Caution
Grafana Agent has reached End-of-Life (EOL) on November 1, 2025. Agent is no longer receiving vendor support and will no longer receive security or bug fixes. Current users of Agent Static mode, Agent Flow mode, and Agent Operator should proceed with migrating to Grafana Alloy. If you have already migrated to Alloy, no further action is required. Read more about why we recommend migrating to Grafana Alloy.
This is documentation for the next version of Grafana Agent Documentation. For the latest stable release, go to the latest version.
cloudwatch_exporter_config
Overview
The cloudwatch_exporter_config block configures the cloudwatch_exporter integration, which is an embedded version of
YACE. Use the cloudwatch_exporter to collect AWS CloudWatch metrics.
This integration lets you scrape CloudWatch metrics in a set of configurations that we will call jobs. There are
two kind of jobs: discovery and static.
Authentication
The agent must be running in an environment with access to AWS. The exporter uses the AWS SDK for Go and provides authentication via AWS’s default credential chain. Regardless of the method used to acquire the credentials, some permissions are needed for the exporter to work.
"tag:GetResources",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics"The following IAM permissions are required for the Transit Gateway attachment (tgwa) metrics to work.
"ec2:DescribeTags",
"ec2:DescribeInstances",
"ec2:DescribeRegions",
"ec2:DescribeTransitGateway*"The following IAM permission is required to discover tagged API Gateway REST APIs:
"apigateway:GET"The following IAM permissions are required to discover tagged Database Migration Service (DMS) replication instances and tasks:
"dms:DescribeReplicationInstances",
"dms:DescribeReplicationTasks"To use all of the integration features, use the following AWS IAM Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1674249227793",
"Action": [
"tag:GetResources",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"ec2:DescribeTags",
"ec2:DescribeInstances",
"ec2:DescribeRegions",
"ec2:DescribeTransitGateway*",
"apigateway:GET",
"dms:DescribeReplicationInstances",
"dms:DescribeReplicationTasks"
],
"Effect": "Allow",
"Resource": "*"
}
]
}Configuration options
Configuration reference:
#
# Common Integration Settings
#
# Enables the cloudwatch_exporter integration, allowing the Agent to automatically
# collect CloudWatch metrics as configured.
[enabled: <boolean> | default = false]
# Sets an explicit value for the instance label when the integration is
# self-scraped. Overrides inferred values.
#
# The default value for this integration is a hash of the whole integration configuration.
[instance: <string>]
# Automatically collect metrics from this integration. If disabled,
# the cloudwatch_exporter integration is run but not scraped and thus not
# remote-written. Metrics for the integration are exposed at
# /integrations/cloudwatch_exporter/metrics and can be scraped by an external
# process.
[scrape_integration: <boolean> | default = <integrations_config.scrape_integrations>]
# How often should the metrics be collected. Defaults to
# prometheus.global.scrape_interval.
[scrape_interval: <duration> | default = <global_config.scrape_interval>]
# The timeout before considering the scrape a failure. Defaults to
# prometheus.global.scrape_timeout.
[scrape_timeout: <duration> | default = <global_config.scrape_timeout>]
# Allows for relabeling labels on the target.
relabel_configs:
[- <relabel_config> ... ]
# Relabel metrics coming from the integration, allowing to drop series
# from the integration that you don't care about.
metric_relabel_configs:
[ - <relabel_config> ... ]
# How frequent to truncate the WAL for this integration.
[wal_truncate_frequency: <duration> | default = "60m"]
#
# Exporter-specific configuration options
#
# Required: AWS region to use when calling STS (https://docs.aws.amazon.com/STS/latest/APIReference/welcome.html) for retrieving
# account information.
# Ex: us-east-2
sts_region: <string>
# Optional: Disable use of FIPS endpoints. Set 'true' when running outside of USA regions.
[fips_disabled: <boolean> | default = false]
# Instead of retrieving metrics on request, decouple scraping retrieves the
# metrics on a schedule and returns the cached metrics.
decoupled_scraping:
# Enable decoupled scraping.
[enabled: <boolean> | default = false ]
# How often to scrape for CloudWatch metrics.
[scrape_interval: <duration> | default = "5m"]
discovery:
# Optional: List of tags (value) per service (key) to export in all metrics. For example defining the ["name", "type"] under
# AWS/EC2 will export the name and type tags and its values as labels in all metrics. Affects all discovery jobs.
# Ex:
# exported_tags:
# AWS/EC2:
# - name
exported_tags:
{ <string>: [ <string> ] }
# List of discovery jobs
jobs: [ <discovery_job> ]
# List of static jobs
static: [ <static_job> ]
# Optional: Enable debug logging on CloudWatch exporter internals.
[debug: <boolean> | default = false]discovery_job
A discovery job allows one to just define the AWS service to scrape, and the metrics under that service/namespace to retrieve. The agent will find AWS resources in the specified service for which to scrape these metrics, label them appropriately, and export them to Prometheus. For example, if we wanted to scrape CPU utilization and network traffic metrics, from all AWS EC2 instances:
sts_region: us-east-2
discovery:
jobs:
- type: AWS/EC2
regions:
- us-east-2
nil_to_zero: true
metrics:
- name: CPUUtilization
period: 5m
statistics:
- Average
nil_to_zero: true
- name: NetworkPacketsIn
period: 5m
statistics:
- Average
nil_to_zero: trueConfiguration reference:
# Required: List of AWS regions.
regions: [ <string> ]
# Optional: List of IAM roles to assume. Defaults to the role on the environment configured AWS role.
roles: [ <aws_role> ]
# Required: Cloudwatch service alias ("alb", "ec2", etc) or namespace name ("AWS/EC2", "AWS/S3", etc). See section below for all
# supported.
type: <string>
# Optional: List of `Key/Value` pairs to use for tag filtering (all must match). Value can be a regex.
search_tags: [ <aws_tag> ]
# Optional: Custom tags to be added as a list of `Key/Value` pairs. When exported to Prometheus format, the label name follows
# the following format: `custom_tag_{Key}`.
custom_tags: [ <aws_tag> ]
# Optional: List of metric dimensions to query. Before querying metric values, the total list of metrics will be filtered to only those that contain exactly this list of dimensions. An empty or undefined list results in all dimension combinations being included.
dimension_name_requirements: [ <string> ]
# Optional: Flag that controls if `NaN` metric values are converted to 0. Default `true`. This can be overridden in the config of each metric.
nil_to_zero: <bool>
# Required: List of metric definitions to scrape.
metrics: [ <metric> ]static_job
A static job allows one to scrape an individual CloudWatch metric. For that, metrics needs to be fully qualified, specifying the following:
namespace: For exampleAWS/EC2,AWS/EBS,CoolAppif it were a custom metric, etc.dimensions: CloudWatch identifies a metrics by a set of dimensions. For example, allAWS/EC2metrics are identified by theInstanceIddimension.metrics: Metric name and statistics.
For example, if one wants to scrape the same metrics in the discovery example, but for a specific AWS EC2 instance:
sts_region: us-east-2
static:
- name: single_ec2_instance
regions:
- us-east-2
namespace: AWS/EC2
dimensions:
- name: InstanceId
value: i-0e43cee369aa44b52
nil_to_zero: true
metrics:
- name: CPUUtilization
period: 5m
statistics:
- Average
nil_to_zero: true
- name: NetworkPacketsIn
period: 5m
statistics:
- Average
nil_to_zero: trueAll dimensions need to be specified when scraping single metrics like the example above. For example AWS/Logs metrics
require Resource, Service, Class, and Type dimensions to be specified. Same applies to CloudWatch custom metrics,
all dimensions attached to a metric when saved in CloudWatch are required.
Configuration reference:
# Required: List of AWS regions.
regions: [ <string> ]
# Optional: List of IAM roles to assume. Defaults to the role on the environment configured AWS role.
roles: [ <aws_role> ]
# Required: Identifier of the static scraping job. When exported to Prometheus format corresponds to the `name` label.
name: <string>
# Required: CloudWatch namespace
namespace: <string>
# Required: CloudWatch metric dimensions as a list of Name/Value pairs. Must uniquely define a single metric.
dimensions: [ <aws_dimension> ]
# Optional: Custom tags to be added as a list of Key/Value pairs. When exported, the label name follows the following format:
# `custom_tag_{Key}`.
custom_tags: [ <aws_tag> ]
# Optional: Flag that controls if `NaN` metric values are converted to 0. Default `true`. This can be overridden in the config of each metric.
nil_to_zero: <bool>
# Required: List of metric definitions to scrape.
metrics: [ <metric> ]aws_role
Represents an AWS IAM Role. Required when configuring a job. If omitted the AWS role that the credentials configured in the environment posses will be used.
This is useful when scraping metrics from different AWS accounts with a single pair of credentials. In this case, a different role is configured for the agent to assume prior to calling AWS APIs, therefore, the credentials configured in the system need permission to assume the target role. See this documentation on how to configure this.
# Required: AWS IAM Role ARN the exporter should assume to perform AWS API calls.
role_arn: <string>
# Optional: External ID used when calling STS AssumeRole API. See https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-user_externalid.html for details.
external_id: <string>aws_dimension
Represents an AWS CloudWatch Dimension.
name: <string>
value: <string>aws_tag
Represents an AWS Tag.
key: <string>
value: <string>metric
Represents an AWS Metrics to scrape, under the context of a job. To see available metrics, AWS does not keep a documentation page with all available metrics. Follow this guide on how to explore metrics, to easily pick the ones you need.
# Required: CloudWatch metric name.
name: <string>
# Required: List of statistic types, e.g. "Minimum", "Maximum", etc.
statistics: [ <string> ]
# Optional: See the `period and length` section below.
period: [ <duration> | default = 5m ]
# Optional: See the `period and length` section below.
length: [ <duration> | default = calculated based on `period` ]
# Optional: Flag that controls if `NaN` metric values are converted to 0.
# When not set, the value defaults to the setting in the parent static or discovery block (`true` if not set in the parent block).
nil_to_zero: <bool>Period and length
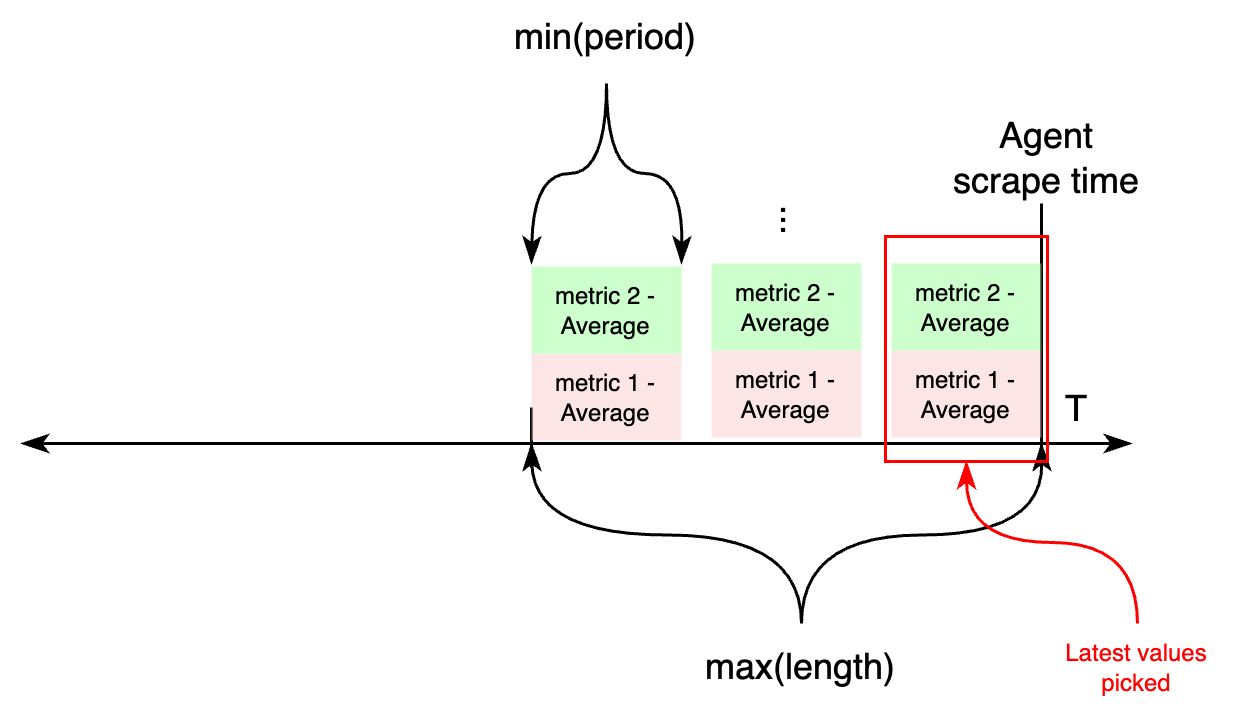
period controls the width of the time bucket used for aggregating metrics collected from CloudWatch.
length controls how far back in time CloudWatch metrics are considered during each agent scrape.
If both settings are configured, the time parameters when calling CloudWatch APIs work as follows:
As noted above, if there is a different period or length across multiple metrics under the same static or discovery job,
the minimum of all periods, and maximum of all lengths is configured.
On the other hand, if length isn’t configured, both period and length settings are calculated based on
the required period configuration attribute.
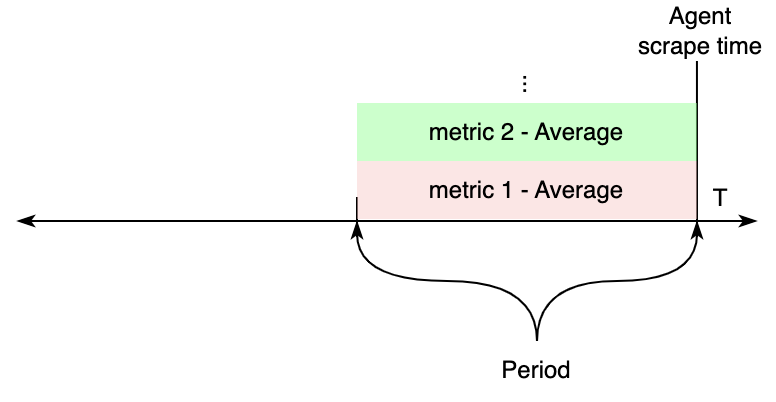
If all metrics within a job (discovery or static) have the same period value configured, CloudWatch APIs will be
requested for metrics from the scrape time, to periods seconds in the past.
The values of these metrics are exported to Prometheus.
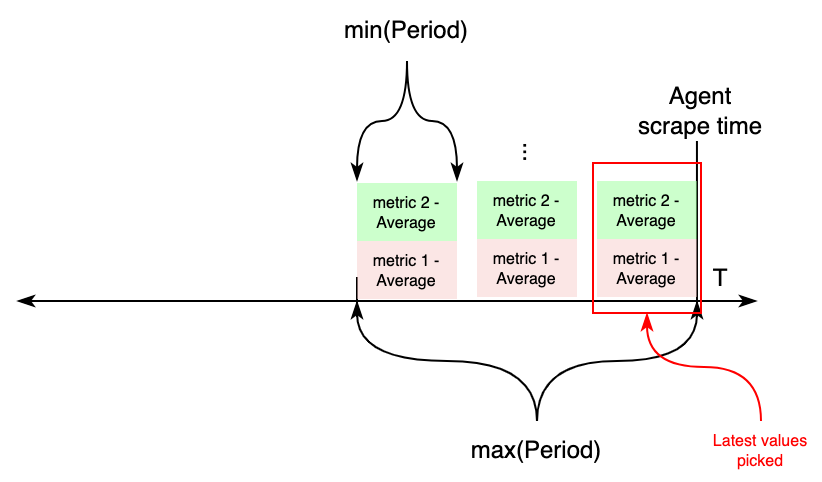
On the other hand, if metrics with different periods are configured under an individual job, this works differently.
First, two variables are calculated aggregating all periods: length, taking the maximum value of all periods, and
the new period value, taking the minimum of all periods. Then, CloudWatch APIs will be requested for metrics from
now - length to now, aggregating each in samples for period seconds. For each metric, the most recent sample
is exported to CloudWatch.
Supported services in discovery jobs
The following is a list of AWS services that are supported in cloudwatch_exporter discovery jobs. When configuring a
discovery job, the type field of each discovery_job must match either the desired job namespace or alias.
- Namespace:
CWAgentor Alias:cwagent - Namespace:
AWS/Usageor Alias:usage - Namespace:
AWS/CertificateManageror Alias:acm - Namespace:
AWS/ACMPrivateCAor Alias:acm-pca - Namespace:
AmazonMWAAor Alias:airflow - Namespace:
AWS/MWAAor Alias:mwaa - Namespace:
AWS/ApplicationELBor Alias:alb - Namespace:
AWS/AppStreamor Alias:appstream - Namespace:
AWS/Backupor Alias:backup - Namespace:
AWS/ApiGatewayor Alias:apigateway - Namespace:
AWS/AmazonMQor Alias:mq - Namespace:
AWS/AppSyncor Alias:appsync - Namespace:
AWS/Athenaor Alias:athena - Namespace:
AWS/AutoScalingor Alias:asg - Namespace:
AWS/ElasticBeanstalkor Alias:beanstalk - Namespace:
AWS/Billingor Alias:billing - Namespace:
AWS/Cassandraor Alias:cassandra - Namespace:
AWS/CloudFrontor Alias:cloudfront - Namespace:
AWS/Cognitoor Alias:cognito-idp - Namespace:
AWS/DMSor Alias:dms - Namespace:
AWS/DDoSProtectionor Alias:shield - Namespace:
AWS/DocDBor Alias:docdb - Namespace:
AWS/DXor Alias:dx - Namespace:
AWS/DynamoDBor Alias:dynamodb - Namespace:
AWS/EBSor Alias:ebs - Namespace:
AWS/ElastiCacheor Alias:ec - Namespace:
AWS/MemoryDBor Alias:memorydb - Namespace:
AWS/EC2or Alias:ec2 - Namespace:
AWS/EC2Spotor Alias:ec2Spot - Namespace:
AWS/ECSor Alias:ecs-svc - Namespace:
ECS/ContainerInsightsor Alias:ecs-containerinsights - Namespace:
AWS/EFSor Alias:efs - Namespace:
AWS/ELBor Alias:elb - Namespace:
AWS/ElasticMapReduceor Alias:emr - Namespace:
AWS/EMRServerlessor Alias:emr-serverless - Namespace:
AWS/ESor Alias:es - Namespace:
AWS/Firehoseor Alias:firehose - Namespace:
AWS/FSxor Alias:fsx - Namespace:
AWS/GameLiftor Alias:gamelift - Namespace:
AWS/GlobalAcceleratoror Alias:ga - Namespace:
Glueor Alias:glue - Namespace:
AWS/IoTor Alias:iot - Namespace:
AWS/Kafkaor Alias:kafka - Namespace:
AWS/KafkaConnector Alias:kafkaconnect - Namespace:
AWS/Kinesisor Alias:kinesis - Namespace:
AWS/KinesisAnalyticsor Alias:kinesis-analytics - Namespace:
AWS/Lambdaor Alias:lambda - Namespace:
AWS/MediaConnector Alias:mediaconnect - Namespace:
AWS/MediaConvertor Alias:mediaconvert - Namespace:
AWS/MediaLiveor Alias:medialive - Namespace:
AWS/MediaTailoror Alias:mediatailor - Namespace:
AWS/Neptuneor Alias:neptune - Namespace:
AWS/NetworkFirewallor Alias:nfw - Namespace:
AWS/NATGatewayor Alias:ngw - Namespace:
AWS/NetworkELBor Alias:nlb - Namespace:
AWS/PrivateLinkEndpointsor Alias:vpc-endpoint - Namespace:
AWS/PrivateLinkServicesor Alias:vpc-endpoint-service - Namespace:
AWS/Prometheusor Alias:amp - Namespace:
AWS/QLDBor Alias:qldb - Namespace:
AWS/RDSor Alias:rds - Namespace:
AWS/Redshiftor Alias:redshift - Namespace:
AWS/Route53Resolveror Alias:route53-resolver - Namespace:
AWS/Route53or Alias:route53 - Namespace:
AWS/S3or Alias:s3 - Namespace:
AWS/SESor Alias:ses - Namespace:
AWS/Statesor Alias:sfn - Namespace:
AWS/SNSor Alias:sns - Namespace:
AWS/SQSor Alias:sqs - Namespace:
AWS/StorageGatewayor Alias:storagegateway - Namespace:
AWS/TransitGatewayor Alias:tgw - Namespace:
AWS/TrustedAdvisoror Alias:trustedadvisor - Namespace:
AWS/VPNor Alias:vpn - Namespace:
AWS/ClientVPNor Alias:clientvpn - Namespace:
AWS/WAFV2or Alias:wafv2 - Namespace:
AWS/WorkSpacesor Alias:workspaces - Namespace:
AWS/AOSSor Alias:aoss - Namespace:
AWS/SageMakeror Alias:sagemaker - Namespace:
/aws/sagemaker/Endpointsor Alias:sagemaker-endpoints - Namespace:
/aws/sagemaker/TrainingJobsor Alias:sagemaker-training - Namespace:
/aws/sagemaker/ProcessingJobsor Alias:sagemaker-processing - Namespace:
/aws/sagemaker/TransformJobsor Alias:sagemaker-transform - Namespace:
/aws/sagemaker/InferenceRecommendationsJobsor Alias:sagemaker-inf-rec - Namespace:
AWS/Sagemaker/ModelBuildingPipelineor Alias:sagemaker-model-building-pipeline