
Monitor an app with Kubernetes Monitoring
Introduction
This tutorial shows how to deploy an instrumented three-tier (data layer, app logic layer, load-balancing layer) web application into a Kubernetes cluster, and leverage Grafana Cloud’s built-in Kubernetes Monitoring feature to monitor the application.
In this tutorial, you will:
- Deploy the TNS sample app into your Kubernetes cluster.
- Deploy a prebuilt dashboard to your Grafana Cloud instance to visualize the app’s performance metrics.
- Roll out Grafana Agents to collect metrics, logs, and events from the Kubernetes cluster.
- Configure these agents to collect metrics, logs, and traces (including exemplars) from the TNS app.
- Learn how to navigate from metrics, to logs, to traces and back using Grafana’s powerful correlation features.
- Learn how to use the Kubernetes Cluster Navigator to explore your cluster’s running workloads, jumping from Pods to dashboards and logs.
Before you begin
To complete this tutorial, you need access to:
- A Kubernetes, K3s, or OpenShift cluster
- A Grafana Cloud stack, optionally with exemplar support enabled.
Deploy and configure Grafana Agent
Follow this procedure to roll out Grafana Agent into your Kubernetes cluster. To make deploying Agent easier, Grafana Cloud provides preconfigured manifests for you to download and modify.
To deploy Grafana Agent:
Navigate to your Grafana Cloud instance.
Click Observability in the left-side menu and select Kubernetes.
Click Start sending data, then click Install dashboards and alert rules to install the prebuilt set of Kubernetes dashboards and alerts.
Click Agent configuration instructions and check that the items listed under Prerequisites are met.
Under Metrics & Events, replace
defaultin the Namespace field with your namespace.The Agent ConfigMap is updated with your namespace.
Click Copy to clipboard and paste the Agent ConfigMap in an editor.
By default, the ConfigMap only scrapes cluster metrics endpoints like the
/cadvisorand/kubeletendpoints. You need to configure the ConfigMap to scrape/metricsendpoints of Pods deployed in your cluster by following the next step.In the ConfigMap, add the following scrape job stanza:
. . . relabel_configs: - action: keep regex: kube-state-metrics source_labels: - __meta_kubernetes_pod_label_app_kubernetes_io_name # New scrape job below - job_name: integrations/kubernetes/pod-metrics kubernetes_sd_configs: - role: pod relabel_configs: - action: drop regex: kube-state-metrics source_labels: - __meta_kubernetes_pod_label_app_kubernetes_io_name - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: pod - source_labels: ['__meta_kubernetes_namespace', '__meta_kubernetes_pod_label_name'] action: 'replace' separator: '/' target_label: 'job' replacement: '$1' - source_labels: ['__meta_kubernetes_pod_container_name'] action: 'replace' target_label: 'container' . . .This scrape job attempts to scrape all containers (and ports) running in your cluster at
/metrics, drops any kube-state-metrics (since you’re already picking these up in another scrape job), and performs some relabeling (settingjob,pod,namespace, etc. labels).To learn more about configuring scrape jobs, see the Prometheus scrape config documentation. You can adjust this generic catchall stanza to restrict scraping to a given namespace, workload label, drop additional metrics, and more using different config directives.
Configure Grafana Agent to send exemplars to Grafana Cloud. To do this, add the following to the ConfigMap:
. . . configs: - name: integrations remote_write: - url: <your_prometheus_metrics_endpoint> basic_auth: username: <your_prometheus_metrics_user> password: <your_prometheus_metrics_api_key> # Add the following line send_exemplars: true . . .
You must contact Support to enable exemplars in your Grafana Cloud instance.
Deploy ConfigMap into your cluster.
Follow the remaining steps in the K8s Monitoring instructions to deploy the following into the namespace that you specified:
- An Agent StatefulSet
- kube-state-metrics
- An Agent ConfigMap & DaemonSet to tail container logs
Deploy the Agent to collect traces by following the Ship Kubernetes traces using Grafana Agent guide.
Be sure to fill in the required
remote_writecredentials. Your Tempo endpoint URL should look something liketempo-us-central1.grafana.net:443.Important: Without an Agent to collect traces, the demo app will not start, so be sure to complete this step.
When you have finished deploying the telemetry collectors, your running K8s Pods should look something like this:
NAME READY STATUS RESTARTS AGE grafana-agent-0 1/1 Running 0 3m grafana-agent-logs-lcpjd 1/1 Running 0 2m44s grafana-agent-logs-pc9sp 1/1 Running 0 2m44s grafana-agent-logs-qtjzq 1/1 Running 0 2m44s grafana-agent-traces-7775575d6d-qcrmq 1/1 Running 0 21s ksm-kube-state-metrics-58ccd7456c-487c9 1/1 Running 0 2m50s
Deploy the TNS app
With the telemetry collectors up and running, you can now deploy the TNS demo app into your Kubernetes cluster. The TNS GitHub repository contains Kubernetes manifests (written in Jsonnet) that deploys the app’s required components. You do not need to learn Jsonnet to follow this guide and to inspect the manifests and code before deploying the components. The repo also contains more information about the app and how it has been instrumented to work with Grafana Cloud. It also contains the app source code.
To deploy the TNS app:
To deploy the app, run the following command:
kubectl apply -f https://raw.githubusercontent.com/grafana/tns/main/production/k8s-yamls-cloud/app-full.yamlYou can inspect the YAML manifests before deploying the app into your cluster. This deploys the app Pods and Services into the
tns-cloudnamespace of your cluster and creates the namespace if it doesn’t exist.Inspect deployment status using
kubectl:kubectl get all -n tns-cloudForward a port to a local web browser:
kubectl port-forward -n tns-cloud service/app 8080:80Navigate to
https://localhost:8080in your web browser to see the demo app in action.
With the instrumented demo app and load generator up and running, you can now navigate to Grafana Cloud to query your app logs, visualize its metrics, and inspect its trace data.
Correlate metrics, logs, and traces
At this point, the demo app and load generator are instrumented, up and running, and your telemetry collectors are forwarding metrics, log, trace, and event data to Grafana Cloud. Before exploring some of Grafana Cloud’s built-in features, install a custom prebuilt app dashboard that demonstrates some core Grafana features.
To correlate telemetry data:
In your Grafana instance, click Dashboards.
Click New and select Import in the dropdown.
Enter
16491in the ID field, and click Load.Click Import to import the dashboard.
Navigate to the dashboard.
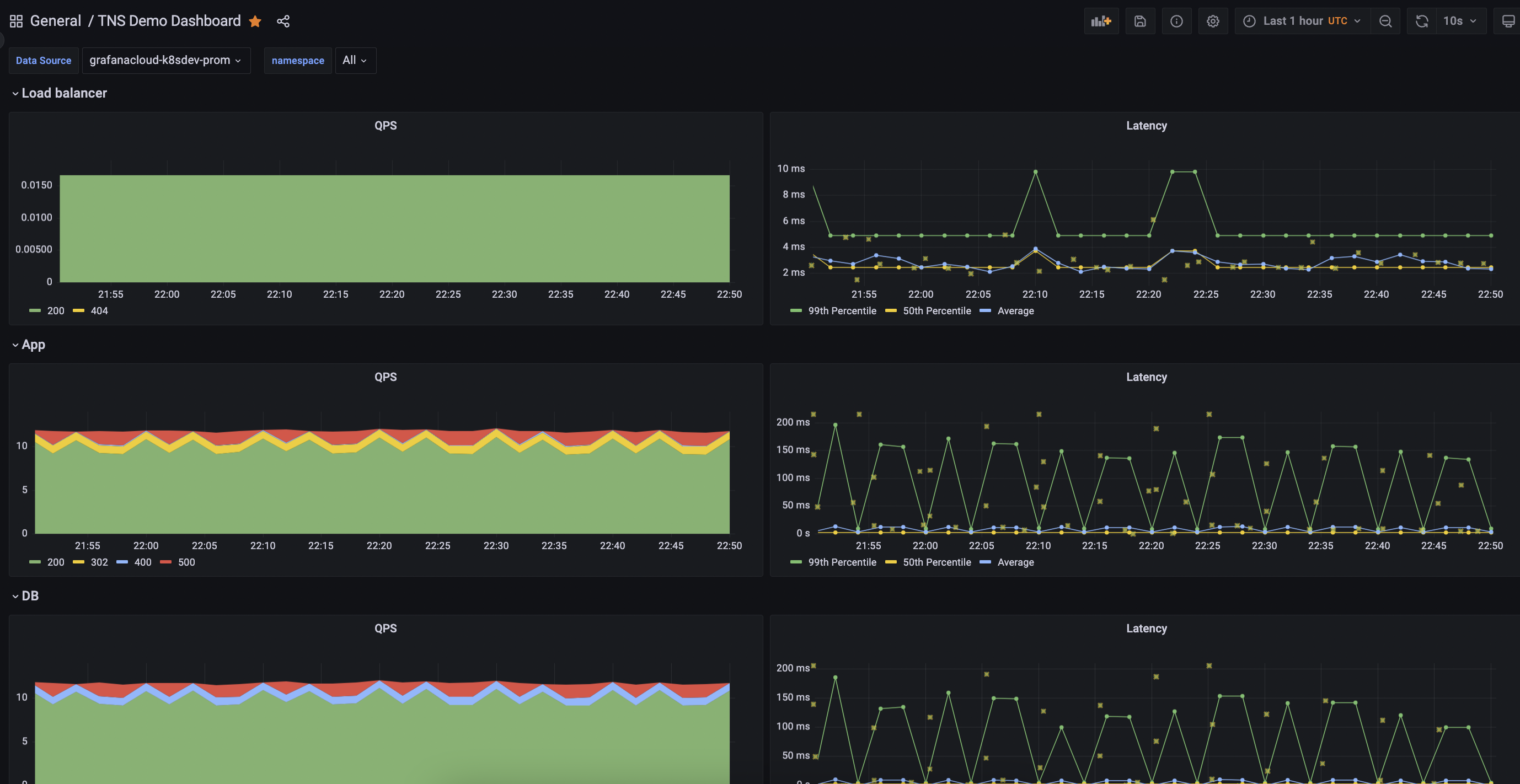
The following dashboard displays:
![TNS Dashboard]()
{{% admonition type=“note” %}} If you do not see the yellow dots (exemplars), make sure that exemplars are enabled. {{% /admonition %}} For more information, refer to Configure Grafana Agent.
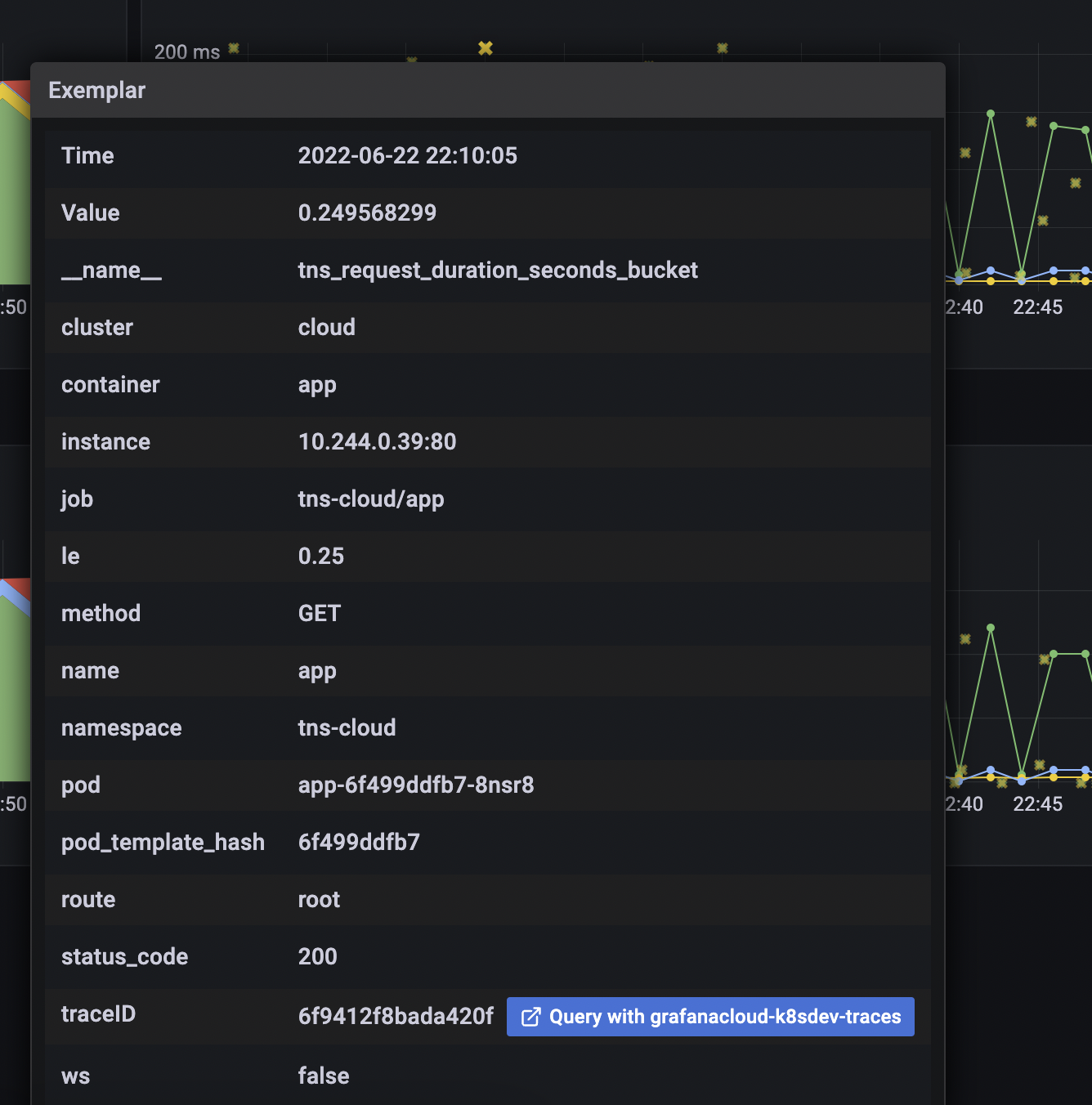
Click an exemplar to jump to a trace for a particularly slow request:
![Exemplar]()
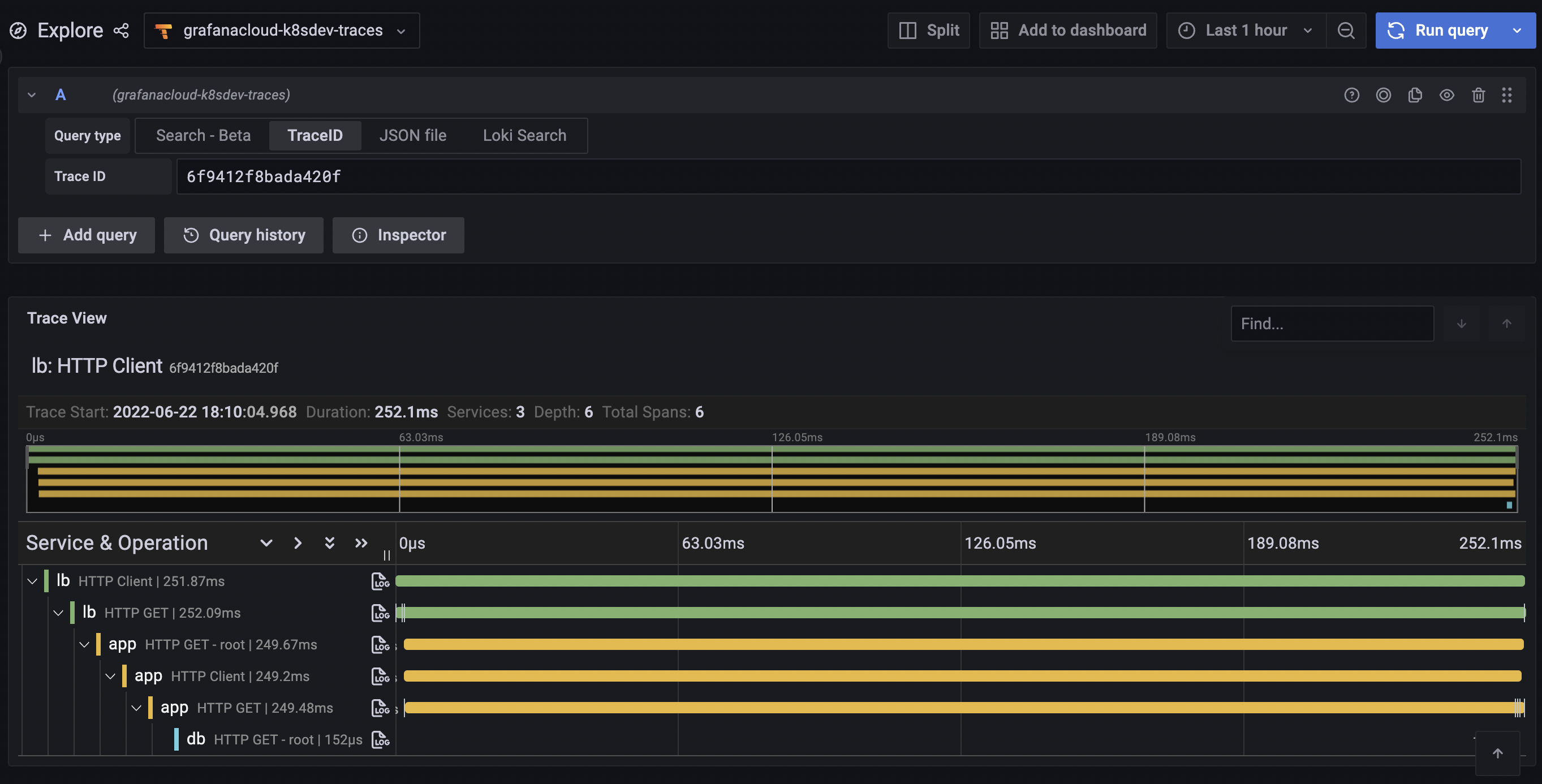
![Trace]()
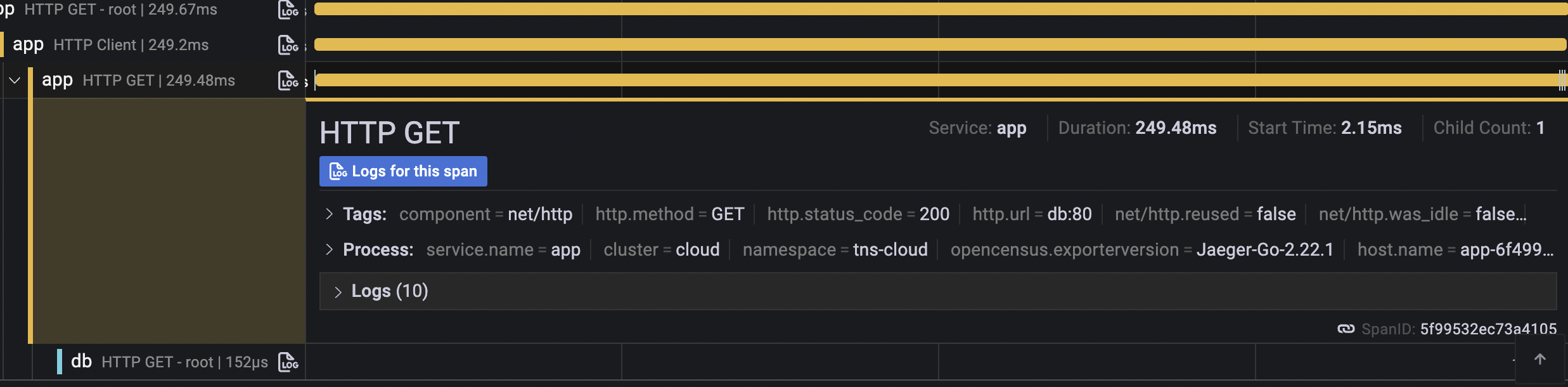
From here, jump to logs to view the problematic span:
![Trace to logs]()
![Logs]()
Click Show context on a log line to see the surrounding log context.
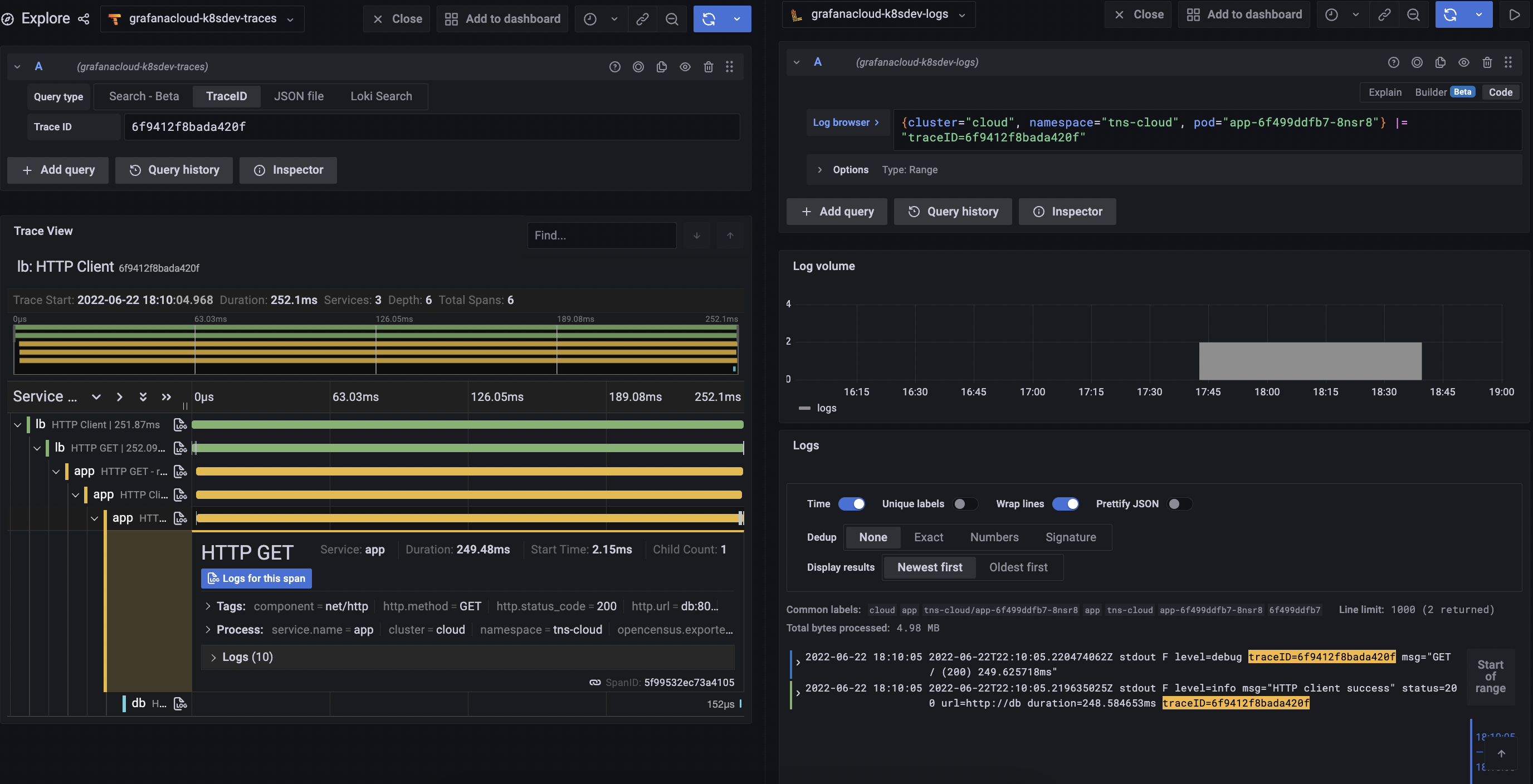
Navigate between metrics, logs, and traces
The ability to jump from metrics, to traces, to logs, and back is an extremely powerful feature that helps you quickly resolve production issues and reduce mean time to recovery (MTTR). You can also jump to logs from metrics using the Explore view.
To navigate between metrics, logs, and traces:
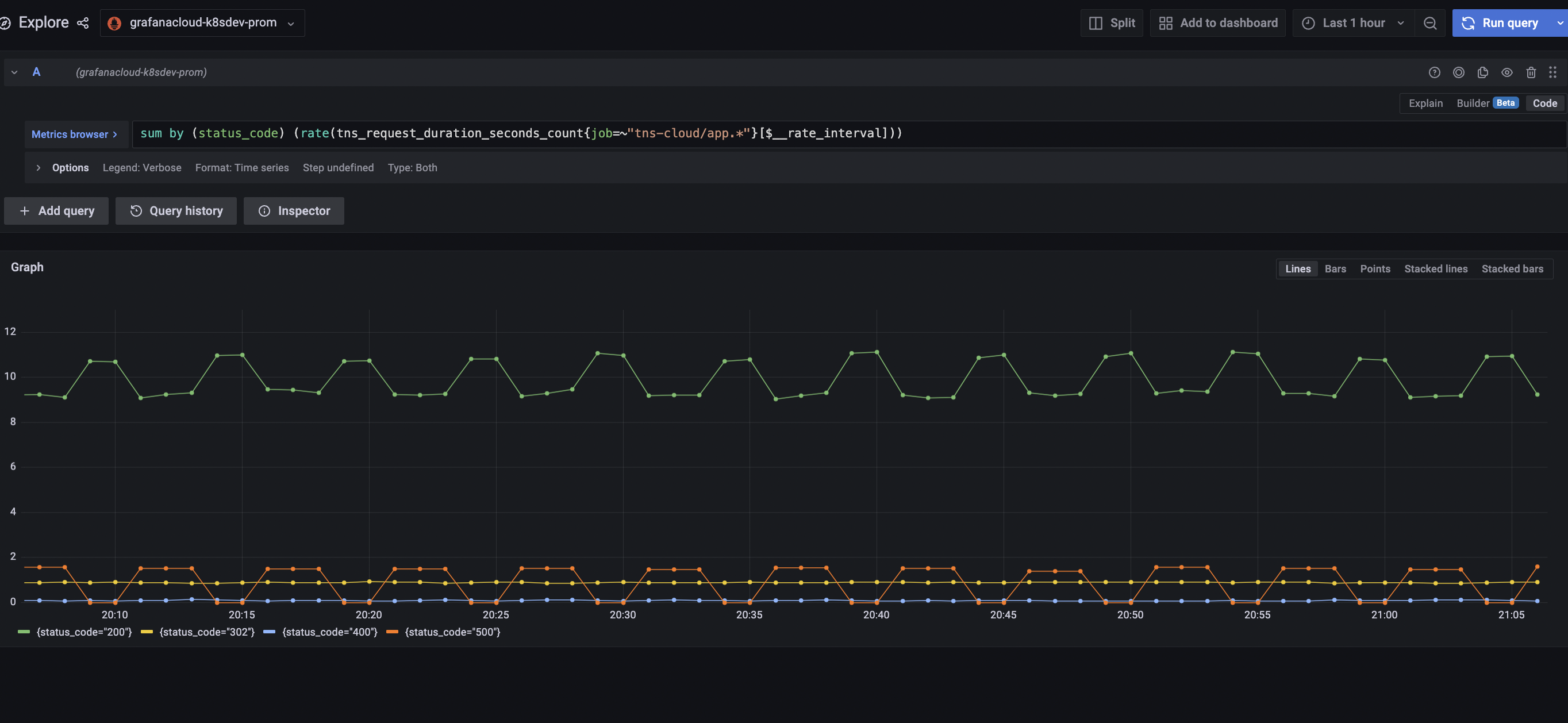
Enter the following PromQL query, ensuring that you select the correct Prometheus data source:
sum by (status_code) (rate(tns_request_duration_seconds_count{job=~"tns-cloud/app.*"}[$__rate_interval]))The following graph displays:
![PromQL Query]()
Click Split at the top of the window, and select the correct Loki data source in the dropdown:
![Loki Dropdown]()
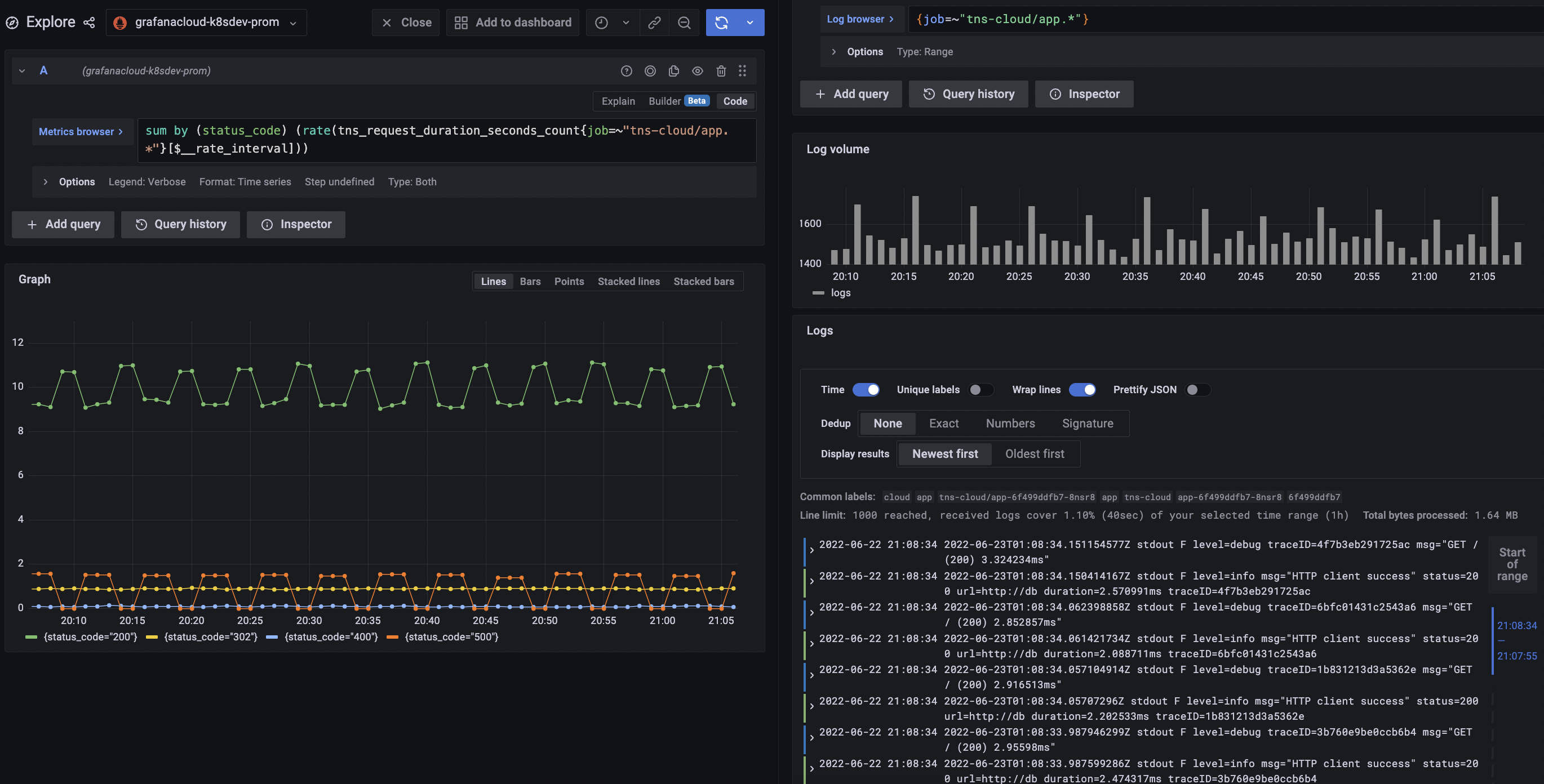
Grafana carries over the labels selected in the PromQL query and pre-populates a LogQL query with the same labels, so that you can quickly jump from Prometheus metrics queries to the corresponding Loki logs data relevant to the metrics graph you’re analyzing:
![Logs Result]()
To learn more about these features, see the following videos:
- Correlate your metrics, logs, and traces with the Grafana Stack
- Correlate your metrics, logs, and traces with the curated OSS observability stack from Grafana Labs
Navigate cluster workloads
Another way to explore your Kubernetes workloads is to use the cluster navigation feature.
To navigate cluster workloads:
In Grafana, click Observability in the left-side menu and select Kubernetes.
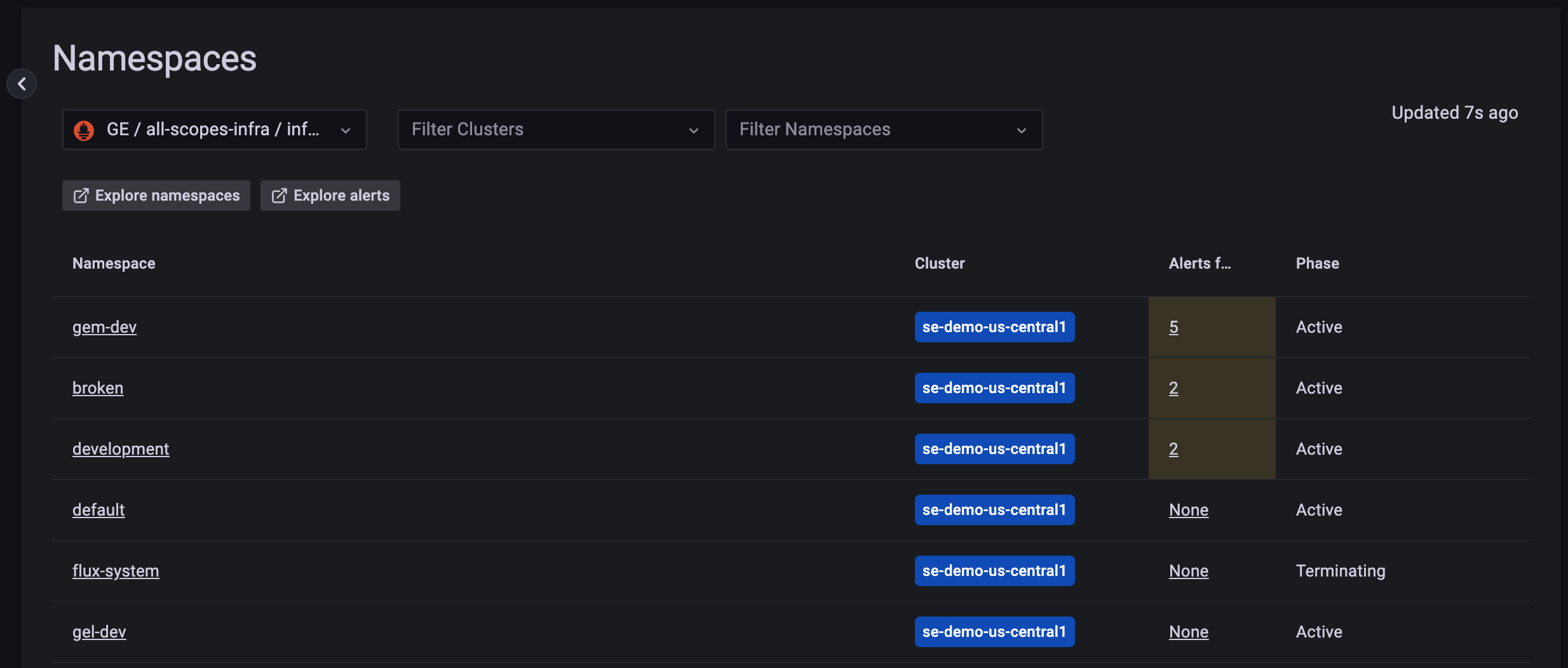
The Namespaces view displays, where you can navigate clusters.
![Cluster nav]()
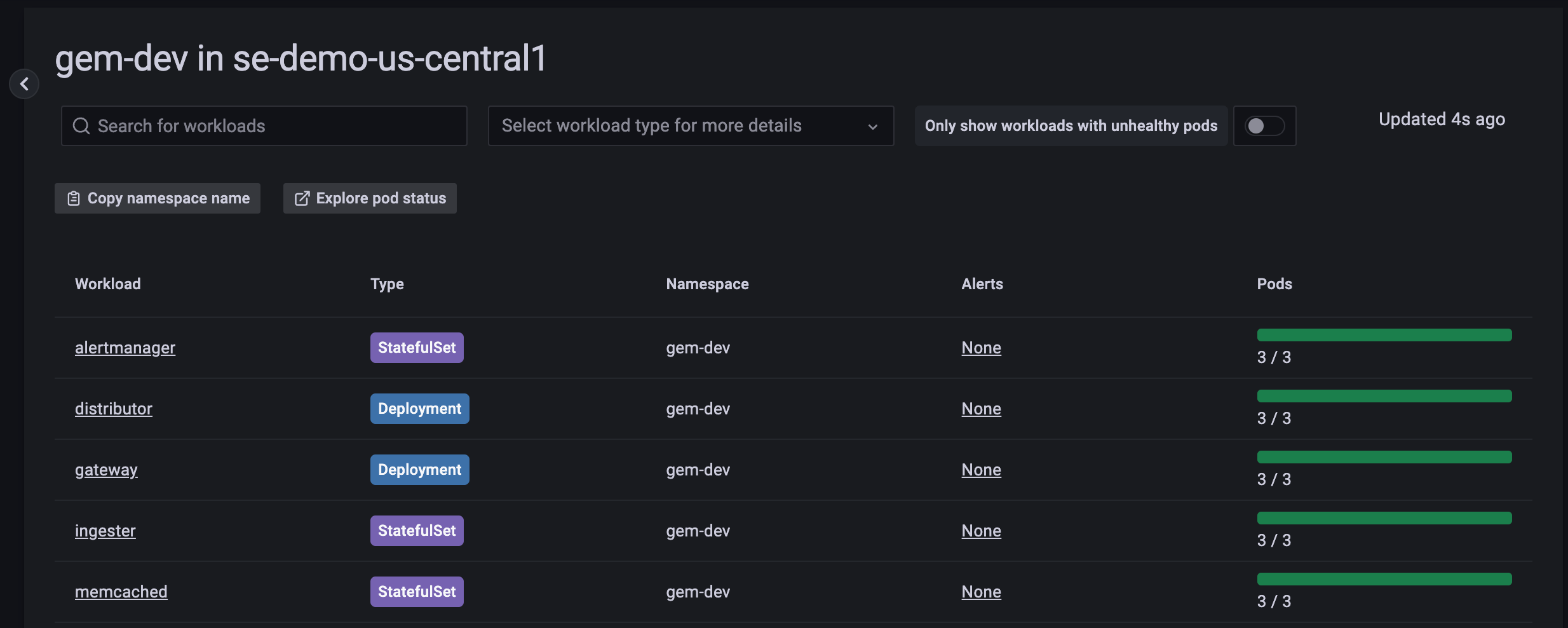
Click into a particular namespace to begin exploring workloads.
![Workload nav]()
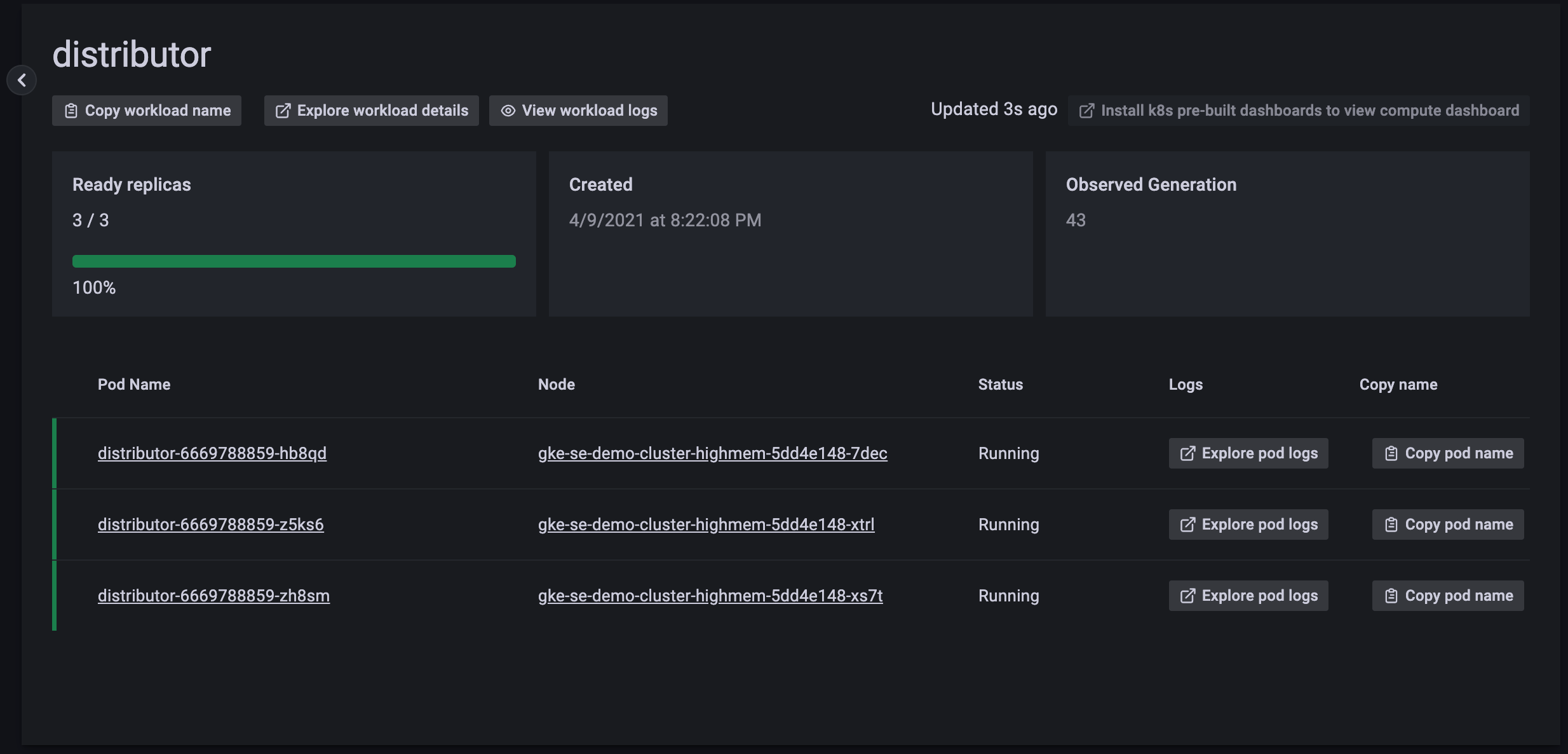
From here, you can see any firing alerts, the health of running Pods, and can further drill down into a given ReplicaSet.
![ReplicaSet nav]()
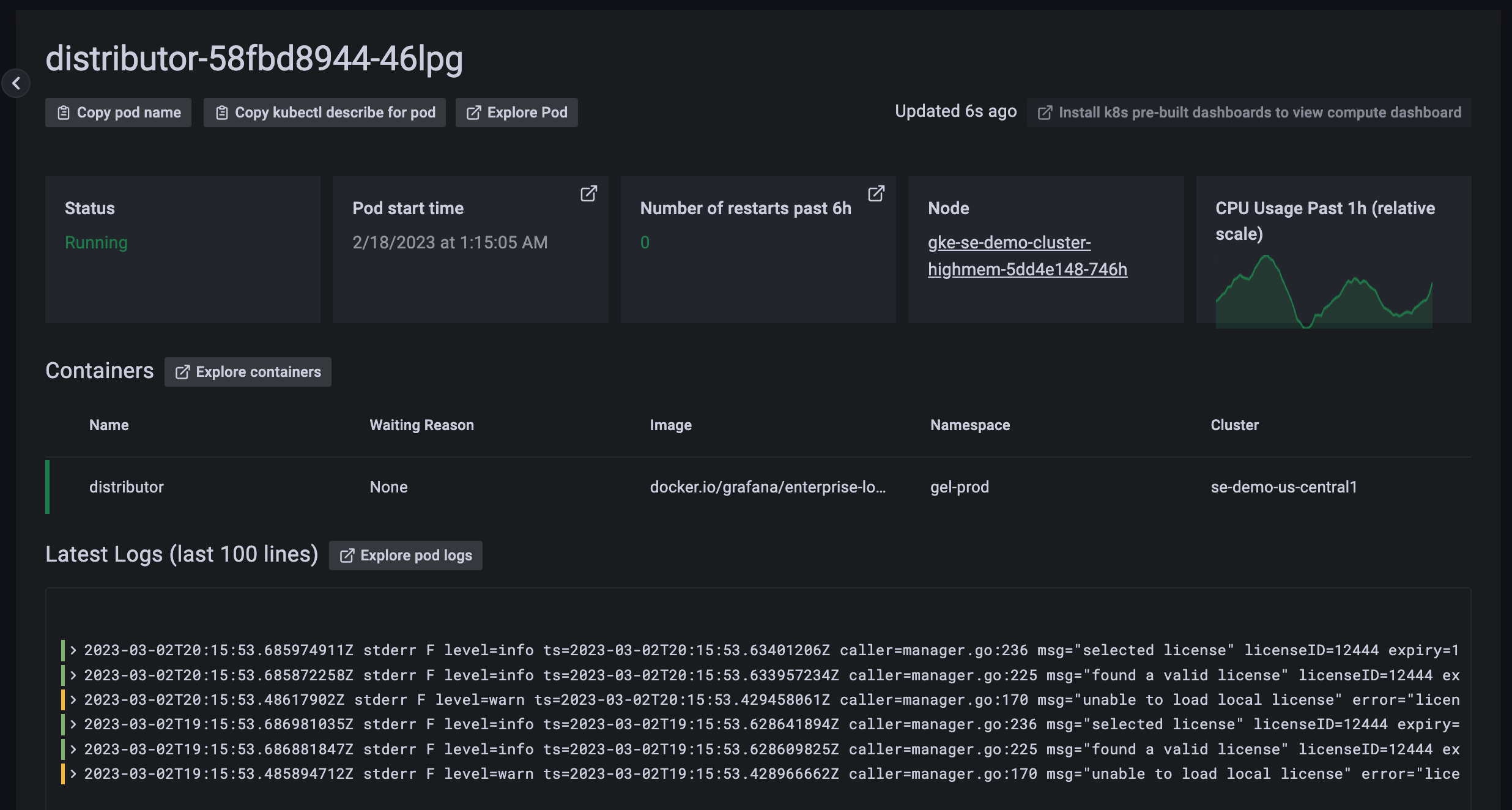
Click into a Pod to quickly see additional Pod info, its logs, and latest Kubernetes cluster events.
![Pod view]()
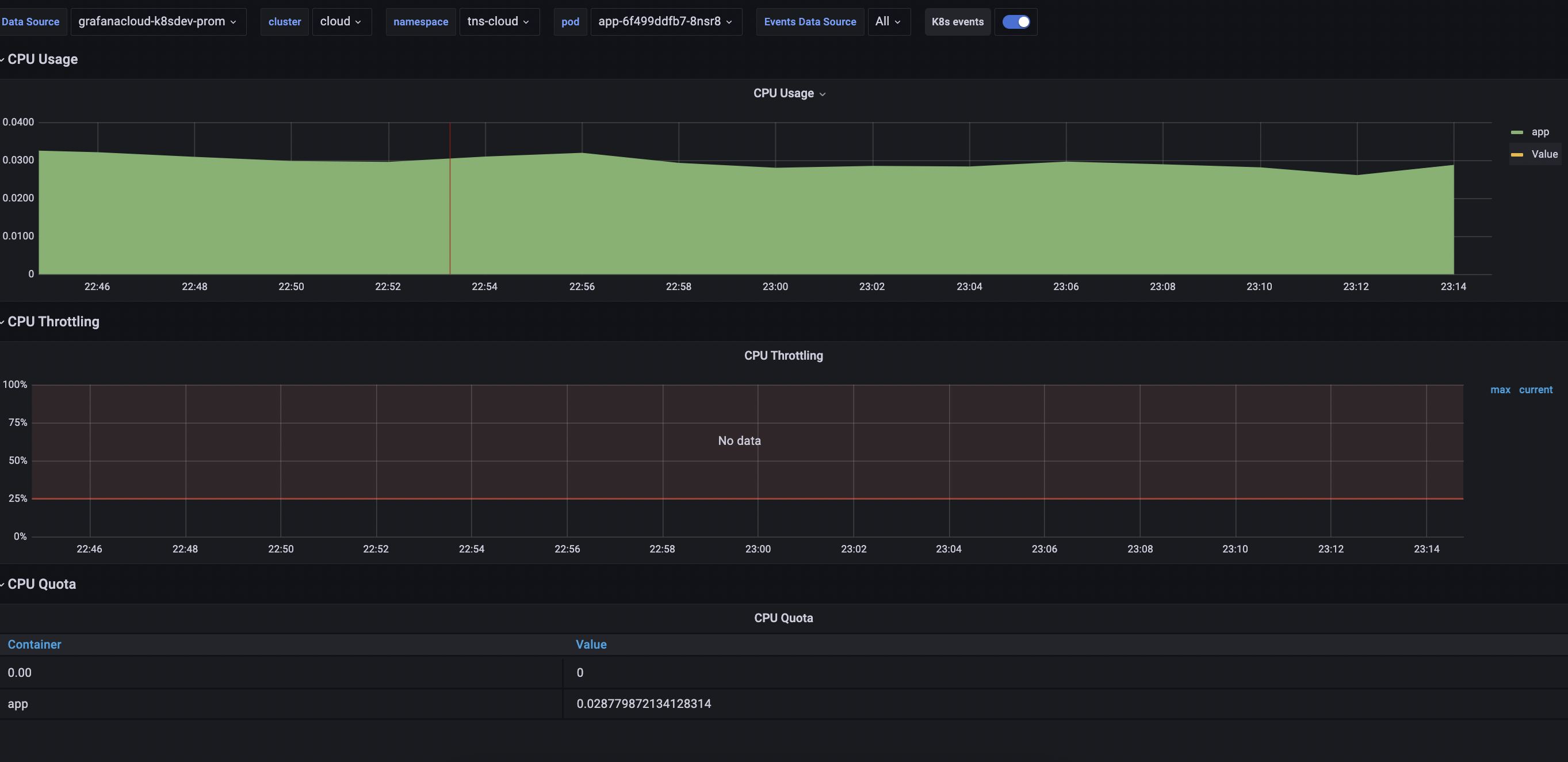
Click View compute resources on the top right of the screen to quickly jump to the Pod’s resource usage dashboard:
![Pod dashboard]()
Summary
Instead of copy and pasting Pod names and labels from a terminal and running kubectl get, kubectl describe, and kubectl logs, you can now navigate and jump straight to the relevant observability data, all in Grafana Cloud.
To learn more about Grafana Cloud Kubernetes monitoring, see the Grafana Kubernetes Monitoring documentation.