What's new from Grafana Labs
Grafana Labs products, projects, and features can go through multiple release stages before becoming generally available. These stages in the release life cycle can present varying degrees of stability and support. For more information, refer to release life cycle for Grafana Labs.
Loading...
Area of interest:
Cloud availability:
Cloud editions:
Self-managed availability:
Self-managed editions:
No results found. Please adjust your filters or search criteria.
There was an error with your request.
Debugging frontend errors just got easier. From the Errors drawer in Grafana Cloud Frontend Observability, click the Analyze button to kick off Grafana Assistant’s root cause analysis investigation.

Saved queries now supports role-based access control (RBAC), giving teams a clearer and safer way to share and manage queries.
Saved queries are now shared by default: all users with access can reuse them, while only users with the Writer role can create, edit, or delete them. This replaces the previous per-query sharing checkbox with consistent, role-based permissions.
You can now configure default columns for Logs Drilldown directly from the plugin configuration page.
This new capability allows administrators to define which fields (or columns) are displayed by default based on the selected set of labels. Instead of relying on a static column setup, the logs view can now support a pre-configured default state per service, or set of services, ensuring users immediately see the most relevant information for their use case.
You can now save a log exploration in Logs Drilldown and return to it later.
Saved explorations include your active filters, so you don’t have to recreate the same view each time you investigate an issue.
Pending periods have been added to NoData and Error alert states in Alerting to help reduce noise by preventing notifications triggering after first evaluation and giving you more granular control. Now, NoData and Error alerts honor the same pending period as regular alerts. Notifications are sent only after the pending period elapses.
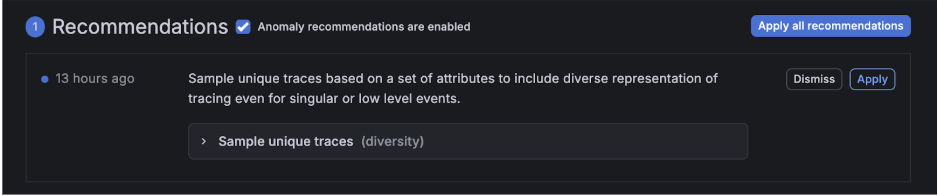
Easily and confidently optimize trace storage while ensuring even your smallest sets of traces are represented.
Diversity sampling captures at least one trace for each unique trace combination (fingerprint) within a fixed time window. These combinations are defined by attributes such as service, route, and status code. With this baseline coverage in place, you can reduce probabilistic sampling rates and avoid creating and managing additional policies just to make sure developers find the traces they need.
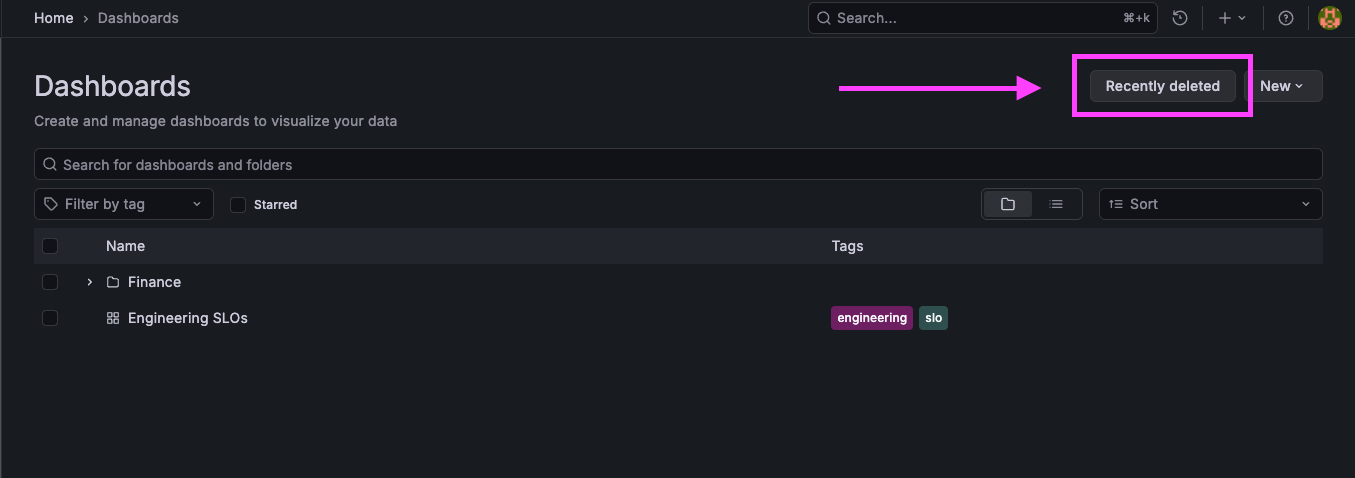
Restore Dashboards is in Public Preview! We would love your feedback, you can share it here.
You can restore dashboards you’ve deleted, no support ticket needed. With the new Recently deleted view, accidentally removing a dashboard no longer means lost work or rebuilding panels from scratch.
Kubernetes costs are notoriously hard to track and optimize. New Overview and Savings tabs in Kubernetes Monitoring show:
- Spending across the past 60 days
- Potential savings for the next 30 days
- How much you can save by optimizing resources
- Recommendations from Grafana Assistant about your data


Git Sync in Grafana lets you manage your dashboards as code as JSON files stored in GitHub. You and your team can use it to version control, collaborate, and automate deployments efficiently.
Using the Google Sheets data source in Grafana is all about speed and flexibility, but one recurring friction point was having to reselect the same spreadsheet every time the data source was used.
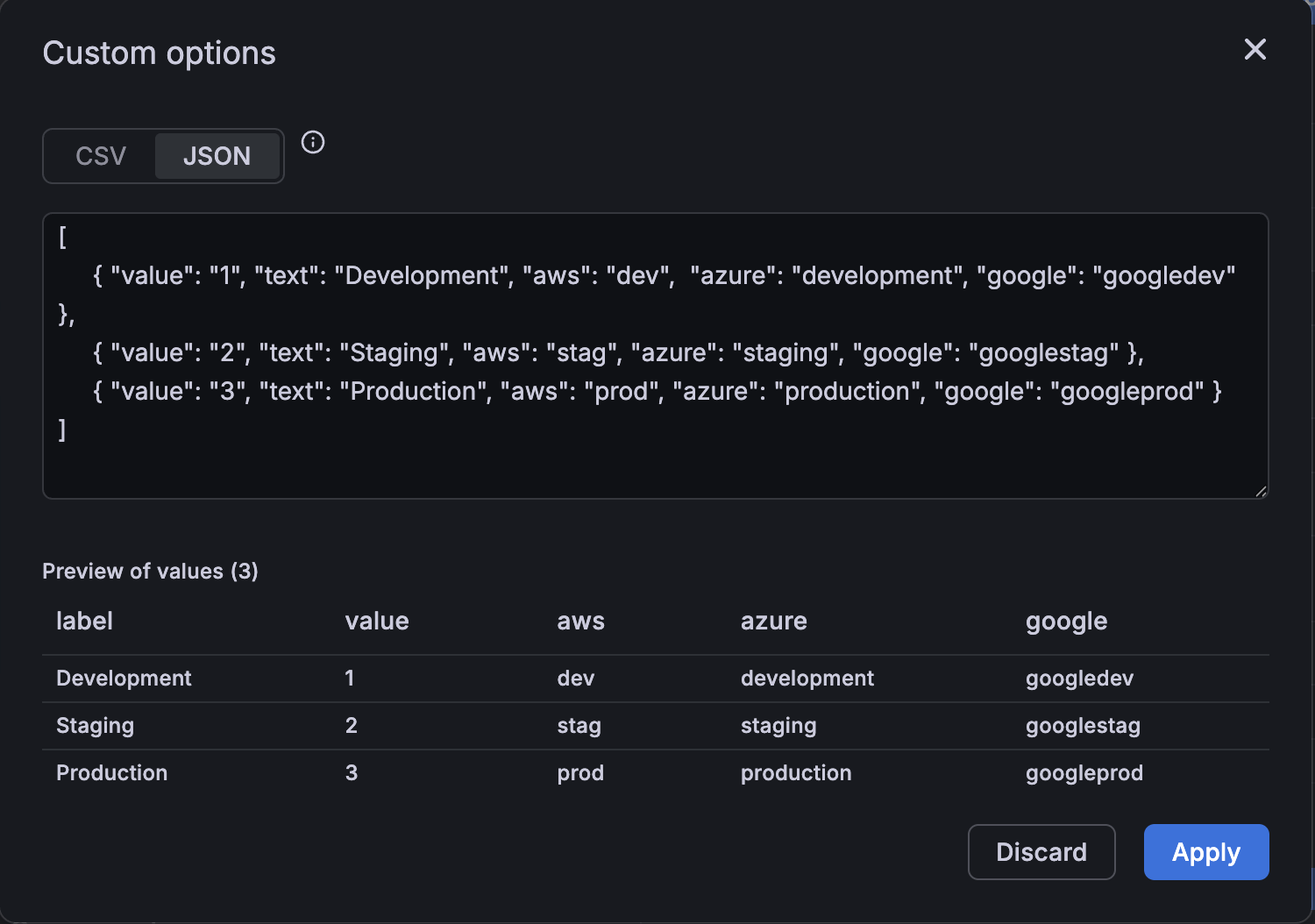
We’re excited to introduce multi-property variables—a simple, powerful way to let you map several identifiers to a single variable. Instead of creating and keeping multiple variables for the same logical concept in sync (for example, an environment identified as “dev” vs “development”), you can map all of those identifiers to one variable and then reference any property you need in panels and queries. This reduces dashboard clutter and makes multi-source dashboards much easier to author and maintain.
Security teams using CrowdStrike’s Falcon NextGen SIEM now have a direct path to visualize their security data in Grafana. With dedicated NGSIEM mode, connect via OAuth2 client credentials and bring your security investigations and incident data directly into your existing Grafana dashboards for unified observability and threat analysis. Get started by selecting NGSIEM mode in your data source configuration and learn more in the configuration documentation.
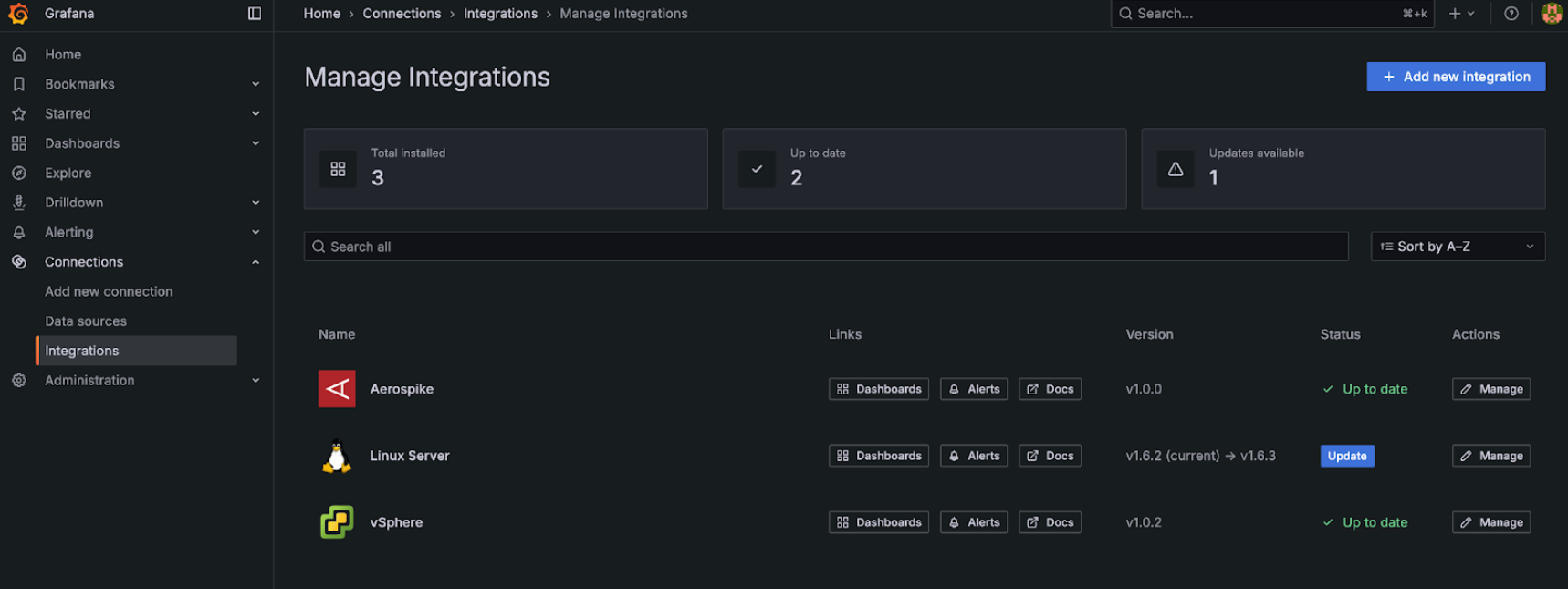
If you are using more than one integration in you observability fleet this new functionality will help you understand and manage their state.
Never wait for a login to secure your stack
You can now automate your entire user lifecycle and team structures directly from your identity provider (IdP). By moving SCIM from public preview to general availability, we’ve removed the “first login” bottleneck, allowing centralized operators to provision, configure, and secure users before they even open the app.