
How we improved ingester load balancing in Grafana Mimir with spread-minimizing tokens
Grafana Mimir is our open source, horizontally scalable, multi-tenant time series database, which allows us to ingest beyond 1 billion active series. Mimir ingesters use consistent hashing, a distributed hashing technique for data replication. This technique guarantees a minimal number of relocation of time series between available ingesters when some ingesters are added or removed from the system.
Unfortunately, we noticed that the consistent hashing algorithm previously used by Mimir ingesters caused an uneven distribution of time series between ingesters, with load distribution differences going up to 25%. As a consequence, some ingesters were overwhelmed, while the others were underused. In order to solve this problem, we came up with a novel algorithm, called spread-minimizing token generation strategy, that allows us to benefit from the consistent hashing on one side and from an almost perfect load distribution on the other side.
Uniform load balancing optimizes network performance and reduces latency as the demand is equally distributed among ingesters. This allows for better usage of compute resources, which leads to more consistent performance. In this blog post, we introduce our new algorithm and show how it improved ingesters load balancing in some of our production clusters for Grafana Cloud Metrics (which is powered by Mimir) to the degree that it’s now almost perfect.
Background: the problem and the solution
Mimir’s ingesters are registered in a hash ring, a distributed consistent hashing scheme used for sharding and replication. Each ingester is assigned a certain number of ring tokens that determine which portion of the ring is owned by that ingester. Mimir uses the hash ring to determine which ingester a time series is written to, or which ingester an in-memory time series is read from. Ideally, in-memory time series should be evenly distributed between ingesters.
Uniform load has multiple benefits:
- It prevents a single ingester from becoming overwhelmed with requests while others remain underutilized.
- It leads to a more efficient utilization of resources.
- It brings more predictability, as it gives the potential to tighten tolerances on alerts.
- It allows some cost savings, as CPU and memory resources are requested based on the average rather than the worst pod utilization of resources.
Unfortunately, the ingesters in Grafana Cloud Metrics production clusters used to suffer from uneven in-memory time series distribution. This problem was present in both clusters with and without shuffle sharding. Since the former have a more complex configuration and multiple possible reasons for unbalanced load distribution, we first dedicated our efforts to the latter.
After a deeper analysis we noticed a strong correlation between the portion of the hash ring owned by an ingester and the number of in-memory time series stored in that ingester. We have, therefore, managed to fix the ingester load balancing in our clusters without shuffle sharding by choosing the ring tokens in such a way that all ingesters own approximately equal portions of the hash ring. As we mentioned earlier, our technique is called spread-minimizing token generation strategy, and it gives rise to an almost perfect load balancing. We’ve already applied this approach to all of Grafana Cloud Metrics production clusters without shuffle sharding.
The following figure shows a per-pod number of in-memory series in a production cluster before (at the left) and after (at the right) the migration to the spread-minimizing tokens. You’ll notice that the difference between the minimum and the maximum values drastically decreased after the migration, showing how the load balancing improved.

The basics: ingesters, hash ring tokens, and spread
Hash ring tokens are 32-bit unsigned integers with values between 0 (included) and 232 (excluded). Each ingester owns the same number of tokens, tokensPerIngester, and no token is owned by more than one ingester at a time.
Coverage of a token T, coverage(T), is the portion of the ring between the token preceding T in the ring (excluded) and token T itself (included). Token ownership of an ingester I, tokenOwnership(T), is a sum of all the token coverages of all the tokens belonging to the ingester, and it represents a portion of the ring owned by I.
Ingesters have an optimal token ownership when they own equal portions of the ring. In order to measure an ingester’s load balancing, we use the notion of spread: the difference between ingesters with the minimum and the maximum number of in-memory time series. Analogously, we define the token ownership spread as the difference between ingesters with the minimum token ownership and the maximum token ownership. The spread is calculated as:
1 - min ( tokenOwnership ) max ( tokenOwnership ) .
Example ring
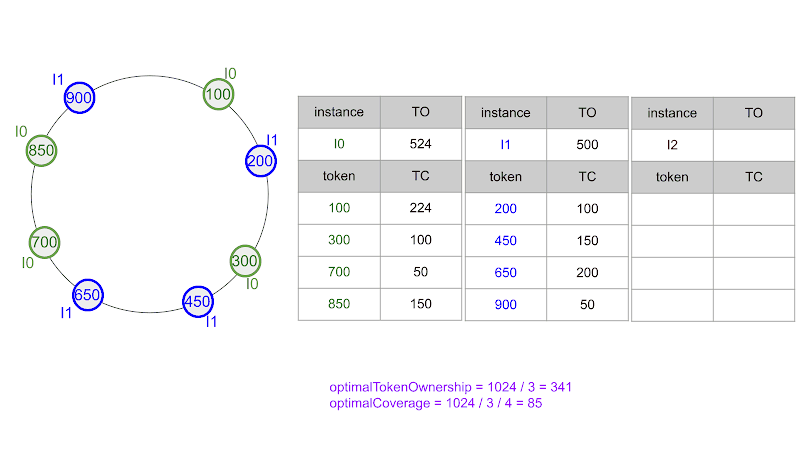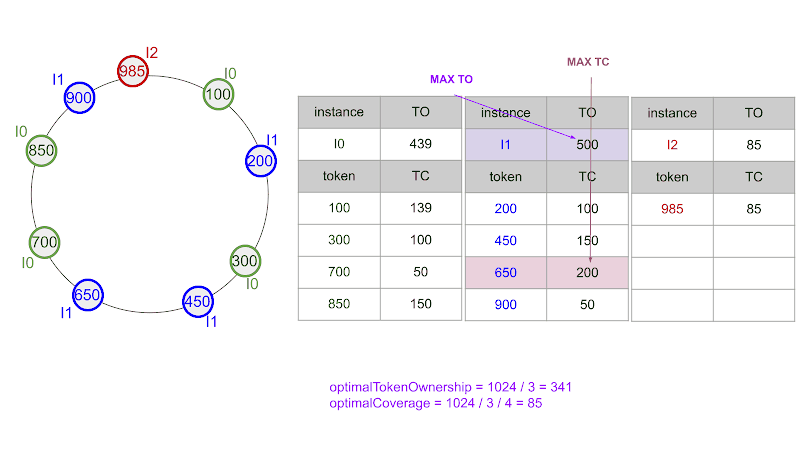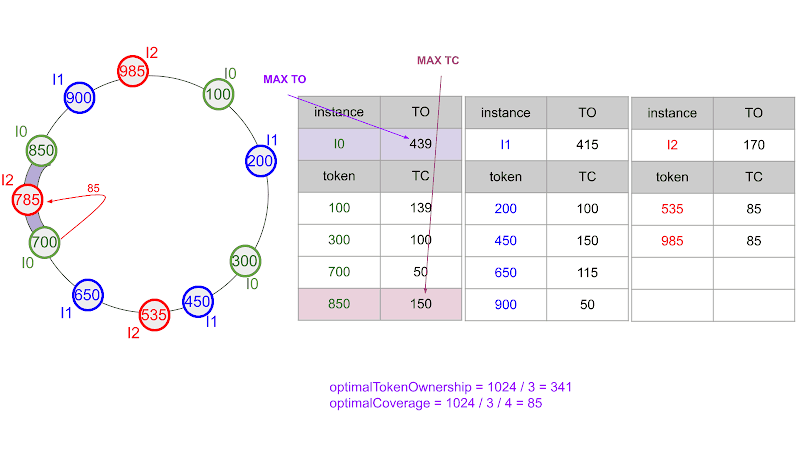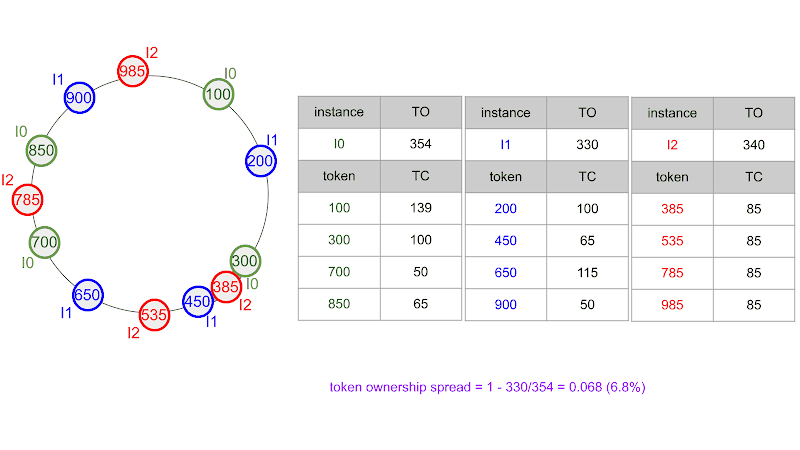
To illustrate these concepts, let’s look at an example that we can use in the rest of this article. In our examples each ingester owns exactly four tokens from the range [0, 1023]. Suppose that ingesters I0 and I1 are registered within a ring, with the following tokens (see the figure):
- I0 (green) owns tokens 100, 300, 700, and 850
- I1 (blue) owns tokens 200, 450, 650 and 900

The figure shows the ring with the eight tokens owned by instances I0 and I1, as well as a table reporting the token coverages. For example, token 450 covers the portion between tokens 300 (excluded) and 450 (included), i.e., 150 tokens. Analogously, token 100 covers the portion between tokens 900 (excluded) and 100 (included), i.e., 123 tokens (between 901 and 1023) plus 101 tokens (between 0 and 100), which are 224 tokens.
In order to calculate the token ownership of ingester I0, we sum up token coverages of I0’s tokens (100, 300, 700 and 850):
224 + 100 + 50 + 150 = 524.
Similarly, the token ownership of ingester I1 (owning tokens 200, 450, 650 and 900) is:
100 + 150 + 200 + 50 = 500.
Since this ring contains only two ingesters, the optimal token ownership would be 1024 / 2 = 512. The token ownership spread is: 1 - min ( 500 , 520 ) max ( 500 , 520 ) = 1 - 500 524 ≈ 0.046 = 4.6%.
Spread-minimizing token generation strategy
When a new ingester is added to a ring, tokensPerIngester tokens get assigned to the ingester. These tokens are fresh, i.e., they are not owned by any other ingester currently registered within the ring. By default, Mimir generates fresh tokens by the random token generation strategy, which simply chooses the tokensPerIngester tokens randomly.
With the current default of 512 tokens per ingester, this strategy gives rise to a very high spread of 15%-25% in our production clusters. Although our experience showed that higher values for tokensPerIngester slightly lower the spread, there is no mathematical proof for that. Moreover, since the tokens are random, two hash rings with equal values of tokensPerIngester and equal numbers of ingesters might have two different token ownership spreads.
Our goal was to define a new strategy with the following properties:
- Starting from a ring with a low token ownership spread, adding or removing an ingester keeps the spread low.
- It preserves the consistency property: Adding or removing an ingester from the ring implies remapping of at most 1/N the total number of in-memory series, where N is the number of ingesters in the ring.
- Different hash rings with equal values of tokensPerIngester and with equal numbers of ingesters have equal token ownership spreads and similar spreads.
The strategy we introduce in this section satisfies all the properties mentioned above. Unlike the random token generation strategy, which provides no guarantee about the spread, the new strategy ensures a low spread.
Strategy description
Now, let’s look at the main idea behind the spread-minimizing token generation strategy, which chooses the fresh tokens for a new ingester in such a way that its token ownership is optimal. Before introducing the algorithm, we would like to point out one of its main limitations: in order to guarantee the consistency property, we assume that the last ingester added to the ring is the first ingester to be removed from it. This is similar to the ordered Pod termination, which is the approach used by Kubernetes to scale down StatefulSets. Since our clusters ingesters run as StatefulSets, the strategy is perfectly applicable.
Let’s assume that we are adding the Nth ingester to the ring. As the total number of tokens is 232, the optimal ownership of this ingester would be optimalTokenOwnership=232/N. Our strategy executes tokensPerIngester steps, each of them choosing one fresh token with a coverage of approximately: optimalCoverage = optimalTokenOwnership tokensPerIngester .
This is achieved as follows:
- We choose the ingester with the highest token ownership in the ring. Let it be I.
- Among I’s tokens, we choose the token with the highest coverage. Let it be T.
- We place a fresh token at distance optimalCoverage from the token preceding T in the ring. This way both the coverage of T and the token ownership of I decrease by optimalCoverage, while the token ownership of the new ingester increases by the same value.
After all tokensPerIngester steps, the token ownership of the new instance is almost optimal. A deviation from optimality may be due to the calculation of optimalCoverage, since it depends on both tokensPerIngester and the number of ingesters in the ring, which are not necessarily divisors of 232. On the other hand, the token ownership of all other ingesters decreases by a multiple of optimalCoverage.
Let us consider our example ring again, and assume that we want to add a new ingester I2 with four fresh tokens. Since there are three ingesters and four tokens per ingester, optimalCoverage is 1024/(3*4)≈85. We apply the first step of the algorithm, while the remaining steps are illustrated by the animation in the figure below.
- The ingester with the highest token ownership is I0 (524).
- I0’s token with the highest coverage (224) is token 100, and it is preceded by token 900.
- The first fresh token is, therefore, 900+85= 985. The coverage of token 100 decreases to 224-85 = 135, while the token ownership of instances I0 and I2, respectively, decreases to 524-85 = 439 and increases to 85.
As the animation below shows, the tokens assigned to instance I2 after the last step are 385, 535, 785, and 985, while the token ownership of instances I0, I1, and I2 are 354, 330, and 340, respectively. Hence, the token ownership spread is: 1 - min ( 354 , 330 , 340 ) max ( 354 , 330 , 340 ) = 1 - 330 354 ≈ 0.0678 = 6.78%.
Implementation details
While the previous section explains the main idea behind Mimir’s spread-minimizing token generation strategy, it omits some more complicated implementation details. Let’s highlight some important features of the full implementation.
- Zone-awareness is required by the strategy: Although we illustrated a simplified version of the strategy, it is crucial to mention that it requires zone-awareness to be enabled, and that all the production clusters where the strategy has been applied actually satisfy that criterion.
- tokensPerIngester is fixed to 512, which corresponds to the number of tokens per ingester used by Mimir’s random token generation strategy.
- The fresh tokens assigned to the first ingester are: n * 232 tokensPerIngester + zoneID , where n is in the range from 0 (included) to tokensPerIngester (excluded), and zoneID is a numerical ID of the replication zone.
- The implementation is available in dskit, our OSS Golang library for building distributed systems, which is licensed under Apache 2.0.
How to enable spread-minimizing tokens for self-hosted clusters
As we’ve already discussed, you don’t need to make any changes if you’re using Grafana Cloud Metrics. However, if you’re using a self-hosted version of Mimir, your Mimir ingesters can be configured to use the spread-minimizing token generation strategy, too. Follow this guide to learn more.
A drastic improvement to load balancing, and what comes next
The spread-minimizing token generation strategy has been applied to all Grafana Could Metrics production clusters without shuffle sharding. This drastically improved the load balancing: The 15%-25% spread observed in the previously used random token generation strategy went down to 0.5%-1%, which is a great achievement.
More balanced time-series distribution allows for better resource usage, as well as some cost savings. Namely, a low spread means a low difference between the minimum and maximum number of per-ingester in-memory series. In other words, the lower the spread, the lower the maximum and the higher the minimum. Similarly, the lower the maximum per-ingester in-memory series, the less ingesters are needed to handle them. Following this logic, we managed to reduce the number of ingester replicas by 5%-10% in the clusters where the new strategy was applied.
In light of these results, we made the spread-minimizing token generation strategy the default for ingesters in all Grafana Cloud Metrics production clusters without shuffle sharding. If you’re using Grafana Mimir OSS or Grafana Enterprise Metrics, we strongly recommend doing the same in your clusters without shuffle sharding.
So far we have not applied the spread-minimizing token generation strategy to the clusters with shuffle sharding enabled, so we don’t have any evidence about its potential impact on the load balancing in those clusters. The problem with these clusters is that, beside a high token ownership spread due to the random token generation strategy, they face an additional issue: the algorithm that creates shards of ingesters. Put simply, this algorithm chooses each of the ingesters forming a shard S of a required size in the following way:
- It generates a random number number R
- If finds the first token than R, owned by an ingester I that does not belong to S
- It adds I to S
Additionally, shard sizes can grow over the time, which introduces additional randomness in the token and time series distributions. Therefore, we strongly believe that having a good strategy for assigning tokens to the ingesters within a ring, without improving the strategy for creating shards of those ingesters, would bring no real benefit because the overall process remains random. This is definitely one of the topics we want to further investigate in the future.
Moreover, it would be interesting to investigate whether the usage of spread-minimizing tokens would bring any benefit to other components using hash rings (Mimir or otherwise).
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!

