Telegraf system overview
InfluxDB dashboards for telegraf metrics
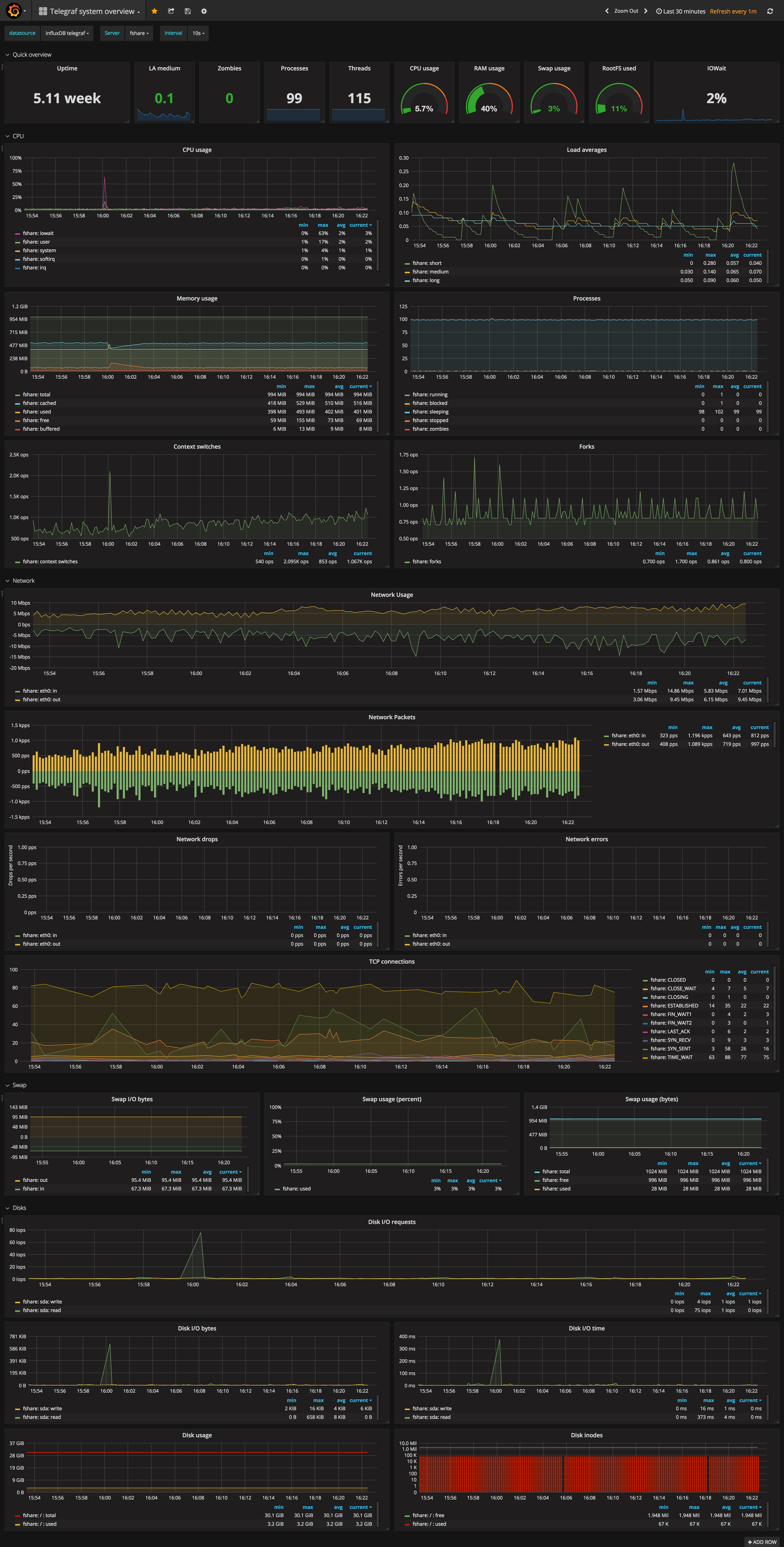
Not updated anymore - please use my templated version instead
Data source config
Collector type:
Collector plugins:
Collector config:
Revisions
Upload an updated version of an exported dashboard.json file from Grafana
| Revision | Description | Created | |
|---|---|---|---|
| Download |