
Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Using PostgreSQL in Grafana
NOTE: In 9.5.18, 9.4.23, 9.6.14, 10.9, 11.4, 12-beta2 versions of PostgreSQL has a bug which prevents execution of multiple column modifications via
ALTER TABLEstatement. Because Grafana uses it during initial database set up and since PostgreSQL has fixed this issue, Grafana does not support these versions
Grafana ships with a built-in PostgreSQL data source plugin that allows you to query and visualize data from a PostgreSQL compatible database.
Adding the data source
- Open the side menu by clicking the Grafana icon in the top header.
- In the side menu under the
Configurationicon you should find a link namedData Sources. - Click the
+ Add data sourcebutton in the top header. - Select PostgreSQL from the Type dropdown.
Data source options
Min time interval
A lower limit for the $__interval and $__interval_ms variables.
Recommended to be set to write frequency, for example 1m if your data is written every minute.
This option can also be overridden/configured in a dashboard panel under data source options. It’s important to note that this value needs to be formatted as a
number followed by a valid time identifier, e.g. 1m (1 minute) or 30s (30 seconds). The following time identifiers are supported:
Database User Permissions (Important!)
The database user you specify when you add the data source should only be granted SELECT permissions on
the specified database and tables you want to query. Grafana does not validate that the query is safe. The query
could include any SQL statement. For example, statements like DELETE FROM user; and DROP TABLE user; would be
executed. To protect against this we highly recommend you create a specific PostgreSQL user with restricted permissions.
Example:
CREATE USER grafanareader WITH PASSWORD 'password';
GRANT USAGE ON SCHEMA schema TO grafanareader;
GRANT SELECT ON schema.table TO grafanareader;Make sure the user does not get any unwanted privileges from the public role.
Query Editor
Only available in Grafana v5.3+.

You find the PostgreSQL query editor in the metrics tab in Graph or Singlestat panel’s edit mode. You enter edit mode by clicking the panel title, then edit.
The query editor has a link named Generated SQL that shows up after a query has been executed, while in panel edit mode. Click on it and it will expand and show the raw interpolated SQL string that was executed.
Select table, time column and metric column (FROM)
When you enter edit mode for the first time or add a new query Grafana will try to prefill the query builder with the first table that has a timestamp column and a numeric column.
In the FROM field, Grafana will suggest tables that are in the search_path of the database user. To select a table or view not in your search_path
you can manually enter a fully qualified name (schema.table) like public.metrics.
The Time column field refers to the name of the column holding your time values. Selecting a value for the Metric column field is optional. If a value is selected, the Metric column field will be used as the series name.
The metric column suggestions will only contain columns with a text datatype (char,varchar,text).
If you want to use a column with a different datatype as metric column you may enter the column name with a cast: ip::text.
You may also enter arbitrary SQL expressions in the metric column field that evaluate to a text datatype like
hostname || ' ' || container_name.
Columns, Window and Aggregation functions (SELECT)
In the SELECT row you can specify what columns and functions you want to use.
In the column field you may write arbitrary expressions instead of a column name like column1 * column2 / column3.
The available functions in the query editor depend on the PostgreSQL version you selected when configuring the data source.
If you use aggregate functions you need to group your resultset. The editor will automatically add a GROUP BY time if you add an aggregate function.
The editor tries to simplify and unify this part of the query. For example:![]()
The above will generate the following PostgreSQL SELECT clause:
avg(tx_bytes) OVER (ORDER BY "time" ROWS 5 PRECEDING) AS "tx_bytes"You may add further value columns by clicking the plus button and selecting Column from the menu. Multiple value columns will be plotted as separate series in the graph panel.
Filter data (WHERE)
To add a filter click the plus icon to the right of the WHERE condition. You can remove filters by clicking on
the filter and selecting Remove. A filter for the current selected timerange is automatically added to new queries.
Group By
To group by time or any other columns click the plus icon at the end of the GROUP BY row. The suggestion dropdown will only show text columns of your currently selected table but you may manually enter any column.
You can remove the group by clicking on the item and then selecting Remove.
If you add any grouping, all selected columns need to have an aggregate function applied. The query builder will automatically add aggregate functions to all columns without aggregate functions when you add groupings.
Gap Filling
Grafana can fill in missing values when you group by time. The time function accepts two arguments. The first argument is the time window that you would like to group by, and the second argument is the value you want Grafana to fill missing items with.
Text Editor Mode (RAW)
You can switch to the raw query editor mode by clicking the hamburger icon and selecting Switch editor mode or by clicking Edit SQL below the query.
If you use the raw query editor, be sure your query at minimum has
ORDER BY timeand a filter on the returned time range.
Macros
Macros can be used within a query to simplify syntax and allow for dynamic parts.
We plan to add many more macros. If you have suggestions for what macros you would like to see, please open an issue in our GitHub repo.
Table queries
If the Format as query option is set to Table then you can basically do any type of SQL query. The table panel will automatically show the results of whatever columns and rows your query returns.
Query editor with example query:
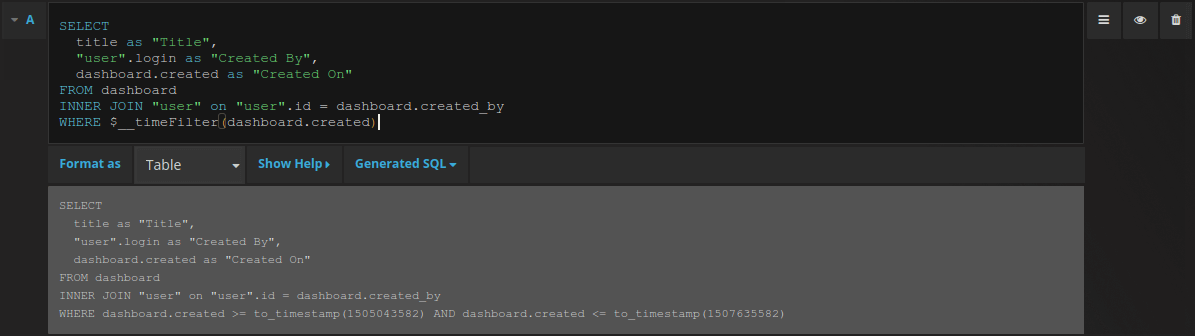
The query:
SELECT
title as "Title",
"user".login as "Created By",
dashboard.created as "Created On"
FROM dashboard
INNER JOIN "user" on "user".id = dashboard.created_by
WHERE $__timeFilter(dashboard.created)You can control the name of the Table panel columns by using regular as SQL column selection syntax.
The resulting table panel:

Time series queries
If you set Format as to Time series, for use in Graph panel for example, then the query must return a column named time that returns either a SQL datetime or any numeric datatype representing Unix epoch.
Any column except time and metric are treated as a value column.
You may return a column named metric that is used as metric name for the value column.
If you return multiple value columns and a column named metric then this column is used as prefix for the series name (only available in Grafana 5.3+).
Resultsets of time series queries need to be sorted by time.
Example with metric column:
SELECT
$__timeGroup("time_date_time",'5m'),
min("value_double"),
'min' as metric
FROM test_data
WHERE $__timeFilter("time_date_time")
GROUP BY time
ORDER BY timeExample using the fill parameter in the $__timeGroup macro to convert null values to be zero instead:
SELECT
$__timeGroup("createdAt",'5m',0),
sum(value) as value,
measurement
FROM test_data
WHERE
$__timeFilter("createdAt")
GROUP BY time, measurement
ORDER BY timeExample with multiple columns:
SELECT
$__timeGroup("time_date_time",'5m'),
min("value_double") as "min_value",
max("value_double") as "max_value"
FROM test_data
WHERE $__timeFilter("time_date_time")
GROUP BY time
ORDER BY timeTemplating
Instead of hard-coding things like server, application and sensor name in you metric queries you can use variables in their place. Variables are shown as dropdown select boxes at the top of the dashboard. These dropdowns makes it easy to change the data being displayed in your dashboard.
Check out the Templating documentation for an introduction to the templating feature and the different types of template variables.
Query Variable
If you add a template variable of the type Query, you can write a PostgreSQL query that can
return things like measurement names, key names or key values that are shown as a dropdown select box.
For example, you can have a variable that contains all values for the hostname column in a table if you specify a query like this in the templating variable Query setting.
SELECT hostname FROM hostA query can return multiple columns and Grafana will automatically create a list from them. For example, the query below will return a list with values from hostname and hostname2.
SELECT host.hostname, other_host.hostname2 FROM host JOIN other_host ON host.city = other_host.cityTo use time range dependent macros like $__timeFilter(column) in your query the refresh mode of the template variable needs to be set to On Time Range Change.
SELECT event_name FROM event_log WHERE $__timeFilter(time_column)Another option is a query that can create a key/value variable. The query should return two columns that are named __text and __value. The __text column value should be unique (if it is not unique then the first value is used). The options in the dropdown will have a text and value that allows you to have a friendly name as text and an id as the value. An example query with hostname as the text and id as the value:
SELECT hostname AS __text, id AS __value FROM hostYou can also create nested variables. Using a variable named region, you could have
the hosts variable only show hosts from the current selected region with a query like this (if region is a multi-value variable then use the IN comparison operator rather than = to match against multiple values):
SELECT hostname FROM host WHERE region IN($region)Using __searchFilter to filter results in Query Variable
Available from Grafana 6.5 and above
Using __searchFilter in the query field will filter the query result based on what the user types in the dropdown select box.
When nothing has been entered by the user the default value for __searchFilter is %.
Important that you surround the
__searchFilterexpression with quotes as Grafana does not do this for you.
The example below shows how to use __searchFilter as part of the query field to enable searching for hostname while the user types in the dropdown select box.
Query
SELECT hostname FROM my_host WHERE hostname LIKE '$__searchFilter'Using Variables in Queries
From Grafana 4.3.0 to 4.6.0, template variables are always quoted automatically. If your template variables are strings, do not wrap them in quotes in where clauses.
From Grafana 4.7.0, template variable values are only quoted when the template variable is a multi-value.
If the variable is a multi-value variable then use the IN comparison operator rather than = to match against multiple values.
There are two syntaxes:
$<varname> Example with a template variable named hostname:
SELECT
atimestamp as time,
aint as value
FROM table
WHERE $__timeFilter(atimestamp) and hostname in($hostname)
ORDER BY atimestamp ASC[[varname]] Example with a template variable named hostname:
SELECT
atimestamp as time,
aint as value
FROM table
WHERE $__timeFilter(atimestamp) and hostname in([[hostname]])
ORDER BY atimestamp ASCDisabling Quoting for Multi-value Variables
Grafana automatically creates a quoted, comma-separated string for multi-value variables. For example: if server01 and server02 are selected then it will be formatted as: 'server01', 'server02'. To disable quoting, use the csv formatting option for variables:
${servers:csv}
Read more about variable formatting options in the Variables documentation.
Annotations
Annotations allow you to overlay rich event information on top of graphs. You add annotation queries via the Dashboard menu / Annotations view.
Example query using time column with epoch values:
SELECT
epoch_time as time,
metric1 as text,
concat_ws(', ', metric1::text, metric2::text) as tags
FROM
public.test_data
WHERE
$__unixEpochFilter(epoch_time)Example query using time column of native SQL date/time data type:
SELECT
native_date_time as time,
metric1 as text,
concat_ws(', ', metric1::text, metric2::text) as tags
FROM
public.test_data
WHERE
$__timeFilter(native_date_time)Alerting
Time series queries should work in alerting conditions. Table formatted queries are not yet supported in alert rule conditions.
Configure the data source with provisioning
It’s now possible to configure data sources using config files with Grafana’s provisioning system. You can read more about how it works and all the settings you can set for data sources on the provisioning docs page
Here are some provisioning examples for this data source.
apiVersion: 1
datasources:
- name: Postgres
type: postgres
url: localhost:5432
database: grafana
user: grafana
secureJsonData:
password: "Password!"
jsonData:
sslmode: "disable" # disable/require/verify-ca/verify-full
maxOpenConns: 0 # Grafana v5.4+
maxIdleConns: 2 # Grafana v5.4+
connMaxLifetime: 14400 # Grafana v5.4+
postgresVersion: 903 # 903=9.3, 904=9.4, 905=9.5, 906=9.6, 1000=10
timescaledb: false

