Netdata: Disks Stats
Per disk metrics overview (+mdadm)
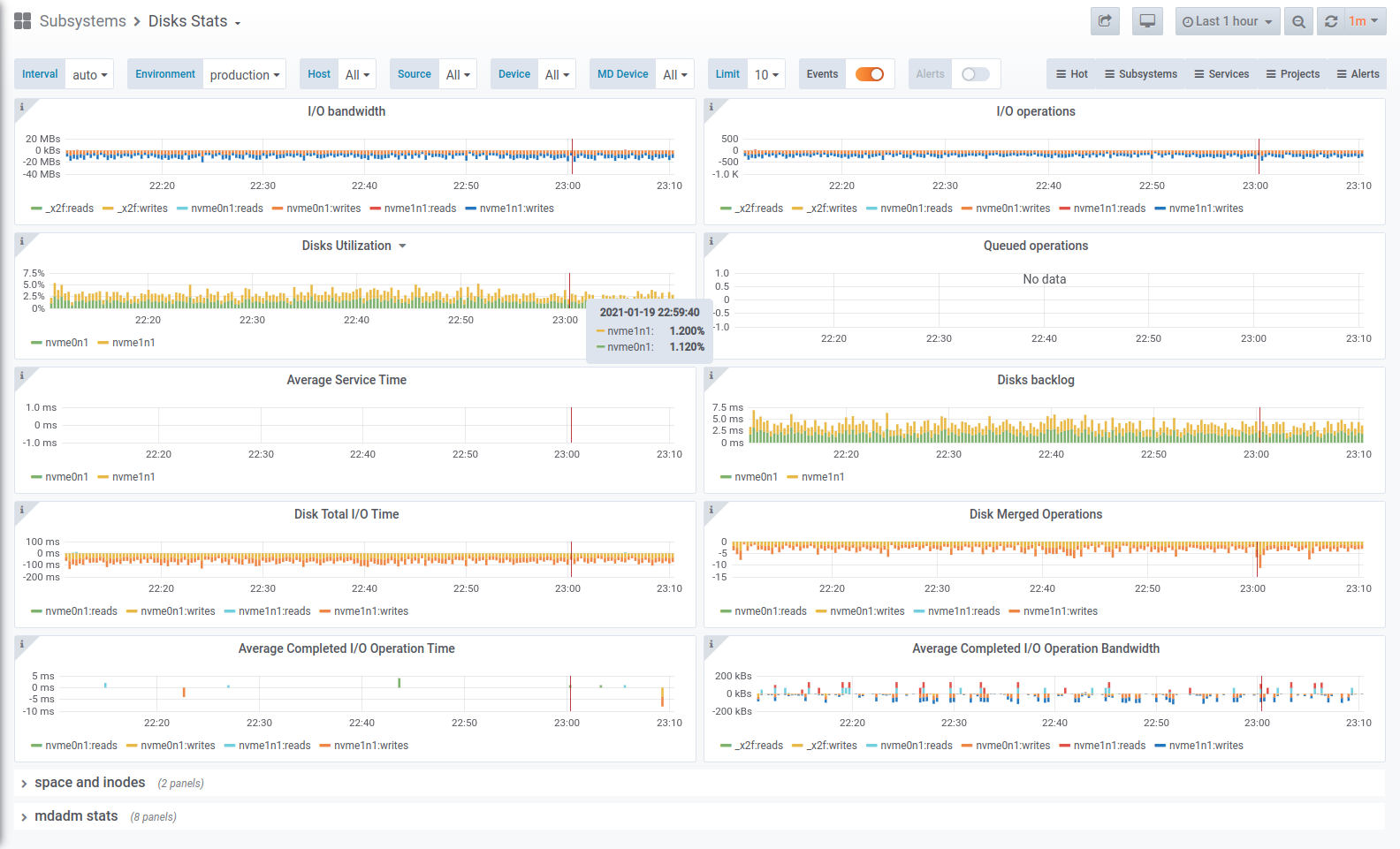
About dashboard
A simple dashboard with an overview for disk related metrics:
- I/O operations and bandwidth
- Disk utilization and backlog
- Queued operations and avergage service time
- Used space and inodes
Plus mdadm related metrics (i.e. software raid):
- current status and amount of faulty devices
- duration and bandwidth of background operations
- devices in check/resync/reshape/recovery statuses
More dashboards for Netdata you can find here.
How to use
Netdata setup
Follow these instructions to setup disks monitoring in Netdata.
Prometheus setup
Please note that you need Netdata as an exporter for metrics. Plus, these labels are mandatory:
- job
- env
- instance
- group
- source
In your prometheus.yml it should look like this:
- job_name: netdata
metrics_path: /api/v1/allmetrics?format=prometheus_all_hosts&source=raw
relabel_configs:
- source_labels: [__address__]
regex: ^(.+)\.\w+:\d+
target_label: instance
action: replace
static_configs:
- targets: [netdata.hostname.here:19999]
labels:
env: production
group: applications
source: newproject
WARNING: Without these labels, this dashboard won't be fully functioning.
Links
License
GPL3
Author
OSSHelp Team, see https://oss.help
Data source config
Collector type:
Collector plugins:
Collector config:
Revisions
Upload an updated version of an exported dashboard.json file from Grafana
| Revision | Description | Created | |
|---|---|---|---|
| Download |