

Loki 2.4 plus simple à opérer, avec un nouveau modèle de déploiement
Grafana Loki est arrivé !
Grafana Lok 2.4 est fourni avec une très longue liste de nouvelles fonctionnalités. Cet article va se focaliser sur les fonctionnalités suivants
- Loki peut maintenant accepter les écritures non ordonnées
- La simplification du déploiement et des opérations avec Loki
N’oubliez pas de consulter la version complète de la release note et bien sûr le guide de mise à jour pour disposer de toutes les dernières infos sur la mise à jour de Loki. Consultez également notre session Pourquoi Loki n’a jamais été aussi facile à utiliser et à opérer du ObservabilityCON 2021.
Prise en charge des logs non ordonnés
La contrainte stricte sur l’ordre des logs dans Loki a longtemps été un défi pour de nombreux utilisateurs Loki, et croyez moi, je vous promets que nous n’avons jamais volontairement compliqué les choses. L’ingestion des données de log rapide et efficace dans la mémoire est un véritable défi !
Aujourd’hui, Loki regroupe les logs entrants en blocs et une fois que ceux-ci atteignent une certaine taille, ils sont compressés. Cependant, une fois que les lignes de log entrantes sont compressées, il devient très difficile d’insérer de nouvelles entrées qui sont reçues de façon non ordonnée, plus particulièrement si cette entrée doit être insérée à un bloc déjà compressé. Décompresser, enregistrer et recompresser est lent et coûteux.
Nous avons exploré plusieurs façons de prendre en charge les logs non ordonnés, tout en essayant de mieux gérer les compromis de performance et de flexibilité en matière de contrainte d’ordre. Et nous avons finalement trouvé une solution dont nous sommes vraiment fiers, qui est maintenant disponible dans la version 2.4. Un article de blog à venir traitera dans les détails de cette solution. Si vous êtes intéressé, vous pouvez aussi consulter le document de conception.
En bref, nous sommes ravis d’avoir finalement pu clore ce problème et ainsi simplifier la vie de nombreux utilisateurs de Loki en leur permettant d’envoyer des logs non ordonnés à Loki !
Un déploiement simple et évolutif
Je voudrais ensuite parler du travail que nous avons fait pour faire en sorte que Loki soit plus facile à utiliser. Nous disions depuis longtemps à quel point il est facile de se lancer sur Loki, en le faisant fonctionner comme un processus unique capable d’ingérer et de servir vos logs.
Mais qu’en est-il si vous voulez exécuter Loki dans une configuration hautement disponible ? Ou si vous voulez profiter de la parallélisation de requête souvent évoquée dans nos exposés de conférence et webinaires ? Vous vous êtes rapidement retrouvé aux limites de ce que pouvait offrir le binaire unique et avez probablement fixé d’un regard épuisé le Helm ou jsonnet d’une configuration microservices Loki.
Ne vous y méprenez pas, on adore les microservices. C’est le système que nous utilisons pour exploiter Loki à Grafana Labs, et il offre la plus grande flexibilité et la plus grande configurabilité ainsi que le meilleur potentiel pour atteindre des centaines de Téraoctets de logs par jour. Mais on doit bien reconnaître aussi que c’est notre travail de faire tourner Loki, et que les microservices sont complexes. Pour beaucoup, ce niveau de complexité est à la fois inutile et constitue un obstacle à l’adoption de Loki.
C’est pourquoi nous nous sommes vraiment efforcés de créer un mode hybride que nous appelons le déploiement simple et évolutif. L’idée est la suivante : reprendre la simplicité d’exécution de Loki, comme binaire unique, mais introduire une voie facile offrant haute disponibilité et évolutivité.
Étape 1 : Binaire unique / Mode Monolithique
Aussi connu sous le nom de mode monolithique, c’est la façon la plus simple de se lancer sur Loki. Et nous avons apporté plusieurs améliorations significatives à ce mode de fonctionnement. Tout d’abord, le mode binaire unique exécute maintenant un frontend de requête qui est le composant responsable du découpage et du sharding des requêtes. Désormais un Loki déployé en binaire unique peut aussi paralléliser des requêtes !
Deuxièmement, le Loki en binaire unique peut aussi être mis à l’échelle en ajoutant plus d’instances et en les connectant à un hash ring. Nous avons également pris soin de nous assurer que le compacteur est exécuté de manière unique automatiquement.
L’ajout de plus d’instances permet de sharder les écritures entrantes sur plus de processus et de fournir plus de CPU pour plus de parallélisation de requêtes, ce qui vous permet de facilement mettre à l’échelle une instance binaire Loki unique pour les performances et de permettre un temps d’exécution à haute disponibilité.
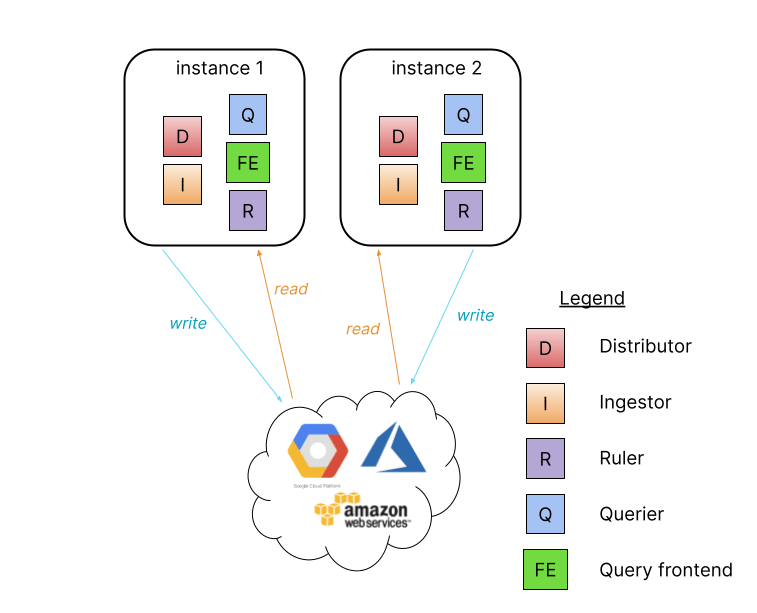
Remarque : Le compacteur qui utilisera le hash ring pour choisir une seule instance pour exécuter des compactions n’est pas représenté ci-dessus.
Étape 2 : un déploiement simple et évolutif
Ce mode est une passerelle entre le fonctionnement de Loki en mode binaire/monolithique et les microservices à part entière. L’idée est de donner aux utilisateurs plus de flexibilité dans la mise à l’échelle et d’avoir l’avantage de séparer la voie de lecture et la voie d’écriture dans Loki.
Ceci devrait être particulièrement attrayant pour quelqu’un qui veut utiliser Loki en dehors de Kubernetes.
Il fonctionne en prenant le même binaire/image et en passant un paramètre de configuration -target=read et -target=write.
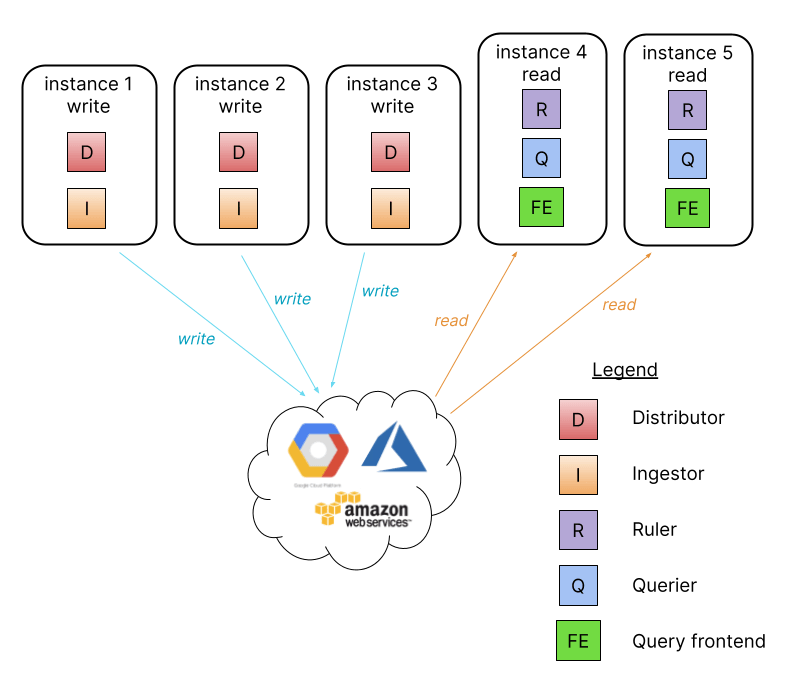
Remarque : Le compacteur qui utilisera le hash ring pour choisir une seule instance de lecture pour exécuter des compactions n’est pas représenté ci-dessus.
Ces nouveaux paramètres séparent les composants internes nécessaires pour les lectures/écritures dans des processus séparés. Cela facilite la mise à l’échelle et en la surveillance des chemins de lecture et d’écriture. Ceci vous permet également d’ajouter et de supprimer des instances de lecture pour augmenter/diminuer le nombre de parallélismes de requêtes que Loki. Vous serez en mesure de mettre à l’échelle les performances de lecture à la demande comme dans le mode microservice.
Étape 3 : Microservices
Pour ceux qui veulent disposer du meilleur en matière de flexibilité, d’observabilité et de performance, Loki peut toujours être exécuté comme avant, sous forme de microservices de composants individuels.
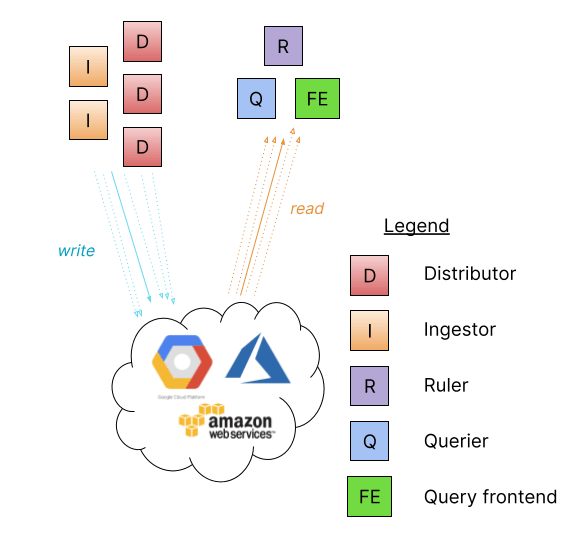
Je crois, cependant, que beaucoup de personnes trouveront que ce mode n’est pas nécessaire, et que l’augmentation du nombre d’éléments mobiles constituera peut-être un obstacle plutôt qu’un avantage. Nous vous laisserons le soin d’en décider. Nous sommes ravis de vous offrir plus d’options pour utiliser Loki de la manière qui vous convienne le mieux !
Pour finir…
L’équipe Loki a travaillé très dur pour faire de la v2.4 la version la plus simple à utiliser de Loki. Nous mettons à jour notre documentation Grafana Loki. Nous aurons bientôt plus d’articles et d’exemples sur l’exécution de Loki dans ces différents modes !
La façon la plus simple de se lancer avec Grafana Loki, c’est Grafana Cloud, avec des forfaits gratuits et payants qui conviennent à chaque cas d’utilisation. Si vous n’utilisez pas déjà Grafana Cloud, inscrivez-vous gratuitement aujourd’hui.