SLOs: a guide to setting and benefiting from service level objectives
If you’re running a technology-driven business, reliability isn’t optional—it’s essential. But how do you balance speed and innovation with a level of reliability that satisfies your customers?
That’s where service level objectives (SLOs) come in.
SLOs offer a framework for defining and achieving reliability goals, aligning technical efforts with user needs, and driving meaningful outcomes for your business. An SLO is expressed as a quantitative target, typically within a defined time period, which is used to assess whether a service meets the agreed-upon performance standard. For example, an SLO might specify that a service should have 99.9% uptime per month, or that latency should be below 100 milliseconds for 95% of requests.
In this guide, we’ll explore why SLOs matter, as well as how to set them up for success, gain team buy-in, and deliver transformative outcomes.
Why should you use SLOs?
If you’ve ever struggled to decide whether to prioritize a new feature or address a lingering performance issue, SLOs can be your guide. They provide a decision-making framework that keeps your focus on what matters most: your users and their experience.
Beyond prioritization, SLOs fundamentally change how and what you alert on. By shifting the focus from arbitrary thresholds to user-impact-driven metrics, they enable a proactive approach to incident management. This shift helps teams move from reactive fire-fighting to strategic maintenance and improvement of reliability, which translates to a better experience for your users.

SLOs help improve customer experience needs
At their core, SLOs help prioritize reliability in areas that directly impact the user experience. By defining objectives for metrics like availability, response time, or error rate, you ensure engineering efforts align with what users care about—metrics that correlate with user delight or abandonment.
For additional guidance, consider the RED method, a simple framework introduced by our CTO Tom Wilkie:
- Rate: The number of requests per second
- Errors: The number of requests that fail
- Duration: The time taken to process those requests
Let’s look at an example of how this could play out in practice. If your service powers online transactions, an SLO focused on checkout completion times ensures your team monitors and optimizes a critical user journey:
Objective: Ensure the checkout process completes within an acceptable time frame for at least 99.9% of transactions over a rolling 30-day period.
Service level indicator (SLI): The time it takes for a user to successfully complete the checkout process, measured from clicking “Place Order” to the confirmation page fully loading.
Target:
- Threshold: 95% of transactions should complete within two seconds.
- Error Budget: Up to 0.1% of transactions may exceed the two-second threshold within a 30-day period.
The intended outcome in this example is to ensure the checkout process remains fast and reliable, with 99.9% of transactions completing within two seconds, while also allowing for a small margin of error (0.1%) for slower transactions over a 30-day period.
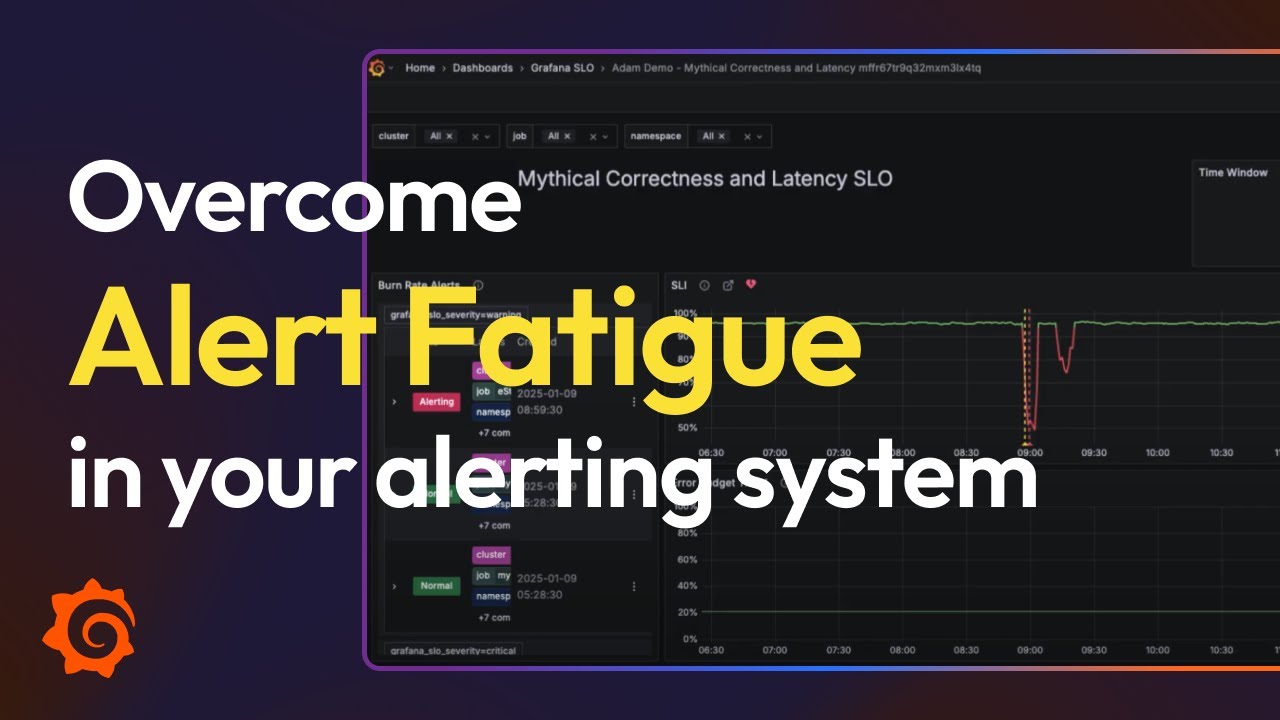
Reduce noisy alerts and alert fatigue
Noisy alerts are a major challenge for teams managing critical services. When monitoring systems generate alerts for every minor issue, engineers struggle to distinguish what’s critical from what’s not, leading to analysis paralysis.
SLOs solve this by shifting the focus from interpreting raw metrics to monitoring user impact. Instead of triggering alerts for small latency spikes, you only alert when performance trends toward breaching an SLO. This reduces alert fatigue and ensures that alerts are actionable and urgent.
SLOs help with prioritization
Without SLOs, teams often chase perfection across all aspects of their systems. While admirable, striving for 100% reliability everywhere is unrealistic and it can lead to wasted resources and burnout.
SLOs let you focus your efforts where they count. For example, you might aim for 99.9% uptime on your API while accepting slightly lower reliability for internal admin tools that don’t directly impact customers. This targeted approach prioritizes critical user journeys, aligns reliability goals with business objectives, and fosters collaboration across teams.
Red light, green light for innovation
Deciding whether to resolve technical debt or build innovative features can feel like a gamble. But SLOs include error budgets—a built-in mechanism for balancing reliability and innovation.
Error budgets define how much unreliability you’re willing to tolerate within a given period. If the budget is exhausted, the team prioritizes fixing issues over launching new features. This systematic approach reduces firefighting, prevents burnout, and ensures long-term service health.
Gain cross-functional alignment
SLOs aren’t just for engineering—they bridge the gap between technical and business teams. By translating technical reliability goals into business-relevant terms, SLOs create a shared language for success. This fosters collaboration and strategic decision-making, with tools like Grafana SLO providing real-time performance visibility across the organization.
Steps to establish successful SLOs
Teams often want to adopt SLOs, but they struggle to implement them, which can lead them to abandon the project altogether. This is why it’s important to carefully plan, execute, and iterate.
To start, identify key user journeys, set realistic targets, and ensure that the right tools are in place to measure performance. With a structured approach, teams can refine their SLOs over time for better reliability and user satisfaction.
- Identify key user journeys or services. Focus on critical interactions that define the user experience. Start small, perhaps with a service tied to an SLA, and evolve over time.
- Set realistic, meaningful targets. Use historical performance data and customer expectations to define ambitious yet achievable thresholds. Involve stakeholders to ensure alignment.
- Use the right tools. Invest in tools like Prometheus and/or Grafana Cloud to monitor, visualize, and analyze system performance. Focus on actionable metrics tied to SLOs.
- Establish error budgets. Define acceptable deviations to balance reliability with innovation. Use error budgets as a strategic tool for prioritization and accountability.
How to gain cultural adoption
Now that you’ve worked through the importance of SLOs and a high-level overview of the steps to getting started, let’s spend a few moments talking about the really tricky part: getting buy-in from across your organization.
Yes, individual teams will still see some benefits from adopting SLOs, but the real meaningful change happens when SLOs are incorporated throughout your company’s entire engineering culture.
Start small
Begin with a pilot program, rather than trying to roll out SLOs organization-wide. Choose a single service that has clear user impact and manageable complexity. For example, you might start with a customer-facing API or a core service that drives significant business value. Use this pilot to refine your process for defining, measuring, and iterating on SLOs.
This allows you to demonstrate the tangible benefits of SLOs without overwhelming your teams. Share the results of the pilot, including lessons learned and positive outcomes, to build momentum and buy-in for broader adoption. This iterative approach ensures that your organization has a solid foundation before scaling SLO implementation across multiple teams or services.
Educate and align teams
Start by explaining the foundational purpose of SLOs to your teams. Emphasize that SLOs are not just technical metrics but tools that bridge the gap between engineering efforts and business goals.
Host workshops, training sessions, or lunch-and-learns to introduce the concept and demonstrate how SLOs directly improve reliability, efficiency, and user satisfaction. For instance, you could showcase real-world examples of how SLO-driven decisions have reduced downtime or prevented costly incidents.
For the fastest buy-in, connect SLOs to tangible business outcomes. Explain how meeting SLOs can reduce customer churn, enhance user trust, and even drive revenue by improving the overall experience. For example, meeting a 99.9% uptime SLO for a payment API might directly correlate with fewer abandoned transactions, thereby increasing revenue.
By making this connection clear, you’ll help teams see SLOs not as additional work but as critical to achieving organizational success.
Make SLOs visible
Visibility is essential for ensuring that SLOs remain top of mind for all stakeholders. Create dashboards that prominently display real-time SLO performance, making them accessible to both technical teams and business leaders. Tools like Grafana can visualize metrics in a way that’s easy to interpret.
Sharing these dashboards fosters accountability and transparency. For example, a dashboard showing that an SLO is at risk of being breached can prompt immediate action from the team. Additionally, regularly sharing SLO performance in team meetings or company-wide updates helps maintain focus and alignment.
When SLOs are visible, you create a culture where everyone is invested in achieving reliability goals.
Celebrate wins and learn from breaches
Incorporate SLO reviews into your regular workflows so they remain relevant and actionable. For example, include SLO discussions in retrospectives, sprint reviews, or quarterly planning meetings. Use these opportunities to evaluate performance, identify trends, and adjust targets or error budgets as needed.
Celebrate successes when teams achieve or exceed their SLOs. Recognition reinforces the importance of SLOs and motivates teams to maintain high standards. When breaches occur, treat them as opportunities for learning rather than failures. Conduct postmortems to understand the root cause and identify improvements, but avoid assigning blame. This approach fosters a culture of continuous improvement and resilience, helping your organization grow stronger with every challenge.
Positive outcomes from implementing SLOs
When done right, SLOs deliver transformative results for your organization:
- Enhanced user satisfaction. Focusing on the right metrics ensures that your efforts directly impact user experience. This leads to fewer complaints, improved customer retention, and higher Net Promoter Scores (NPS).
- Reduced alert fatigue. By tying alerts to SLO breaches rather than raw metrics, teams experience fewer distractions and can focus on solving meaningful problems.
- Balanced innovation and reliability. Error budgets empower teams to take calculated risks, knowing there’s a clear framework for prioritizing reliability when needed.
- Stronger collaboration across teams. With shared goals and clear communication, SLOs break down silos and improve collaboration between engineering, product, and business teams.
SLOs aren’t just a technical tool—they’re a strategic advantage for delivering reliable, user-focused services while balancing innovation and operational efficiency.
If you’re looking to achieve the outcomes we’ve discussed in this post, Grafana SLO can help teams create, manage, and scale SLOs. It simplifies the process of setting SLOs by generating user-defined dashboards and error budget alerts. This helps teams get started quickly as well as iterate on their SLOs overtime. If you’re ready to get started, try Grafana SLO for free on Grafana Cloud and take the first step toward proactive reliability.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!