
Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Getting started with Tempo
You can use Grafana Cloud to avoid installing, maintaining, and scaling your own instance of Grafana Tempo. Create a free account to get started, which includes free forever access to 10k metrics, 50GB logs, 50GB traces, 500VUh k6 testing & more.
Distributed tracing visualizes the lifecycle of a request as it passes through a set of applications. There are a few components that must be configured in order to get a working distributed tracing visualization.
This document discusses the four major pieces necessary to build out a tracing system: Instrumentation, Pipeline, Backend and Visualization. If one were to build a diagram laying out these pieces it may look something like this:
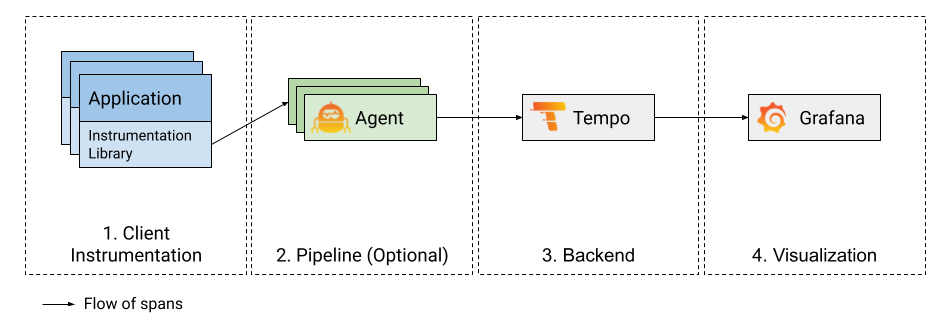
1. Instrumentation
Instrumentation SDKs
The first building block to a functioning distributed tracing visualization pipeline is client instrumentation, which is the process of adding instrumentation points in the application that creates and offloads spans.
Below is a list of the most popular frameworks used for client instrumentation. Each of these have SDKs in most commonly used programming languages and you should pick one according to your application needs.
OpenTelemetry Auto Instrumentation
Some languages have support for auto-instrumentation. These libraries capture telemetry information from a client application with minimal manual instrumentation of the codebase.
- OpenTelemetry Java Autoinstrumentation
- OpenTelemetry .NET Autoinstrumentation
- OpenTelemetry Python Autoinstrumentation
Note: Check out our instrumentation examples to learn how to instrument your favourite language for distributed tracing.
2. Pipeline (Grafana Agent)
Once your application is instrumented for tracing, the next step is to send these traces to a backend for storage and visualization. It is common to build a tracing pipeline that offloads spans from your application, buffers them and eventually forwards them to a backend. Tracing pipelines are optional (most clients can send directly to Tempo), but you will find that they become more critical the larger and more robust your tracing system is.
The Grafana Agent is a service that is deployed close to the application, either on the same node or within the same cluster (in kubernetes) to quickly offload traces from the application and forward them to a storage backend. It also abstracts features like trace batching and backend routing away from the client.
To learn more about the Grafana Agent and how to set it up for tracing with Tempo, refer to this blog post.
Note: The OpenTelemetry Collector / Jaeger Agent can also be used at the agent layer. Refer to this blog post to see how the OpenTelemetry Collector can be used with Grafana Cloud Tempo.
3. Backend (Tempo)
Grafana Tempo is an easy-to-use and high-scale distributed tracing backend used to store and query traces. The purpose of the tracing backend is to store and retrieve traces on demand.
Getting started with Tempo is easy.
- If you’re looking for examples of how to get started with Tempo, check out the examples topic.
- For production workloads, refer to the deployment section.
Note: The Grafana Agent is already set up to use Tempo. Refer to the configuration and example for details.
4. Visualization (Grafana)
Grafana has a built in Tempo datasource that can be used to query Tempo and visualize traces. For more information refer to the Tempo data source topic.
See here for details about Grafana configuration.
Was this page helpful?
Related resources from Grafana Labs


