Plugins 〉LLM


LLM
Grafana LLM plugin
This Grafana application plugin centralizes access to LLMs across Grafana.
It is responsible for:
- storing API keys for LLM providers
- proxying requests to LLMs with auth, so that other Grafana components need not store API keys
- providing Grafana Live streams of streaming responses from LLM providers (namely OpenAI)
- providing LLM based extensions to Grafana's extension points (e.g. 'explain this panel')
Future functionality will include:
- support for more LLM providers, including the ability to choose your own at runtime
- rate limiting of requests to LLMs, for cost control
- token and cost estimation
- RBAC to only allow certain users to use LLM functionality
For users
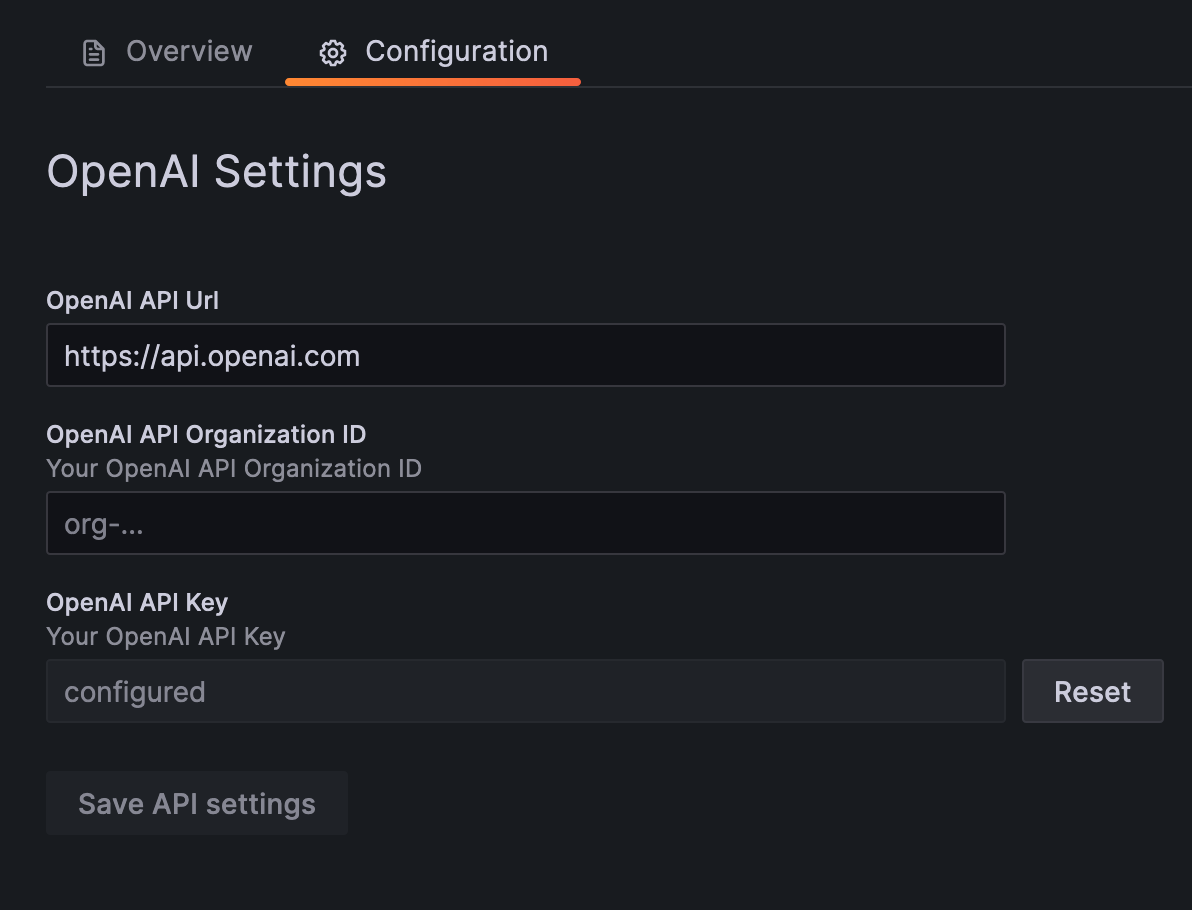
Grafana Cloud: the LLM app plugin is installed for everyone, but LLM features are disabled by default. To enable LLM features, select "Enable OpenAI access via Grafana" in plugin configuration.
OSS or Enterprise: install and configure this plugin with your OpenAI-compatible API key to enable LLM-powered features across Grafana.
For more detailed setup instructions see LLM plugin section under machine learning.
This includes new functionality inside Grafana itself, such as explaining panels, or in plugins, such as automated incident summaries, AI assistants for flame graphs and Sift error logs, and more.
All LLM requests will be routed via this plugin, which ensures the correct API key is being used and requests are routed appropriately.
For plugin developers
This plugin is not designed to be directly interacted with; instead, use the convenience functions
in the @grafana/llm
package which will communicate with this plugin, if installed.
Working examples can be found in the '@grafana/llm README' and in the DevSandbox.tsx class.
First, add the latest version of @grafana/llm to your dependencies in package.json:
{
"dependencies": {
"@grafana/llm": "0.8.0"
}
}
Then in your components you can use the llm object from @grafana/llm like so:
import React, { useState } from 'react';
import { useAsync } from 'react-use';
import { scan } from 'rxjs/operators';
import { llms } from ‘@grafana/llm’;
import { PluginPage } from ‘@grafana/runtime’;
import { Button, Input, Spinner } from ‘@grafana/ui’;
const MyComponent = (): JSX.Element => {
const [input, setInput] = React.useState(’’);
const [message, setMessage] = React.useState(’’);
const [reply, setReply] = useState(’’);
const { loading, error } = useAsync(async () => {
const enabled = await llms.openai.enabled();
if (!enabled) {
return false;
}
if (message === ‘’) {
return;
}
// Stream the completions. Each element is the next stream chunk.
const stream = llms.openai
.streamChatCompletions({
model: llms.openai.Model.BASE
messages: [
{ role: ‘system’, content: ‘You are a helpful assistant with deep knowledge of the Grafana, Prometheus and general observability ecosystem.’ },
{ role: ‘user’, content: message },
],
})
.pipe(
// Accumulate the stream chunks into a single string.
scan((acc, delta) => acc + delta, ‘’)
);
// Subscribe to the stream and update the state for each returned value.
return stream.subscribe(setReply);
}, [message]);
if (error) {
// TODO: handle errors.
return null;
}
return (
<div>
<Input value={input} onChange={(e) => setInput(e.currentTarget.value)} placeholder=“Enter a message” />
<br />
<Button type=“submit” onClick={() => setMessage(input)}>
Submit
</Button>
<br />
<div>{loading ? <Spinner /> : reply}</div>
</div>
);
};
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Grafana Cloud Free
- Free tier: Limited to 3 users
- Paid plans: $55 / user / month above included usage
- Access to all Enterprise Plugins
- Fully managed service (not available to self-manage)
Self-hosted Grafana Enterprise
- Access to all Enterprise plugins
- All Grafana Enterprise features
- Self-manage on your own infrastructure
Install on Grafana Cloud
Plugins can be installed directly from within your Grafana instance or automated using the Cloud API or Terraform.
Learn more about plugin installationMarketplace plugins
This is a paid plugin developed by a marketplace partner. To purchase an entitlement, sign in first, then fill out the contact form.
Get this plugin
This is a paid for plugin developed by a marketplace partner. To purchase entitlement please fill out the contact us form.
What to expect:
- Grafana Labs will reach out to discuss your needs
- Payment will be taken by Grafana Labs
- Once purchased the plugin will be available for you to install (cloud) or a signed version will be provided (on-premise)
Thank you! We will be in touch.
For more information, visit the docs on plugin installation.
Installing on a local Grafana:
For local instances, plugins are installed and updated via a simple CLI command. Plugins are not updated automatically, however you will be notified when updates are available right within your Grafana.
1. Install the Application
Use the grafana-cli tool to install LLM from the commandline:
grafana-cli plugins install The plugin will be installed into your grafana plugins directory; the default is /var/lib/grafana/plugins. More information on the cli tool.
Alternatively, you can manually download the .zip file for your architecture below and unpack it into your grafana plugins directory.
Alternatively, you can manually download the .zip file and unpack it into your grafana plugins directory.
2. Enable it
Next, log into your Grafana instance. Navigate to the Plugins section, found in your Grafana main menu.
Click the Apps tabs in the Plugins section and select the newly installed app.
To enable the app, click the Config tab. Follow the instructions provided with the application and click Enable. The app and any new UI pages are now accessible from within the main menu, as designed by the app creator.
If dashboards have been included with the application, they will attempt to be automatically installed. To view the dashboards, re-import or delete individual dashboards, click the Dashboards tab within the app page.
Changelog
Unreleased
- Update Anthropic model defaults by @joe-elliott
- Base:
claude-sonnet-4-20250514 - Large:
claude-sonnet-4-20250514
- Base:
0.22.1
- feat: relax minimum Grafana version requirement by @sd2k in #724
0.22.0
- feat: add MCP StreamableHTTP server to /mcp endpoint of LLM app by @sd2k in #691
- fix: MCP isEnabled check and improve back-compatibility by @sd2k in #717
0.21.2
- fix: handle case when nested provider differs by @sd2k in #704
- feat: add log line when MCP stream can't be found by @sd2k in #703
0.21.1
- fix: revert token timeout to 10 min by @annanay25 in #698
0.21.0
- feat: export 'enabled' function from mcp module of npm package by @sd2k in #689
- feat: refresh Grafana access token before expiry in Cloud by @sd2k in #688
- refactor: add MCP struct and simplify access token usage by @sd2k in #696
0.20.1
- feat: increase OBO user auth token TTL to 30 min by @annanay25 in #684
0.20.0
- feat: remove MCP feature flag and enable MCP by default by @annanay25 in #670
0.19.3
- feat: upgrade MCP Grafana integration to v0.4.0 by @sd2k in #673
0.19.2
- feat: remove OpenAI Assistant specific code by @csmarchbanks in #663
- feat: enable LLM app to create access tokens on-behalf-of user by @annanay25 in #644
0.19.1
- feat: add Dashboard and Sift tools by @csmarchbanks in #661
- feat: allow customizing the OpenAI API path in the app config page by @sd2k in #656
0.19.0
- feat: upgrade MCP Grafana integration to v0.3.0 by @csmarchbanks in #658
- feat: add asserts tool by @xujiaxj in #657
0.18.0
- feat: add enabled flag to MCPProvider context value and fix infinite loop when MCP is not enabled by @sd2k in #648
0.17.0
- bug: Make sure at least one message has the user role for Anthropic by @edwardcqian in #629
- Update model defaults by @csmarchbanks in #632 and #635:
- Base:
gpt-4o-minitogpt-4.1-mini - Large:
gpt-4otogpt-4.1
- Base:
0.16.0
- chore: bump github.com/grafana/mcp-grafana to 0.2.4 by @sd2k in #618. This adds more tools to retrieve dashboards and OnCall details.
- Switch to Anthropic's OpenAI-compatible API by @gitdoluquita in #617. This PR also adds helper functions to execute tool calls with streaming endpoints.
0.15.0
- removed mentions for public preview from README.md by @Maurice-L-R in #610
- Bump a full minor version to do a release so we can publish a version out of public preview by @SandersAaronD in #612
0.14.1
- fix: improve dev sandbox prompt by @sd2k in #598
- workaround: send publish messages over Websocket by @sd2k in #601
- fix: use public API to publish, where possible by @sd2k in #603
- fix: check for >= 3 args in publish, not === 3 by @sd2k in #604
- chore: bump github.com/grafana/mcp-grafana to 0.2.2 by @sd2k in #605
- chore: add CODEOWNERS by @sd2k in #607
0.14.0
- Allow enabling of dev sandbox via jsonData by @csmarchbanks in #595
- feat: run MCP server in backend using Grafana Live by @sd2k in #574
- feat: add MCP helper functions to the @grafana/llm package by @sd2k in #590
0.13.2
- docs: Add guide for implementing new LLM providers by @gitdoluquita in #573
- Bug: duplicate healthcheck details for backwards compatiblity by @edwardcqian in #585
0.13.1
- update action versions in plugin-release by @csmarchbanks in #577
- fix: update build:all command to also build plugin frontend by @sd2k in #578
0.12.0
- Add support for OpenAI assistant functionality
- Upgrade various dependencies
0.11.0
- Update model defaults:
- Base:
gpt-3.5-turbotogpt-4o-mini - Large:
gpt-4-turbotogpt-4o
- Base:
0.10.9
- Update wording around OpenAI and open models
- Update LLM setup instructions
0.10.8
- Bump various dependencies to fix security issues (e.g. #446)
0.10.7
- Use non-crypto UUID generation for stream request #409
0.10.6
- Fix bug where it was impossible to fix a saved invalid OpenAI url (#405)
0.10.1
- Settings: differentiate between disabled and not configured (#350)
0.10.0
- Breaking: use
baseandlargemodel names instead ofsmall/medium/large(#334) - Breaking: remove function calling arguments from
@grafana/llmpackage (#343) - Allow customisation of mapping between abstract model and provider model, and default model (#337, #338, #340)
- Make the
modelfield optional for chat completions & chat completion stream endpoints (#341) - Don't preload the plugin to avoid slowing down Grafana load times (#339)
0.9.1
- Fix handling of streaming requests made via resource endpoints (#326)
0.9.0
- Initial backend support for abstracted models (#315)
0.8.6
- Fix panic with stream EOF (#308)
0.8.5
- Added a
displayVectorStoreOptionsflag to optionally display the vector store configs
0.8.1
- Add mitigation for side channel attacks
0.7.0
- Refactors repo into monorepo together with frontend dependencies
- Creates developer sandbox for developing frontend dependencies
- Switches CI/CD to github actions
0.6.4
- Fix bug where resource calls to OpenAI would fail for Grafana managed LLMs
0.6.3
- Fix additional UI bugs
- Fix issue where health check returned true even if LLM was disabled
0.6.2
- Fix UI issues around OpenAI provider introduced in 0.6.1
0.6.1
- Store Grafana-managed OpenAI opt-in in ML cloud backend DB (Grafana Cloud only)
- Updated Grafana-managed OpenAI opt-in messaging (Grafana Cloud only)
- UI update for LLM provider selection
0.6.0
- Add Grafana-managed OpenAI as a provider option (Grafana Cloud only)
0.5.2
- Allow Qdrant API key to be configured in config UI, not just when provisioning
0.5.1
- Fix issue where temporary errors were cached, causing /health to fail permanently.
0.5.0
- Add basic auth to VectorAPI
0.4.0
- Add 'Enabled' switch for vector services to configuration UI
- Added instructions for developing with example app
- Improve health check to return more granular details
- Add support for filtered vector search
- Improve vector service health check
0.3.0
- Add Go package providing an OpenAI client to use the LLM app from backend Go code
- Add support for Azure OpenAI. The plugin must be configured to use OpenAI and provide a link between OpenAI model names and Azure deployment names
- Return streaming errors as part of the stream, with objects like
{"error": "<error message>"}
0.2.1
- Improve health check endpoint to include status of various features
- Change path handling for chat completions streams to put separate requests into separate streams. Requests can pass a UUID as the suffix of the path now, but is backwards compatible with an older version of the frontend code.
0.2.0
- Expose vector search API to perform semantic search against a vector database using a configurable embeddings source
0.1.0
- Support proxying LLM requests from Grafana to OpenAI