
Grafana LLM plugin updates: choose the large language models and providers that work best for you
At Grafana Labs, our mission has always been to empower users with the tools they need to build their own observability solutions. Our big tent philosophy embodies this mission by allowing you to choose the tools and technologies that best suit your needs.
In this post, we want to share an update to our LLM plugin that reflects this philosophy in action. As of the 0.10.0 release earlier this year, the Grafana LLM plugin, which provides centralized access to large language models across Grafana, now supports open-weights models and non-OpenAI providers. This offers you greater flexibility to choose the LLMs and providers that best meet your needs in terms of performance, privacy, and cost.
An overview of the Grafana LLM plugin
The Grafana LLM plugin — currently in public preview in Grafana OSS, Grafana Enterprise, and Grafana Cloud — leverages generative AI to simplify your workflows. More specifically, the plugin helps you leverage LLMs to:
- Annotate your dashboards and panels with more descriptive titles
- Automatically generate incident summaries
- Explain log patterns in a more human-friendly way
- Analyze complex flame graph profiles withFlame graph AI (shown below)
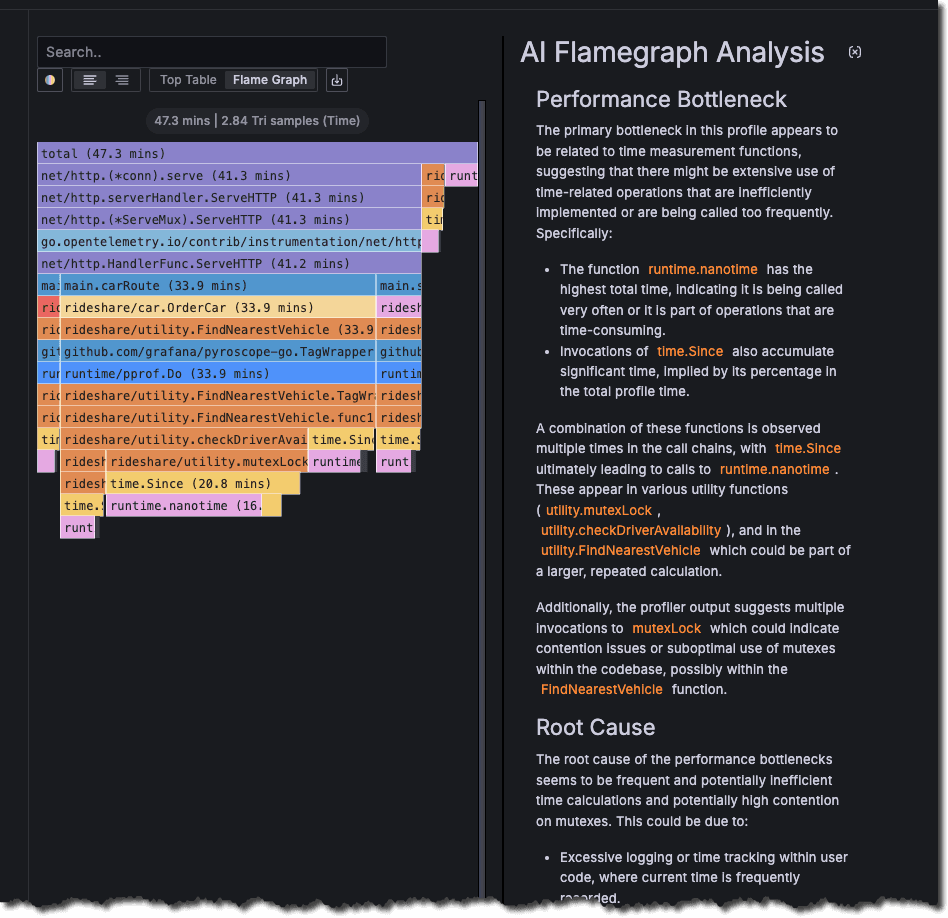
The update we made in the 0.10.0 release makes these capabilities more accessible, no matter which LLMs or LLM provider you prefer, by allowing you to choose what works best for you and to balance cost, performance, and privacy.
Unified support for LLMs
Initially, Grafana’s LLM features were exclusive to models from OpenAI, leveraging their powerful GPT models. While these models are remarkable, we recognized the need for flexibility. With the latest update, you now have the freedom to integrate any model you prefer, as long as it is behind an OpenAI-compatible API and supports a system prompt.
This means you can now take advantage of:
- Self-hosted models: You can use powerful open source models like Llama 3 and deploy them independently to gain full control over your data and model management.
- Support for alternative LLM providers: Through OpenAI-compatible proxies, such as LiteLLM, you can tap into models from different providers such as Google’s Gemini or Anthropic’s Claude, no matter which cloud service you’re using.
To make this transition as seamless as possible, we are presenting two simplified options: a Base model for cost-effective LLM completions (e.g., gpt-4o-mini) or a Large model for use cases that require more advanced capabilities or larger context windows (e.g., gpt-4o). Grafana administrators can override these defaults and pick custom models that balance cost, performance, and privacy.

Some OpenAI-compatible API proxies, such as LiteLLM, have additional routing capabilities, allowing you to use different models from different providers (including your own self-hosted provider) for either the Base or Large model, depending on your unique needs and requirements.
Getting started with custom LLM providers
To use an alternative provider or self-hosted LLM model, follow these simple steps:
- Configure the plugin:
- In the plugin settings, select Use your own OpenAI Account.
- Set the OpenAI API URL to point to your self-hosted API (e.g. http://vllm.internal.url:8000/).
- Map your custom models in Model Settings > Model mappings by specifying the
BaseandLargemodel (e.g.,meta-llama/Meta-Llama-3-8B-Instruct).
That’s it! You can now enjoy Grafana’s LLM-powered features with your chosen model. On top of that, you now have the option to change the default model used to Base or Large, depending on your needs.
Benchmarking non-OpenAI LLMs on Grafana
As we opened the doors to bringing your own LLMs, we wanted to ensure that Grafana’s AI features still work as expected when using non-OpenAI options. This is easier said than done, since it’s not easy to guarantee a prompt still works consistently across diverse providers and open LLM models.
Part of our testing approach was to benchmark our AI features across some popular LLMs. We discovered that the current prompt structure wasn’t reliable for a subset of models (particularly llama3), since it was using multiple system prompts. By being able to test different approaches, we were able to improve it and make sure our features still work as best as they can, regardless of the model you choose.
Benchmark results
Model
Panel description \N=841
Panel title \N=841
Dashboard title \N=506
gemini-1.5-flash
78.1%
82.0%
67.2%
claude-3.5-sonnet
78.4%
80.5%
68.7%
gpt-4o-2024-05-13
77.8%
81.3%
66.1%
gpt-4o-mini-2024-07-18
78.0%
80.7%
66.8%
gpt-4-turbo-2024-04-09
77.6%
79.4%
66.9%
gpt-3.5-turbo-0125
76.3%
77.8%
63.6%
llama3:8b-instruct
73.0%
73.1%
65.0%
llama3.1:8b-instruct (AWQ)
76.7%
70.9%
63.1%
llama3:8b-instruct (pre-fix)
59.2%
58.5%
64.1%
As expected, larger models deliver better performance, and by supporting smaller models, as well, we provide more flexibility and options for trading off cost and performance.
What’s next for LLMs in Grafana?
As we’re looking ahead, we want to bring more LLM capabilities to Grafana developers and continue to embrace our big tent philosophy.
One of the features we’re excited to explore is enabling function calling and tool integration. This would allow developers to use LLMs to interact with Grafana to, for example, create new incidents or update dashboards.
A recent Grafana Labs hackathon project experimented with the Model Context Protocol (MCP) and created a Grafana MCP server that offers this functionality and more. This lets users ask questions of their Grafana instance from any compatible MCP client, such as Claude Desktop or Zed. Furthermore, it paves the way to a more agentic approach to interacting with Grafana: imagine being able to chat with your Grafana instance from Slack, with an assistant that can search for relevant dashboards, add comments to incidents, or start Sift investigations.
Stay tuned to learn more, as we continue to build out LLM capabilities in Grafana.

