Organizing your Grafana k6 performance testing suite: Best practices to get started
In 2017, we open sourced Grafana k6 and made its first beta available to everyone. This wasn’t our first rodeo — k6 marked the third load testing tool our team had developed over a decade. We had recognized the gaps in existing solutions, as well as the barriers that were hindering adoption in the developer community.
The plan was simple yet ambitious: let’s build a tool developers actually enjoy using and that helps engineering teams build more reliable software. k6 was our team’s first scriptable tool in JavaScript.
We’ve come a long way since those early days, but we still hear the same common question from new users: “How should I structure my performance testing projects using k6?”
In this blog post, we offer some guidelines to get started with Grafana k6, and then share a list of best practices to organize your performance testing suite. Whether you use open source Grafana k6 or Grafana Cloud k6 — our fully managed performance testing platform — these practices will help you plan and ramp up faster.
Getting started with k6
For many teams, getting started with k6 — or performance testing, in general — is a new journey. Our general advice is straightforward and aims to demystify the process:
- Treat it as you would any other kind of testing suite.
- Start simple and then iterate. Basic continuous testing is better than no testing at all.
Let’s dig into each of these points a little more.
Treat it as you would any other kind of testing suite
Engineering teams often start with performance testing after they have experienced severe reliability issues. But to be more proactive, and address potential reliability issues before they occur, you should embrace performance testing just as you do any other type of frequent testing.
Maybe, for other types of testing, you prioritize based on the risk of failure, on critical business flows, or the frequency of an issue. You can adopt the same strategies and principles when approaching performance testing with k6. (Though, there are some specific things to keep in mind — more on that below.)
Start simple and iterate
It all starts with a few tests, and as the team gains more experience and confidence, the performance testing suite naturally expands. The key to success in performance testing, just like in other types of testing, lies in adopting a continuous testing approach. (I’ll forgo delving into the “why” in this blog, but for an insightful read on the topic, check out this article by my colleague Marie Cruz, which pairs nicely with the k6 automation guide.)
It is just another testing suite — but often has a broader scope
Again, we want you to treat performance testing like any other type of testing. That said, it is crucial to acknowledge the specific characteristics of performance testing, and debunk the myth that is hard.
I hear “performance testing is hard” every now and then from performance engineer experts, but my view is quite different. The difficulty often comes from siloed operations, not from the performance testing practice itself.
More specifically, the challenges often arise when those leading the testing efforts are not fully versed in operating the system or its implementation details. In this case, writing tests, understanding the system’s performance, and investigating potential issues will indeed be tough. If you find yourself in this situation, work closely with developers to “shift testing left” and adopt an all-team testing approach.
As a developer, if you have some testing experience, the practice of performance testing is relatively simple. Simply put, it’s like automated functional testing, but with an added dimension of load. Data parameterization, while can be tricky, is certainly manageable.
Think of it as a cycle: test, develop, test again. Rinse and repeat until you can verify the system performs as expected (based on your key reliability metrics) under the simulated load.
There are a few aspects to keep in mind that make performance testing distinct from other testing types, and these aspects influence the design of our testing suites:
- Different testing environments. Our system or application is typically deployed in multiple environments: development, QA, pre-production, production, etc. It’s common to run the same test in various environments for different purposes, normally with distinct workloads (which leads me to my next point…)
- Testing with distinct workloads. The system under test often performs differently under medium traffic, high-load traffic, and peak traffic. Hence, it is common to run different load test types to verify the performance under expected traffic patterns.
- Reliability is a team effort. Application reliability depends on the reliability of the underlying subsystems. No matter the organizational approach to reliability and QA, or the testing method, it is critical that all teams responsible for these distinct systems and services participate in testing.
These aspects introduce challenges that require a flexible testing approach.
Four best practices for performance testing suites
Over the years, the k6 team has observed a few common patterns in performance testing suites. Here, we’ll outline these common and general best practices, which also include recommendations from Grafana k6 Champions Grzegorz Piechnik, Krzysztof Widera, Paul Maxwell-Walters, and Sahani Perera. We thank them for sharing their expertise with the community!
Note: The sections below provide an overview of patterns, and the examples are intended as references. Each project may implement these patterns in its own unique way.
1. Modularize test configurations
Modular tests become essential to enable the reuse of tests across distinct environments and workloads. This modular approach provides greater flexibility, enhances test maintenance, and facilitates collaboration among team members.
To get started, use environment variables to specify different base endpoints:
k6 run -e BASE_URL=https://pizza.grafana.fun script.jsYour test script can then read the value through the __ENV variable, ensuring the test code remains unchanged:
const BASE_URL = __ENV.BASE_URL || 'http://localhost:3333';
let res = http.get(`${BASE_URL}/api/pizza`);Alternatively, you could use a key-pair object to store settings for each environment. This is preferable when there are multiple settings per environment:
const EnvConfig = {
dev: {
BASE_URL: 'http://localhost:3333',
MY_FLAG: true
}
qa: {
BASE_URL: 'https://pizza.qa.grafana.fun',
MY_FLAG: true
},
pre: {
BASE_URL: 'https://pizza.ste.grafana.fun',
MY_FLAG: false
},
prod: {
BASE_URL: 'https://pizza.grafana.fun',
MY_FLAG: false
}
};
const Config = EnvConfig[__ENV.ENVIRONMENT] || EnvConfig['dev'];
const BASE_URL = Config.BASE_URL;Note: Remember not to store sensitive data in your config files. For cloud-based tests, consider using cloud environment variables.
Our previous test could now run against the four environments hosting the application. For instance:
k6 run -e ENVIRONMENT=prod script.jsWe can also apply this same approach to distinct workloads (traffic). For the sake of simplicity, use the same method for setting up the k6 workload, either stages or scenarios. Here is an example using stages:
const WorkloadConfig = {
average: [
{ duration: '1m', target: 100 },
{ duration: '4m', target: 100 },
{ duration: '1m', target: 0 },
],
stress: [
{ duration: '1m', target: 700 },
{ duration: '4m', target: 700 },
{ duration: '1m', target: 0 },
],
smoke: [{ duration: '10s', target: 1 }],
};
const stages = WorkloadConfig[__ENV.WORKLOAD] || WorkloadConfig['smoke'];
export const options = {
stages: stages,
};Our test is now configured to run with three different workloads. Thus, we have one test designed to target three workloads and four environments — 12 combinations from a single test.
We aim to create other tests for various scenarios, such as different APIs or user flows. Naturally, the idea of reusing the workload and environment settings seems ideal, right? We’ll do that. However, it’s important to remember that not every test and environment are appropriate for all workloads.
Not all user flows receive the same amount of traffic. Some actions handle more traffic than others. It is often appropriate to differentiate workloads into sublevels such as averageLow and averageHigh, for scenarios with lower or higher traffic.
Not all the tests are executed in all environments. Each environment configures a distinct infrastructure setup and supports different capacities. Development or QA environments do not set up the same resources and scalability policies as production or pre-production. It makes little sense to run a stress test in environments without a high-availability setup.
Focus on performance regressions. Pre-release environments rarely replicate the infrastructure of your production environment completely. Do not expect both environments to perform equally under the same traffic. We should not be obsessed with using the same workload for all environments. The goal is to establish a workload for a performance baseline and then conduct frequent tests to identify performance changes (regressions).
Considering these aspects, our workload settings might have evolved into the following:
// config/workload.js
export const WorkloadConfig = {
smoke: [...],
stag: {
averageLow: [...],
averageMed: [...],
averageHigh: [...],
stress: [...],
},
pre: {
averageLow: [...],
averageMed: [...],
averageHigh: [...],
stress: [...],
peak: [...],
},
prod: {...}
};The previous snippet is a basic example for demonstration purposes. Different teams might have distinct approaches to organizing config files. Some teams might use only one config file for both environment and workload settings, while others may prefer to split config files by data types, as shown below:
├── config/
│ ├── workloads.js
│ └── settings.js
├── test1.js
└── test2.jsAnother alternative is to separate config files by environments and use a Bundler to load only the necessary settings. An example is shown below, and to learn more, you can read our related blog post on JavaScript tools, modules, and TypeScript:
├── config/
│ ├── dev.js
│ ├── pre.js
│ └── prod.js
├── test1.js
└── test2.jsFeel free to organize these config files how it best suits your specific environments and testing processes. It’s likely that you’ll go through a few iterations, creating several more tests, until your config setup becomes more stable.
Even though every testing environment and scenario is unique, certain groups of tests often share scopes and implementation details. Therefore, these and many other k6 options can be modularized to further optimize your k6 testing suite.
Thresholds is a common and important one to consider. It is very likely that you have defined some common thresholds across all the tests or within specific groups of tests. To conclude this section, here is an example of modularizing thresholds:
export const ThresholdsConfig = {
common: {
http_req_duration: ['p(99)<1000'],
http_req_failed: ['rate<0.01']
},
pre: {
instant: {
http_req_duration: ['p(99)<300'],
},
},
prod:{}
};Then, a test can import and configure its thresholds as follows:
import { ThresholdsConfig } from './config/thresholds.js';
let thresholds = Object.assign({}, ThresholdsConfig.common, ThresholdsConfig.pre.instant);
export const options = {
thresholds: thresholds,
};2. Implement reusable test scenarios
Each environment where our application runs typically serves a different purpose. Thus, it is common to run the same “test scenario” — meaning the same virtual user (VU) and test logic — across multiple environments, each with a different objective in mind.
For instance, a smoke test (minimal load) might run in the QA environment for functional testing or to check test errors. Then, the same test scenario could be executed against the pre-release environment to verify SLO metrics, while nightly tests are scheduled in production to assess performance changes. In short, the same scenario is tested in multiple environments for different goals.
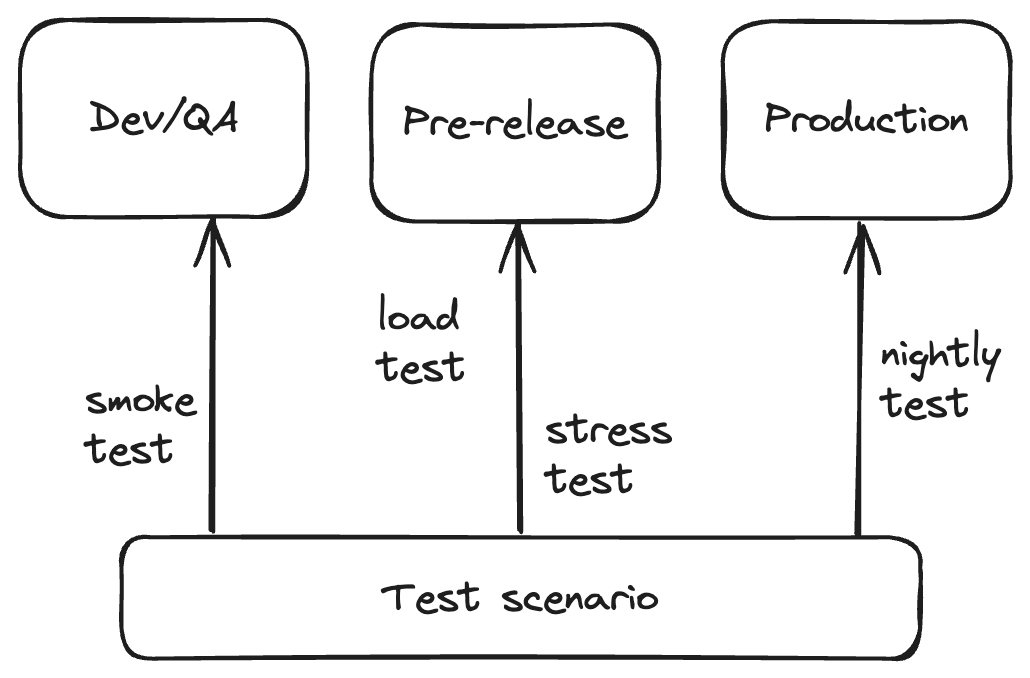
In cases like these, or when you want to run a scenario in conjunction with an existing test, it’s necessary to implement reusable test scenarios (VU logic). Here’s an example structuring tests and modular scenarios:
├── scenarios/
│ ├── e2e/
| │ ├── checkout.js
│ | └── read-news.js
│ └── apis/
│ └── account.js
├── tests/
│ ├── smoke-read-news-test.js
│ ├── pre/
| │ ├── stress-read-news-test.js
│ | └── avg-read-news-test.js
│ └── prod/
│ └── nightly-read-news-test.jsWhen reusing scenarios, avoid coupling scenario logic with other testing concepts. Consider the following guidelines:
- Implement modular scenarios that can extend their default behavior.
- Make the usage of custom metrics optional.
- Avoid the use of groups.
- Tag requests and checks (and custom metrics when appropriate).
- For more flexibility, use scenarios to set the workload.
Do not overthink it. Start by implementing scenarios with the intention of reusing them across multiple tests. When you plan a new test, a common question is whether to extend an existing test or to create a new one.
In most cases, we recommend avoiding multi-purpose tests and suggest a new test for each scenario, with one primary purpose in each environment, as mentioned earlier. This prevents mixing responsibilities and helps track historical results of the same test to identify performance changes during large periods.
If you have modularized test configurations and test scenarios, creating a new basic test could be as simple as importing some modules and adjusting a few settings:
// tests/pre/avg-read-news-test.js
import { WorkloadConfig, EnvConfig } from './config/workload.js';
import ReadNewsScenario from './scenarios/read-news.js';
const Config = EnvConfig.pre;
const stages = WorkloadConfig.pre.averageMed;
export const options = {
stages: stages,
}
export default function () {
ReadNewsScenario(Config.BASE_URL);
}This example showcases how easily new tests can be created by reusing existing modules.
3. Create object-oriented models for data access
Implementing an API client is a common pattern for interacting with various types of APIs, such as RESTful or GraphQL. An API client encapsulates the requests to the backend, abstracting away the implementation details of the API and k6.
As the complexity of the requests increases or the testing suite grows, an API client becomes our central point, making interactions with the backend easier. Should the APIs change, then only the client needs to be updated — not all the tests.
This pattern also makes it faster to write new tests and easier to understand testing code. This is particularly useful for team collaboration, and especially important when team members are not well-versed in the API specifications or k6 APIs.
The following client includes methods to access all the API resources:
export class APIClient {
constructor(token, baseUrl, addCheck) {...}
create(type, data, options) {... return {data, res};}
find(type, id, options) {... return {data, res};}
update(type, id, data, options) {... return {data, res};}
remove(type, id, options) {... return {res};}
}The example above serves as a basic reference. Depending on the API, you might choose one general client or multiple clients, each for a specific API scope, extending from a BaseClass.
The methods of this pattern should encapsulate the logic to retrieve and manipulate the data, providing an intuitive API for other testers. These methods should always return responses, enabling each test to manage responses and their data according to its particular scenario.
As general advice, refrain from incorporating additional responsibilities into the client and avoid custom behavior for non-general cases. Some people favor a client without extra responsibilities, while others prefer to include general-purpose logic, such as:
- Verifying the expected response status using checks
- Handling the reporting of error responses
An object-oriented model that encapsulates the details of interacting with data is a common software pattern, and one that can be beneficial in performance tests. This pattern is not restricted to HTTP requests, as it can be a useful abstraction for any type of interaction with data or protocols in our test code. For example, here is a page object example using k6 Browser to interact with HTML page elements.
4. Create an error handling wrapper
If you have already started with k6, you might have noticed that k6 OSS reports limited error information by default. It only outputs the rate of failed HTTP requests, http_req_failed:
http_req_failed................: 36.36% ✓ 40 ✗ 70As a result, users often include checks to verify response statuses and understand what happened to each specific request.
check(res, {
'GET item is 200': (r) => r.status === 200,
});✗ GET item is 200
↳ 63% — ✓ 70 / ✗ 40However, remember that if you stream k6 results (metric data points), these data points will include information such as response status. In this case, users can find response statutes without the need to implement these checks:

By default, checks don’t fail the test. Therefore, the k6 check API is commonly used for “informative” assertions; users tend to utilize checks to provide a custom report of the test execution.
✗ GET item is 200
↳ 63% — ✓ 70 / ✗ 40
✓ Add item is 201
↳ 100% — ✓ 110 / ✗ 0Yet, these checks lack additional error information and may require more detailed information to be more helpful when troubleshooting.
To gather more error information during the testing, our first recommendation is to focus on finding these errors through observability or by using the monitoring solution that instruments the application.
Traditionally, performance testing has focused primarily on gathering results within the testing tool itself, often operating independently. This results in a lack of visibility of the operational aspects of the system.
Start by understanding how the system operates and its telemetry data. Then, connect your testing results with observability data. You should be able to find all the errors in your observability solution, which will guide you in linking errors with their root cause. That’s the end testing goal. To learn more about how to connect testing data with observability data, refer to:
- Grafana dashboards for k6 OSS
- k6/experimental/tracing module
- Grafana Cloud k6: Correlate results in Grafana
Nevertheless, it can be useful to include error data in your test reports. In k6, there are two common options for storing additional error information:
- Log error data and output k6 logs to Grafana Loki or a file, or use Grafana Cloud k6.
- Create a custom counter metric to track error data.
Consider first which data to store depending on whether you’re handling a general or particular error, and based on the existing observability/telemetry data available.
Also, keep in mind that a high-load test can fail thousands or millions of times, potentially requiring you to store a vast amount of data. For instance, you might choose to store the endpoint URL, error message, the TraceID, or any relevant request or response details.
As a reference, here is an ErrorHandler example that accepts a callback to instruct the handler how to log the error details:
class ErrorHandler {
constructor(logErrorDetails) {
this.logErrorDetails = logErrorDetails;
}
logError(isError, res, tags = {}) {
if (!isError) return;
const traceparentHeader = res.request.headers['Traceparent'];
const errorData = Object.assign(
{
url: res.url,
status: res.status,
error_code: res.error_code,
traceparent: traceparentHeader && traceparentHeader.toString(),
},
tags
);
this.logErrorDetails(errorData);
}
}Next, instantiate the ErrorHandler and pass a custom callback to determine how to log the error details:
const errorHandler = new ErrorHandler((error) => {console.error(error);});
// or
const errors = new CounterMetric('errors');
const errorHandler = new ErrorHandler((error) => {errors.add(1, error);});Then, call it from the scenario or API client as follows:
checkStatus = check(res, { 'status is 200': (res) => res.status === 200 });
errorHandler.logError(!checkStatus, res);Next steps and sharing with the community
We hope these recommendations help you implement a better and more flexible performance testing suite. If you are looking for further guidance, be sure to check out our related blog post that explores how to set up a k6 performance testing suite using JavaScript tools, modules, shared libraries, and more.
You can also reference our guide on automating performance testing, which provides guidelines to establish a repeatable performance testing process.
A special thanks again to the Grafana k6 Champions who helped shape this post by sharing their expertise and experiences with us!
If you have your own recommendations or best practices that you’d like to share, please add them to our list of awesome k6 examples, as well as share them on Slack and in our Community Forum. Your insights are not only useful for fellow users, but also provide the k6 team vital information for considering future improvements.
And, as we always say: start simple and then iterate. Happy testing!