Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Open and closed models
Different k6 executors have different ways of scheduling VUs. Some executors use the closed model, while the arrival-rate executors use the open model.
In short, in the closed model, VU iterations start only when the last iteration finishes. In the open model, on the other hand, VUs arrive independently of iteration completion. Different models suit different test aims.
Closed Model
In a closed model, the execution time of each iteration dictates the number of iterations executed in your test. The next iteration doesn’t start until the previous one finishes.
Thus, in a closed model, the start or arrival rate of
new VU iterations is tightly coupled with the iteration duration (that is, time from start
to finish of the VU’s exec function, by default the export default function):
import http from 'k6/http';
export const options = {
scenarios: {
closed_model: {
executor: 'constant-vus',
vus: 1,
duration: '1m',
},
},
};
export default function () {
// The following request will take roughly 6s to complete,
// resulting in an iteration duration of 6s.
// As a result, New VU iterations will start at a rate of 1 per 6s,
// and we can expect to get 10 iterations completed in total for the
// full 1m test duration.
http.get('https://httpbin.test.k6.io/delay/6');
}Running this script would result in something like:
running (1m01.5s), 0/1 VUs, 10 complete and 0 interrupted iterations
closed_model ✓ [======================================] 1 VUs 1m0sDrawbacks of using the closed model
When the duration of the VU iteration is tightly coupled to the start of new VU iterations, the target system’s response time can influence the throughput of the test. Slower response times means longer iterations and a lower arrival rate of new iterations―and vice versa for faster response times. In some testing literature, this problem is known as coordinated omission.
In other words, when the target system is stressed and starts to respond more slowly, a closed model load test will wait, resulting in increased iteration durations and a tapering off of the arrival rate of new VU iterations.
This effect is not ideal when the goal is to simulate a certain arrival rate of new VUs, or more generally throughput (e.g. requests per second).
Open model
Compared to the closed model, the open model decouples VU iterations from the iteration duration. The response times of the target system no longer influence the load on the target system.
To fix this problem of coordination, you can use an open model, which decouples the start of new VU iterations from the iteration duration. This reduces the influence of the target system’s response time.
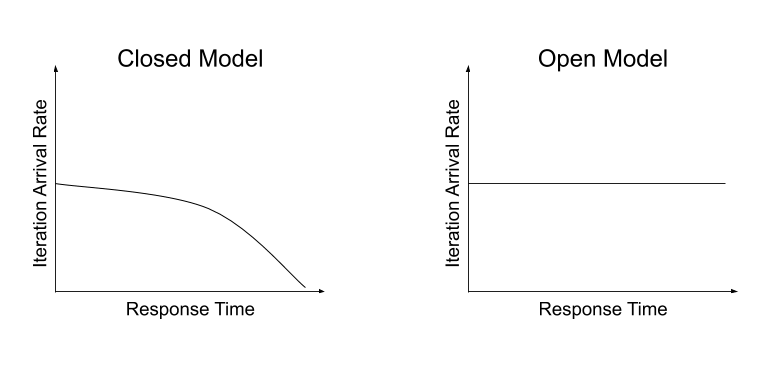
k6 implements the open model with two arrival rate executors: constant-arrival-rate and ramping-arrival-rate:
import http from 'k6/http';
export const options = {
scenarios: {
open_model: {
executor: 'constant-arrival-rate',
rate: 1,
timeUnit: '1s',
duration: '1m',
preAllocatedVUs: 20,
},
},
};
export default function () {
// With the open model arrival rate executor config above,
// new VU iterations will start at a rate of 1 every second,
// and we can thus expect to get 60 iterations completed
// for the full 1m test duration.
http.get('https://httpbin.test.k6.io/delay/6');
}Running this script would result in something like:
running (1m09.3s), 000/011 VUs, 60 complete and 0 interrupted iterations
open_model ✓ [======================================] 011/011 VUs 1m0s 1 iters/s