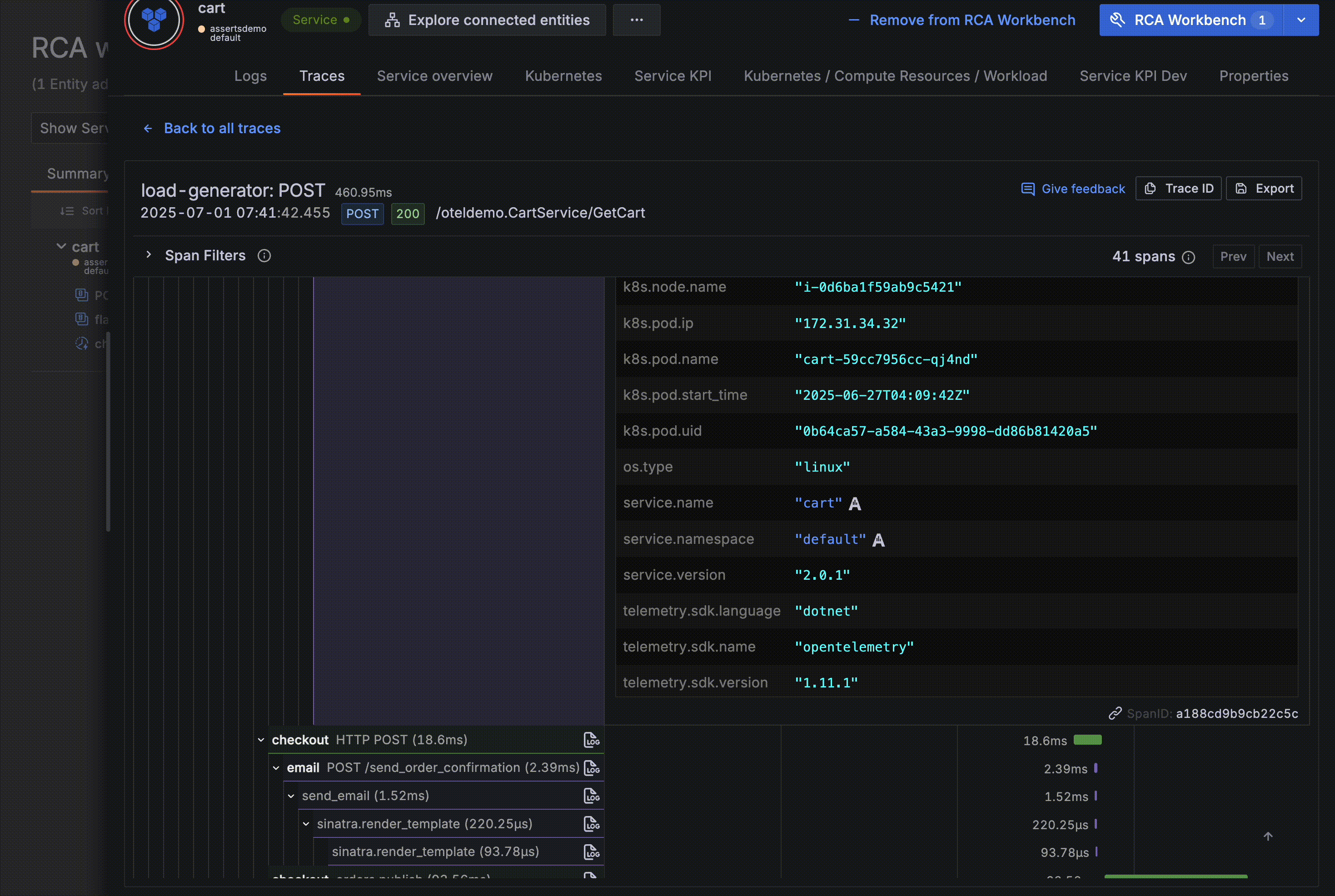
We are announcing the availability of embedded Logs Drilldown within Asserts. This is our second milestone, coming hot off the heels of launching the embedded version of Traces Drilldown in Asserts.
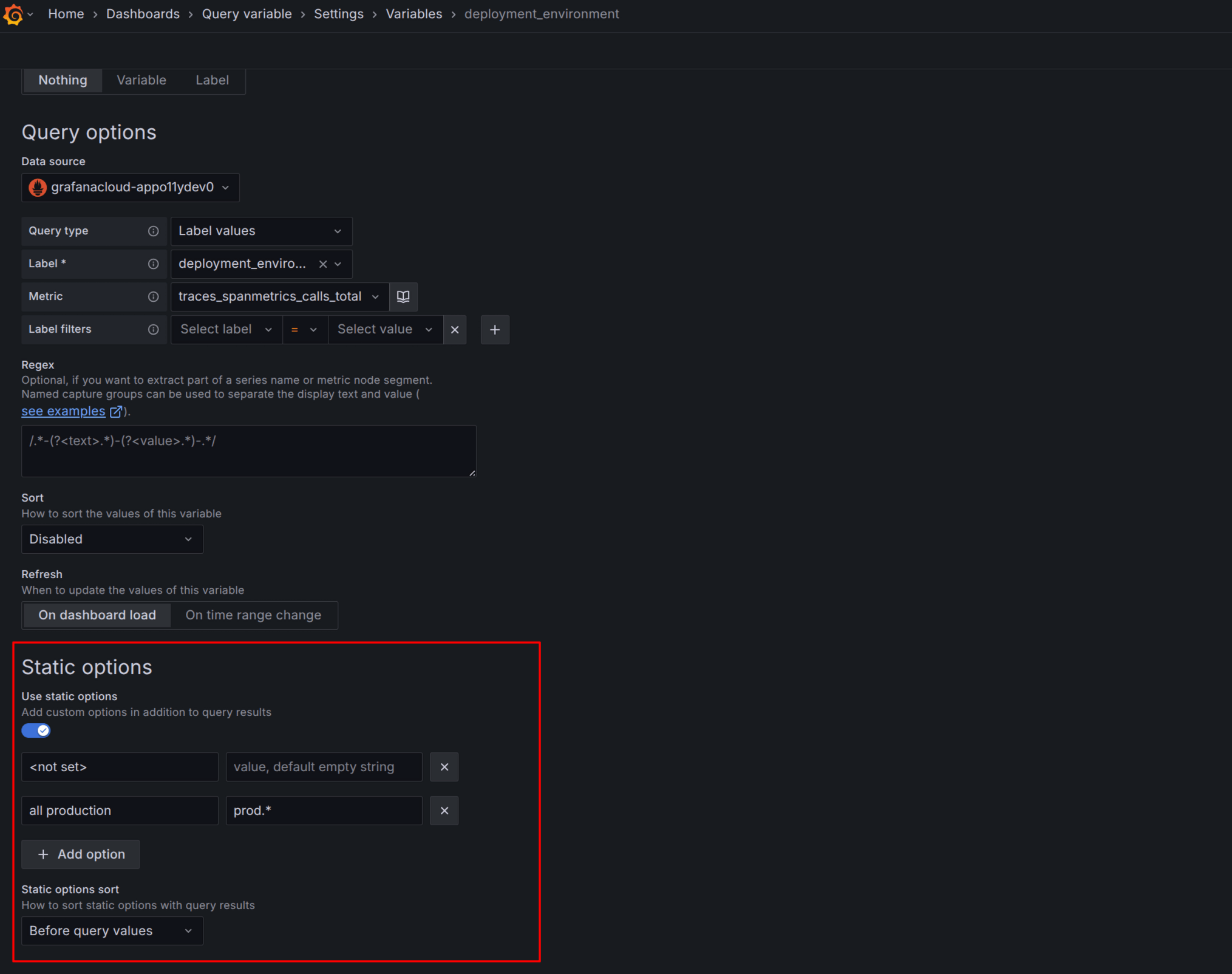
You can now define additional static options for query variables to be included with the options retrieved by querying the data source. This affords you more flexibility, allowing you to create options like “value not set” or “all clusters in Asia”.
Mute Timings have been renamed to Active Time Intervals to better align with their usage.
With auto-apply, you now get all of the benefits of Adaptive Metrics, in a more timely manner. Using auto-apply, recommendations are applied automatically, without a human in the loop. Maximize your cost savings and observability outcomes, and spend less time reviewing recommendations!
The Drilldown Apps are going places! We’re ensuring our opinionated experiences can benefit from our best-of-breed signal exploration workflows by making them embeddable in other contexts. Our first milestone is the integration of Traces Drilldown in the Asserts KPI drawer.
Introducing the all new user experience for per stream exports in Grafana Cloud Logs.
With per stream export, you can configure Grafana Cloud to export select log streams to your object storage bucket in AWS, Google Cloud, or Azure. By only exporting a subset of your logs, you can significantly reduce your object storage costs and minimize logs needed to sort through after being stored.