
Kong AI Gateway Dashboard
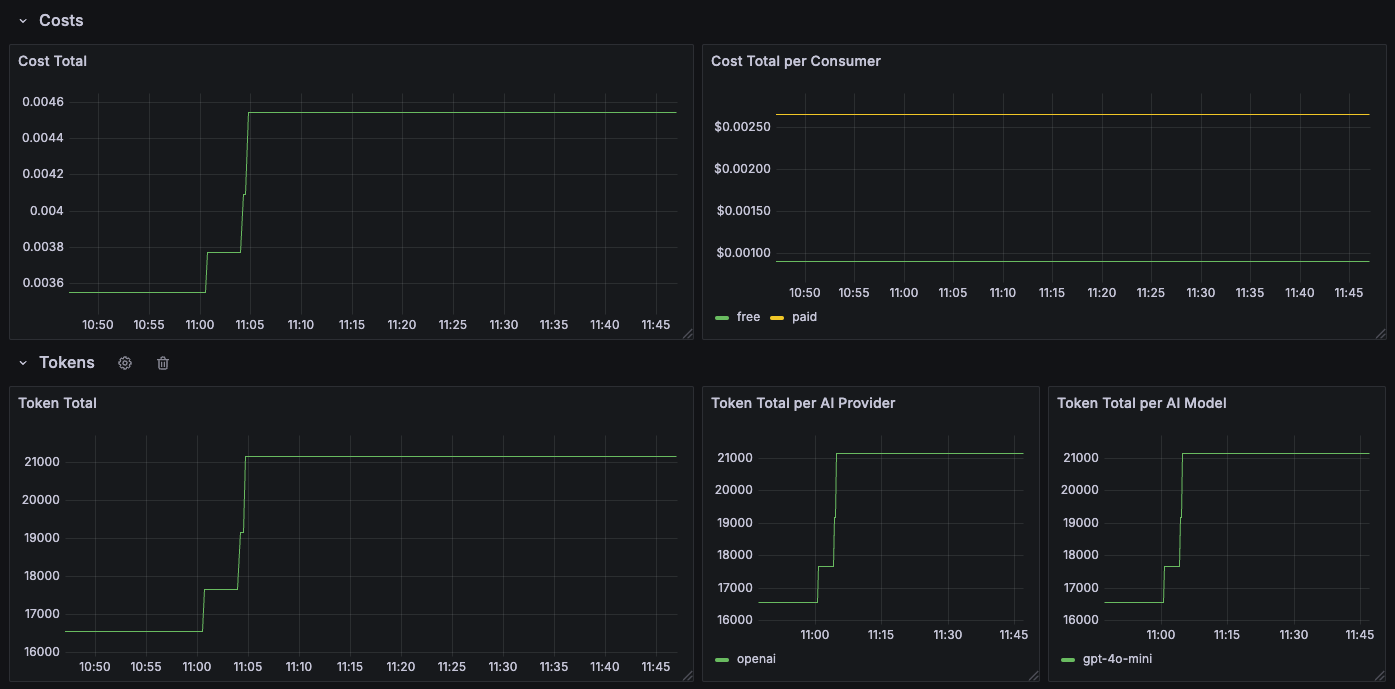
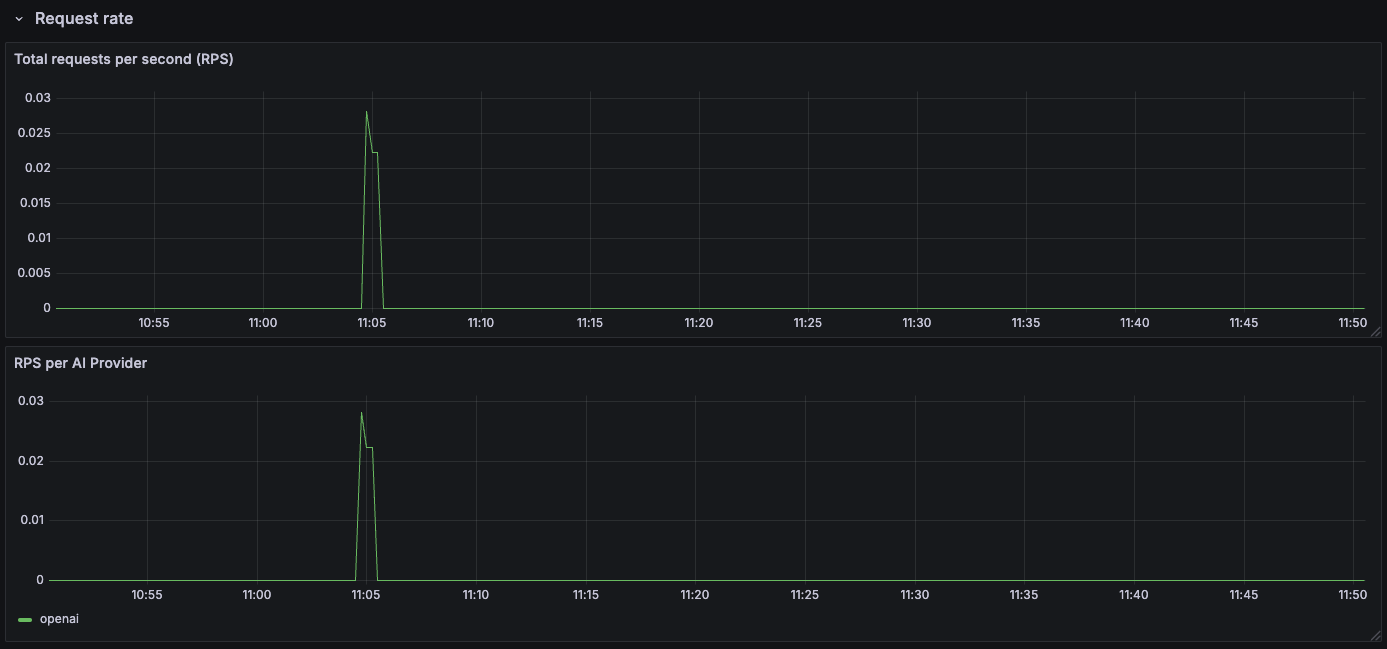
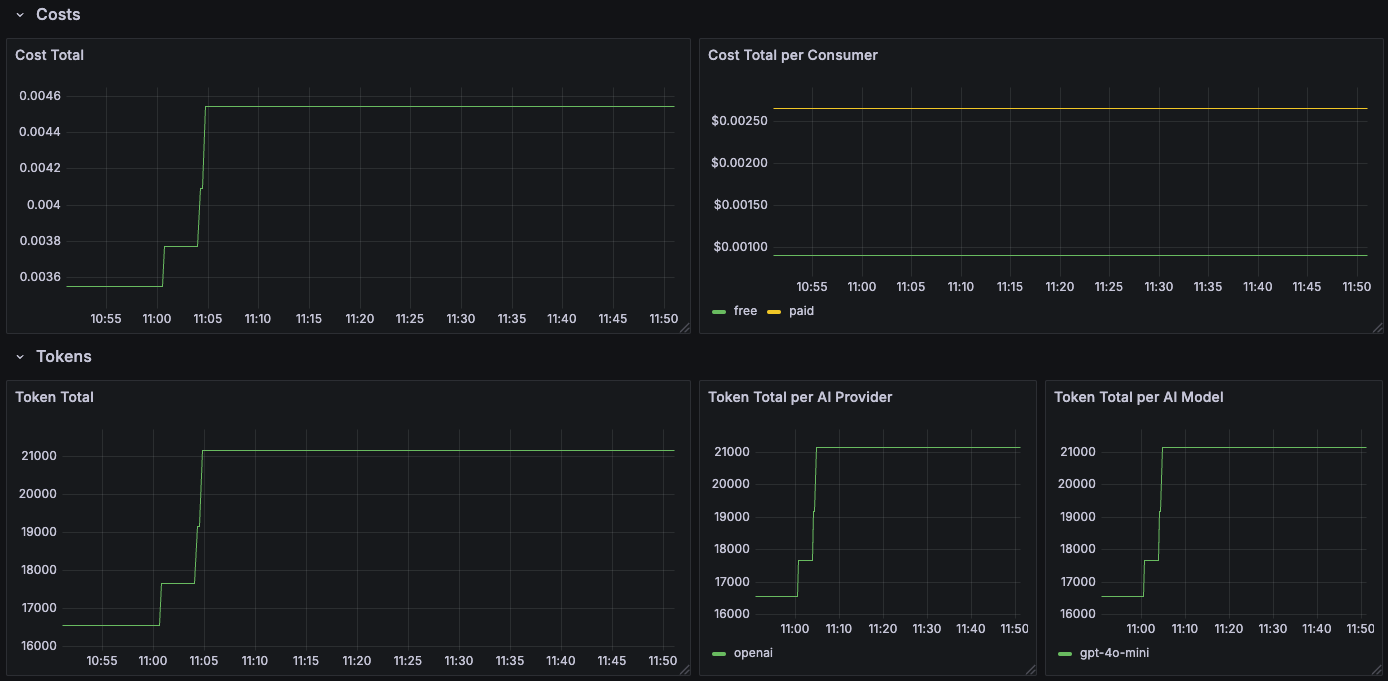
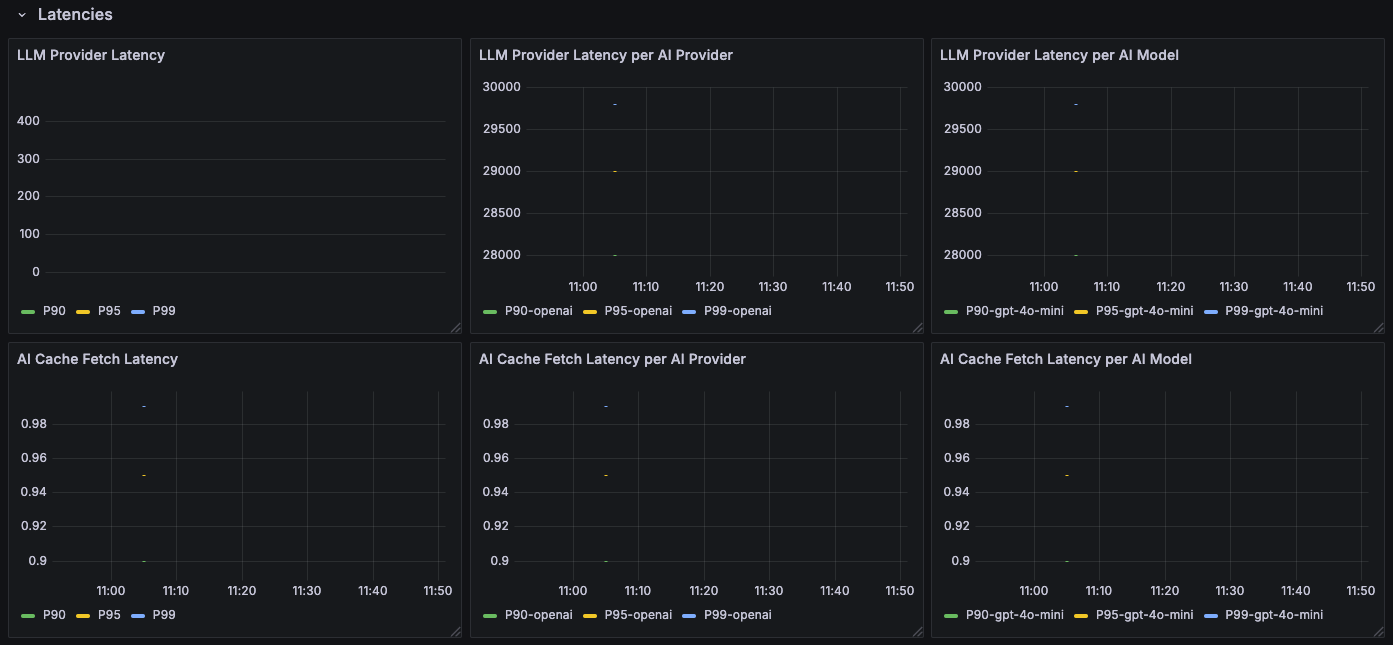
This dashboard visualizes the metrics available from the Kong AI Gateway. The following metrics are visualized:
- Request per Second (RPS): The number of requests processed per second.
- Token per Second (TPS): The number of tokens processed per second.
- Latency: The delay in processing requests, broken down by component:
- LLM Provider: Latency from the Large Language Model provider.
- Cache Fetch: Latency to retrieve data from the cache.
- Cache Embeddings: Latency related to creating embeddings for the cache.
- RAG Fetch: Latency to retrieve data for Retrieval-Augmented Generation (RAG).
- RAG Embeddings: Latency related to creating embeddings for RAG.
- Cost: The monetary cost associated with API usage.
- Token: The number of tokens consumed.
Data source config
Collector type:
Collector plugins:
Collector config:
Revisions
Upload an updated version of an exported dashboard.json file from Grafana
| Revision | Description | Created | |
|---|---|---|---|
| Download |