
So verwaltet ihr Metriken mit hoher Kardinalität in Prometheus und Kubernetes
In den letzten Monaten wurde das Thema der Kosten für Observability in unseren Gesprächen mit Nutzern häufig und wiederholt aufgegriffen, da diese Kosten schneller steigen als der Umfang der überwachten Anwendungen und Infrastruktur. Da Unternehmen immer stärker auf Cloud-Native-Architekturen setzen und die Popularität von Prometheus weiter zunimmt, ist es nicht verwunderlich, dass auch die Kardinalität von Metriken (kartesische Kombination von Metriken und Labels) wächst. Die Wachstumsrate hat jedoch einige Unternehmen überrascht und ist bei Aufbau und Aufrechterhaltung von Observability-Systemen und -Praktiken in den Vordergrund gerückt.
Wenn euch das bekannt vorkommt und ihr derzeit untersucht, wie ihr das Wachstum von Metriken steuern könnt, schaut euch unser Webinar „Wie das Wachstum von Metriken in Prometheus und Kubernetes mit der Grafana Cloud gesteuert wird“ an, um praktische Tipps und Tricks zu erfahren, mit deren Umsetzung ihr sofort beginnen könnt.
Aber warum wachsen Metriken so beispiellos?
Cloud-native Umgebungen und Microservices-basierte Architekturen in Kombination mit autonomen Entwicklungsteams und Flexibilität schaffen eine perfekte Dreierkombination für eine exponentielle Zunahme von Zeitreihendaten. In Cloud-nativen Infrastrukturen wie Kubernetes kommt es mit zunehmender Abstraktion zu mehr Zeitreihen. Was einst ein einzelner Bare-Metal-Server war, auf dem eine Anwendung ausgeführt wurde, wird jetzt durch viele Pods ersetzt, auf denen verschiedenste Microservices über viele verschiedene Nodes verteilt ausgeführt werden. Jede dieser Abstraktionsschichten benötigt ein Label, damit sie eindeutig identifiziert werden kann, und jede dieser Komponenten generiert ihre eigenen Metriken, um ihre einzigartige Reihe von Zeitreihen zu erstellen.
Darüber hinaus entstehen durch die flüchtige Natur der Arbeitslasten in Kubernetes ebenfalls mehr Zeitreihen. So generiert die kube_pod_status_phase-Metrik (eine der kube-Status-Metriken) jedes Mal eine neue Zeitreihe, wenn ein Pod den Status wechselt, z. B. von „ausstehend“ auf „ausgeführt“ auf „fehlgeschlagen“ oder „erfolgreich“. Abhängig von der Häufigkeit von Clusterereignissen, insbesondere bei vielen kurzfristig ausgeführten Aufträgen, kann das Verfolgen des Status einzelner Pods bereits viele Metriken generieren.
Die Einfachheit der Instrumentierung und Autonomie, die durch eine Microservices-Architektur geschaffen wird, kann ebenso zu einer Erhöhung der Kardinalität führen. Mit einer Vielzahl von Open-Source-Exportern sowie Client-Bibliotheken für mehr als 15 Programmiersprachen war es noch nie einfacher, eure Anwendung zu instrumentieren, um Prometheus-Metriken bereitzustellen. Da jedes Team in der Lage ist, seiner Anwendung Metriken hinzuzufügen, wird die Governance schwieriger. Manchmal können Metriken, die in einer Entwicklungsumgebung relevant sind, in eine Produktionsumgebung rieseln und einen Anstieg der Zeitreihen verursachen. Da so viele Teams ihre Anwendungen instrumentieren, wird es für ein zentralisiertes Observability-Team schwierig, diese Lecks zu erkennen und zu verhindern.
Ist es ausschließlich das Cloud-native Monitoring, welches zu einer Erhöhung der Metrik-Kardinalität führt?
Während eine hohe Kardinalität in Cloud-Umgebungen definitiv häufiger vorkommt, ist es auch üblich, dass eine Legacy-Infrastruktur (Hardware oder Software), die nicht zu Prometheus gehört, in ein Prometheus-kompatibles Format mit Exportern migriert wird. Diese Exporter können bei der Anzahl der von ihnen generierten Metriken eine große Varianz aufzeigen, was zu einer hohen Kardinalität beiträgt. Beispielsweise gibt der Prometheus Node-Exporter, der Hardware- und Betriebssystemmetriken bereitstellt, standardmäßig etwa 500 Prometheus-Zeitreihen aus. Der mySQL-Exporter veröffentlicht rund 1.000 Zeitreihen, die nicht alle nützlich sind.
Unabhängig von der Umgebung ist einer der häufigsten Fehler, die wir sehen, die Verwendung suboptimaler Labels in Metrikdatenbanken. Da Kardinalität ein kartesisches Produkt aus zwei Sätzen (Metriken und Labels) ist, trägt die Definition der Label dazu bei, die Kardinalität unter Kontrolle zu halten. Wenn Labels verwendet werden, die zufällig generiert werden und keine Obergrenze für eindeutige Werte haben (z. B. wenn {session_id} bei jeder neuen Verbindung generiert wird), kann die Anzahl der Zeitreihen steigen, wenn der Datenverkehr zum System zunimmt. Das Gleiche gilt für {user_id} oder {device_id}.
Ok, eine hohe Kardinalität ist ein Symptom der Umgebung, aber warum spielt das eine Rolle?
Eine Erhöhung der Kardinalität bedeutet, dass ihr jetzt mehr Infrastruktur und Rechenleistung benötigt, um diese Zeitreihen zu speichern und zu verarbeiten. Dies wiederum hat einen direkten Einfluss darauf, wie viel eure Observability-Plattform kostet. In letzter Zeit stand dies für Nutzer und zentralisierte Observability-Teams an oberster Stelle.
Es wirkt sich allerdings auch auf die Leistung eurer Observability-Plattform selbst aus. Wenn eure Datenbank wächst, so wächst auch die Anzahl der Zeitreihen, auf die bei bestimmten Abfragen zugegriffen wird. Dies kann euer System stark verlangsamen, wenn ihr die Daten abfragt oder visualisiert. Dashboards, die langsam geladen werden, oder Abfragen, die langsam Daten zurückgeben, verlängern die MTTR bei der Fehlerbehebung.
Hinweis: Der Vorteil der Verwendung einer Cloud-basierten Observability-Plattform wie Grafana Cloud, die von der skalierbarsten Zeitreihendatenbank Grafana Mimir betrieben wird, besteht darin, dass diese Leistungsprobleme nicht auftreten, wenn eure Anzahl an Zeitreihen zunimmt.
Wie kann ich also das Wachstum von Metriken steuern?
Da das Wachstum von Metriken unvermeidlich ist und Auswirkungen auf euer Endergebnis hat, stellt sich die Frage, wie ihr wachsende Metriken und Kosten kontrollieren und optimieren könnt. Wie bei Monitoringund Observability beginnen die Antworten auf Fragen mit der richtigen Sichtbarkeit und den richtigen Einblicken in die Daten.
Nachfolgend findet ihr drei wichtige Schritte zur Kontrolle der Kardinalität und der Kosten von Metriken:
1. Verschafft euch einen Überblick über Metriken mit hoher Kardinalität und wertvolle Metriken
Der erste Schritt zu einer Optimierung besteht darin, einen Überblick darüber zu gewinnen, welche Metriken und Labels zur Kardinalität beitragen und welche Metriken wertvoll sind. Metriken, die in Dashboards, Warnungen und Aufzeichnungsregeln verwendet werden, sind natürlich erforderlich; andere werden jedoch nur für Ad-hoc-Abfragen verwendet, beispielsweise bei der Fehlerbehebung oder werden überhaupt nicht abgefragt.
Das folgende Diagramm zeigt Metriken, die auf der Grundlage von Kardinalität und Wert in vier Quadranten unterteilt sind. Ihr solltet damit beginnen, die Metriken in Quadrant 3 zu identifizieren, die teuer sind, aber nicht verwendet werden. Bei den Metriken, die in Quadrant 4 fallen, kann eine Neubewertung der Granularität und der Labelarchitektur zu einer großen Verbesserung für Metriken und Labels führen, die einen Mehrwert bieten, aber eine hohe Kardinalität aufweisen.

Identifizierung von Metriken und Labels mit hoher Kardinalität
Grafana Cloud Pro- und Advanced-Pläne umfassen eine Reihe von Dashboards für das Kardinalitätsmanagement, die euch helfen, Metriken und Labels mit hoher Kardinalität zu identifizieren und euch bei der Optimierung anzuleiten.

Weitere Informationen zur einfachen Überwachung der Kardinalität mit Grafana-Dashboards findet ihr unter:
- So verwaltet ihr die Kardinalität mit sofort einsatzbereiten Dashboards in der Grafana Cloud
- Analyse der Verwendung von Metrikenverwendung mit Dashboards zum Kardinalitätsmanagement
Wenn ihr Grafana Cloud-Benutzer seid und mehr darüber erfahren möchtet, wie ihr Metriken optimiert, kontaktiert uns.
Entdeckt unbenutzte Metriken
Mimirtool ist ein Open-Source-Tool, das verwendet werden kann, um Metriken in Mimir, Prometheus oder Prometheus-kompatiblen Datenbanken zu identifizieren, die nicht in Dashboards, Warnungen oder Aufzeichnungsregeln verwendet werden. Mimirtool wird über die Kommandozeile ausgeführt und erzeugt eine JSON-Datei mit unbenutzten Metriken.
Metriken, die vollständig ungenutzt sind, können sicher verworfen werden, wenn sie nicht für Ad-hoc-Anfragen oder zukünftige Projekte erforderlich sind.
Erfahrt mehr über die Verwendung von Mimirtool, um ungenutzte Metriken zu identifizieren, in diesen Dokumenten:
- So findet ihr schnell ungenutzte Metriken und erhaltet mehr Wert aus der Grafana Cloud
- Analyse und Reduzierung der Metriknutzung mit Grafana Mimirtool
2. Verstehen, welche Teams für das Wachstum von Metriken verantwortlich sind
Als nächstes solltet ihr verstehen, welche Teams und Umgebungen am meisten zur Kardinalität in eurem Unternehmen beitragen.
Grafana Cloud Advanced enthält Usage Insights, um die Ursachen der Kardinalität in eurer Umgebung zu identifizieren. Verfolgt die Anzahl der Zeitreihen, für die im Laufe der Zeit ein bestimmtes Label oder eine Reihe von Labeln genutzt wurden, damit ihr versteht, wie verschiedene Teams, Umgebungen oder Anwendungen zu eurer Gesamtzahl der Reihen beitragen. Indem ihr diese Daten als Zeitreihe bereitstellt, könnt ihr leicht feststellen, wie eine Änderung zu einem bestimmten Zeitpunkt zu einer Erhöhung eurer Observability-Rechnung geführt hat.

Um mehr über die Verwendung von Nutzungsgruppen zur Überwachung der Metriknutzung zu erfahren, werft einen Blick auf diesen Blogbeitrag:
3. Beginnt mit der Optimierung der Metriken
In diesem Abschnitt behandeln wir, wie ihr mit der Optimierung von Metriken beginnen könnt, sobald ihr einen Einblick in Metriken und Labels mit hoher Kardinalität habt, und ihr Metriken mit niedrigem und hohem Wert identifizieren konntet.

Datenhäufigkeit prüfen
Bei der Prognose von Kapazitätsanforderungen für Metriken ist es wichtig, eure Datenfrequenzanforderungen zu berücksichtigen. Das standardmäßige Scrape_Interval für Prometheus beträgt 15 Sekunden oder 4 Datenpunkte pro Minute (DPM). Wenn diese Häufigkeit jedoch nicht erforderlich ist, kann die Standardkonfiguration dazu führen, dass mehr Daten gespeichert werden, als notwendig sind.
Um euer aktuelles scrape_interval zu überprüfen, verwendet die folgende Abfrage, um die Anzahl der in der letzten Minute importierten Proben zu finden, aufgeteilt nach Ziel:
count_over_time(scrape_samples_scraped[1m])

Ihr könnt dann diese Metriken überprüfen und das Scrape_Interval für weniger kritische Metriken erhöhen, um die Kosten zu senken. Oft können weniger kritische Metriken auf ein Scrape_Interval von 60 Sekunden eingestellt werden, was die Kosten um bis zu 75 % senken kann.
Weitere Informationen zum Einstellen von Scrape_Intervals findet ihr in unserer Dokumentation:
Histogramme prüfen
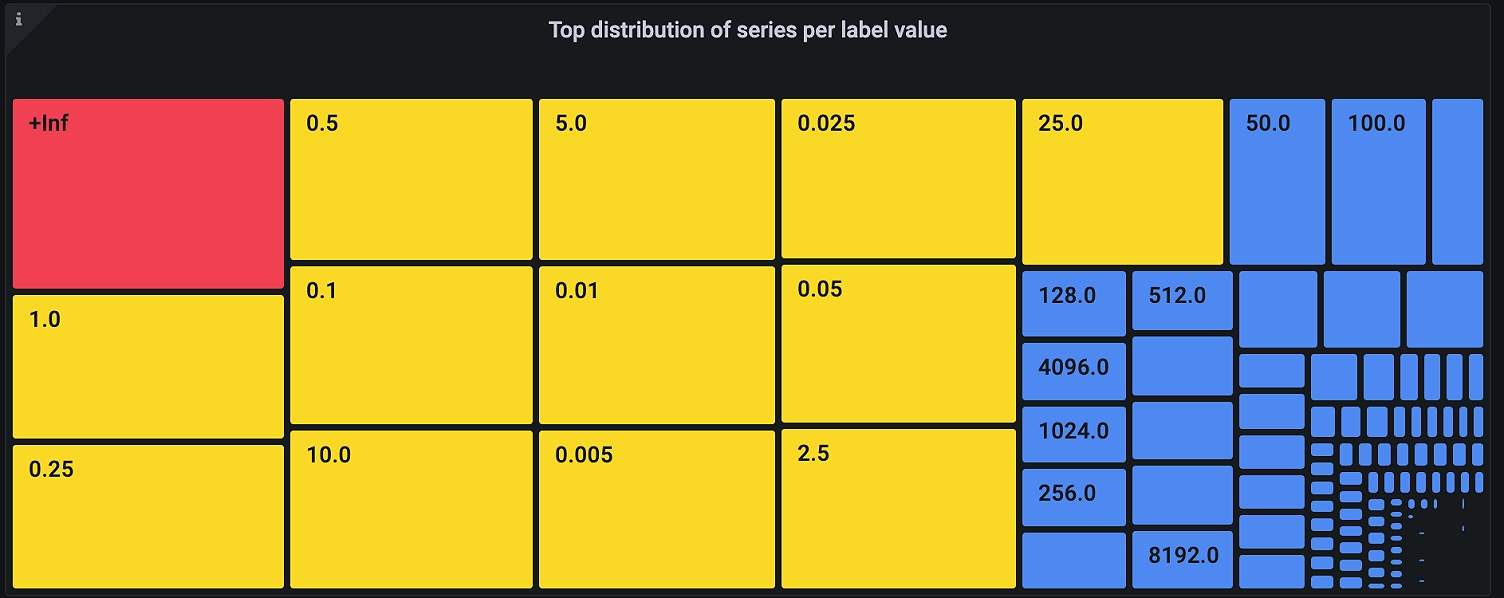
Histogramme ermöglichen es euch, die Verteilung einer bestimmten Größe zu verstehen. Die Genauigkeit dieser Verteilung wird durch die Anzahl der Buckets bestimmt, die ihr in diesem Histogramm habt. In Prometheus wird jedes Bucket als Zeitreihe verfolgt, die einen bestimmten Wert des le (kleiner oder gleich) Labels hat.
Mit dem Grafana-Dashboard für Kardinalitätsmanagement in Grafana Cloud können wir die Werte für das le Label sehen und wie dies zur Gesamtkardinalität beiträgt. Wählt Buckets aus, die für eure Umgebung relevan sind. Wenn die SLO für einen Dienst beispielsweise eine Antwortzeit von 50 ms hat, müsst ihr möglicherweise nicht zwischen Anfragen unterscheiden, die 5 ms und 10 ms benötigen.

Ihr könnt die Metrikserie für Buckets, die nicht benötigt werden, sicher verwerfen. Dies führt nicht zu Datenverlusten, da die Buckets kumulativ sind. Wenn ihr beispielsweise den Bucket „kleiner oder gleich 10“ verwerft, werden diese Werte einfach in den Bucket „kleiner oder gleich 25“ aufgenommen. Wenn diese Dimensionalität nicht erforderlich ist, könn ihr den Wert 10 für das le Label sicher verwerfen.
Nachfolgend findet ihr ein Beispiel für eine Relabel-Konfiguration:
# verwirft alle Metrikreihen, die mit _bucket enden, wobei le="10"
- source_labels: [__name__, le]
separator: _
regex: ".+_bucket_10"
action: "drop" <https://relabeler.promlabs.com/>*")
Weitere Informationen zur Reduzierung der Verwendung von Prometheus-Metriken und der Relabel-Konfiguration findet ihr in unserer Dokumentation:
Labels reduzieren
Für Metriken mit unbenutzten Labels ist es nicht ganz so einfach wie das Verwerfen von Labels, die nicht verwendet werden. Das Verwerfen eines Labels kann zu doppelten Serien führen, die von Prometheus abgelegt werden wie in den nachstehenden Beispiele zu sehen ist. Im ersten Beispiel könnt ihr das IP-Label sicher verwerfen, da die verbleibenden Serien einzigartig sind. Im zweiten Beispiel könnt ihr jedoch sehen, wie das Verwerfen des IP-Labels doppelte Zeitreihen erzeugt, die Prometheus verwirft. In diesem Beispiel erhält Prometheus die Werte 1, 3 und 7 für my_metric_total mit dem gleichen Zeitstempel und verwirft 2 der Datenpunkte.
# Ihr könnt das IP-Label verwerfen, die verbleibenden Serien sind immer noch einzigartig
my_metric_total{env=“dev”, ip=“1.1.1.1"} 12
my_metric_total{env=“tst”, ip=“1.1.1.1"} 14
my_metric_total{env=“prd”, ip=“1.1.1.1"} 18
#Verbleibende Werte nach dem Verwerfen des IP-Labels
my_metric_total{env=“dev”} 12
my_metric_total{env=“tst”} 14
my_metric_total{env=“prd”} 18
# Ihr könnt das IP-Label nicht verwerfen, die verbleibenden Serien sind nicht eindeutig
my_metric_total{env=“dev”, ip=“1.1.1.1"} 1
my_metric_total{env=“dev”, ip=“3.3.3.3”} 3
my_metric_total{env=“dev”, ip=“5.5.5.5"} 7
#Verbleibende Werte nach dem Verwerfen des IP-Labels sind nicht eindeutig
my_metric_total{env=“dev”} 1
my_metric_total{env=“dev”} 3
my_metric_total{env=“dev”} 7Ihr könnt Labels sicher verwerfen, wenn dies nicht zu Duplikaten führt.
In Umgebungen, in denen ihr die Kontrolle über die Anwendung habt, könnt ihr die für die Metrik-Sammlung verwendeten Agenten neu konfigurieren, um nicht verwendete Labels verwerfen.
Wenn ihr keine Kontrolle über die Anwendung habt und das Verwerfen von Labels zu doppelten Serien führt, kann die Anwendung einer Funktion (d. h. Summe, Durchschnitt, Min, Max) über Prometheus-Aufzeichnungsregeln es euch ermöglichen, die aggregierten Daten zu behalten, während einzelne Serien verworfen werden. Im folgenden Beispiel verwenden wir die Summenfunktion, um die aggregierte Metrik zu speichern, sodass wir die einzelnen Zeitreihen verwerfen können.
# sum by env
my_metric_total{env="dev", ip="1.1.1.1"} 1
my_metric_total{env="dev", ip="3.3.3.3"} 3
my_metric_total{env="dev", ip="5.5.5.5"} 7
# Aufzeichnungsregel
sum by(env) (my_metric_total{})
my_metric_total{env="dev"} 11Weitere Informationen zur Reduzierung von Prometheus-Aufnahmeregeln und zur Konfiguration von Relabels findet ihr in den folgenden Ressourcen:
- Prometheus-Aufnahmeregeln
- Reduzierung der Verwendung von Prometheus-Metriken durch Relabeling
- Wie Re-Labeling in Prometheus funktioniert
Erfahrt mehr über die Verwaltung von Metriken in Prometheus und Kubernetes mit Grafana Cloud
Meldet euch bei Grafana Cloud an, um die Kardinalität in eurer Umgebung zu verstehen, Teams und Umgebungen Kosten zuzuordnen und eure Metrikkosten zu optimieren. Dazu gehört auch eine 14-tägige Testversion von Grafana Cloud Pro, sodass ihr die Dashboards für das Kardinalitätsmanagement, Nutzungsgruppen und andere Technologien in eurer Umgebung ausprobieren könnt.
Um mehr darüber zu erfahren, wie ihr die Kosten für Metriken in Prometheus- und Kubernetes-Umgebungen steuern könnt, könnt ihr euch auch unser Webinar „So steuert ihr das Wachstum von Metriken in Prometheus und Kubernetes mit Grafana Cloud“ ansehen.
Wenn ihr Grafana Cloud-Benutzer seid und mehr darüber erfahren möchtet, wie ihr Metriken optimiert, kontaktiert uns.