
The concise guide to Loki: How to get the most out of your query performance
Thanks for joining me for Part 3 of “The concise guide to Grafana Loki,” a series of blog posts that takes a closer look at best practices for various aspects of using the log aggregation system. Today’s post is my holiday present for all the folks out there running Loki who would like to get the most query performance they can out of their cluster.
My favorite part of working on the Loki project isn’t building it — it’s running it. It seems like I was born with a skill for finding problems, or maybe they like finding me; either way I love the process of investigating and troubleshooting issues. Today’s post is my attempt at taking all that I’ve learned about running Loki in regards to the topic of query performance and distilling as best as I can. The result will be quite dense, but hopefully there is something in here for everyone running Loki, regardless of the size of their installation.
Baseline best practices
Before I get into the details, there are a few general best practices you should be following that can make a huge difference. And since this is a concise guide to Loki (well, relatively concise), I’ll just briefly touch on on each one here:
- You should definitely read Part 2 of this series, which focuses on labels. And if you are doing things with your labels you shouldn’t be, fix that now.
- Upgrade! We are constantly making Loki faster, so make sure you are on the latest release! Always check with the upgrade guide when upgrading.
- Part 2 of this series also talks about automatic stream sharding. Make sure this is enabled, as it’s currently not enabled by default. You can see how to do so here. Loki’s sharding for querying is done at the stream level, similar to what happens for writes. Really large single streams cannot be split up, which limits query performance.
- In the opening paragraph of this blog I used the word “cluster.” You really need to be running Loki in the simple scalable deployment mode (SSD) or microservices mode to get to the higher levels of query performance. If you are using SSD mode, convert to the three target mode, which will make it much, much easier to add
readresources since they can be stateless.
*Note: If you are running Loki as a single binary in monolithic mode, you can parallelize it to some extent. However, if you are adding instances for performance reasons, Loki will do better if you run it in either SSD or microservices modes.*
- You should make sure you are using the TSDB index type. If you aren’t, or aren’t sure, check out these docs for switching to the TSDB index. While many of the concepts and settings talked about here will work with other index types to improve performance, the TSDB index type has some significant additional sharding capabilities that allow it to be faster for both large and small queries.
*Note: When changing the schema with a new entry, that entry must always be in the future. Be aware of your current time vs. UTC as the rollover will always happen at 00:00 UTC.*
- Use
snappyforchunk_encodingfor best performance. Snappy doesn’t compress as small when compared to GZIP (which is the default), but it’s much, much faster. We run all our clusters using Snappy for compression. Loki does support some other compression algorithms, such as Lz4 and Zstd, which produce smaller output files than Snappy and have similar performance. However, we have only really compared them in benchmarks and not at any larger scales.
*Note: Changing the
chunk_encodingcan be done anytime but it’s a forward moving change only; chunks created by a previous setting will stay in their previous format.*
- Caching, I believe, will get its own dedicated post in this series, but if you are impatient, you should make sure you have configured the results cache and chunk cache for Loki. The results cache saves Loki from doing the same work multiple times, mostly on metric queries. The chunk cache can help reduce I/O operations on your storage as well as improve performance.
- Storage. … You really, really should use a major cloud provider object storage to get the best performance out of Loki. Time and time again we have seen folks try to use an Amazon S3-compatible API in front of a self-managed storage system, only to be met with disappointment and frustration. Loki is a database capable of doing a tremendous amount of work on object storage — our largest Loki clusters will pull upwards of 1 Tbps of bandwidth from Google Cloud Storage and S3. We often find that self-managed storage solutions fall short of the performance capabilities of cloud managed object storage, at small and large scales. If this is your only option, you may have to temper your expectations around top-end query performance.
How queries work in Loki
Now that I’m a self proclaimed “animation expert” (See: Part 2), I thought a nice animation would help here.
The first step when Loki executes a query is to split it into smaller time segments:

Then each time segment is split again through a sharding process:
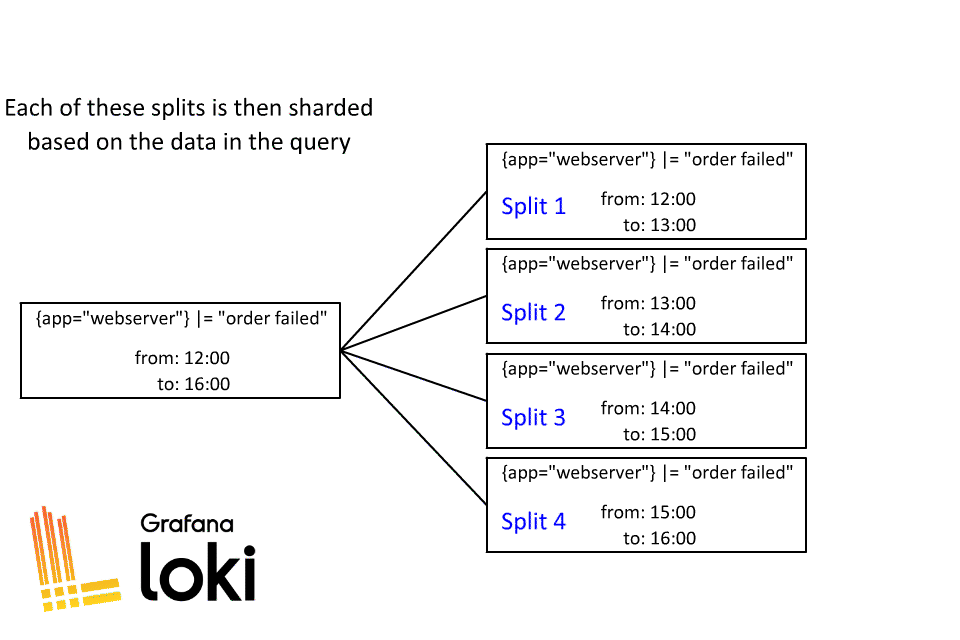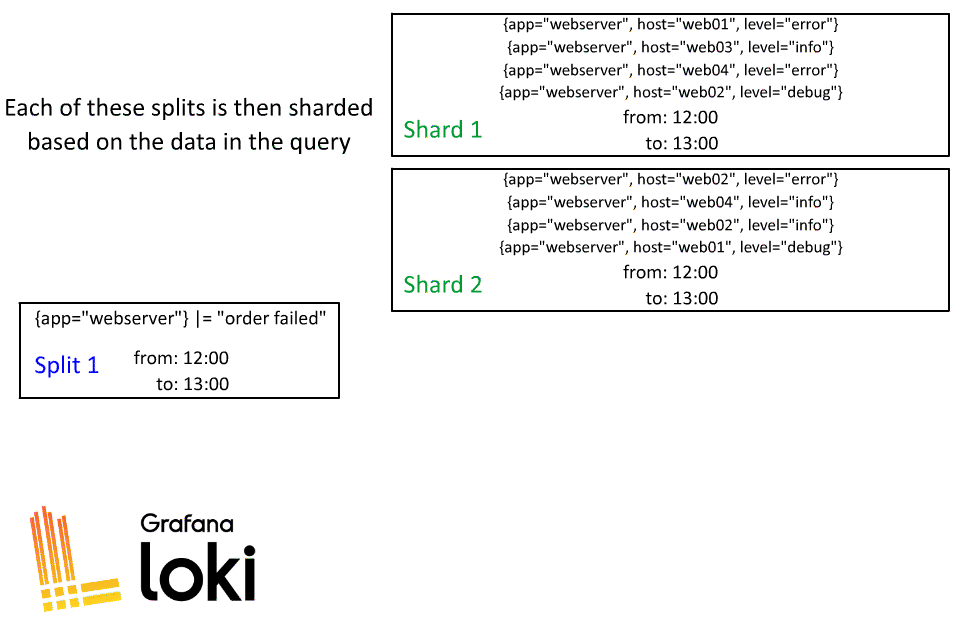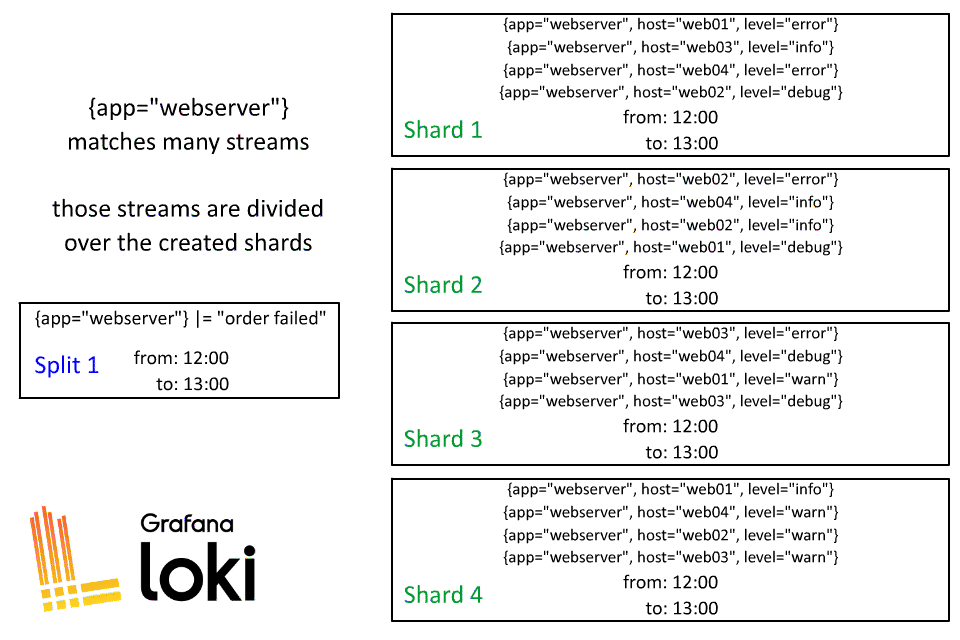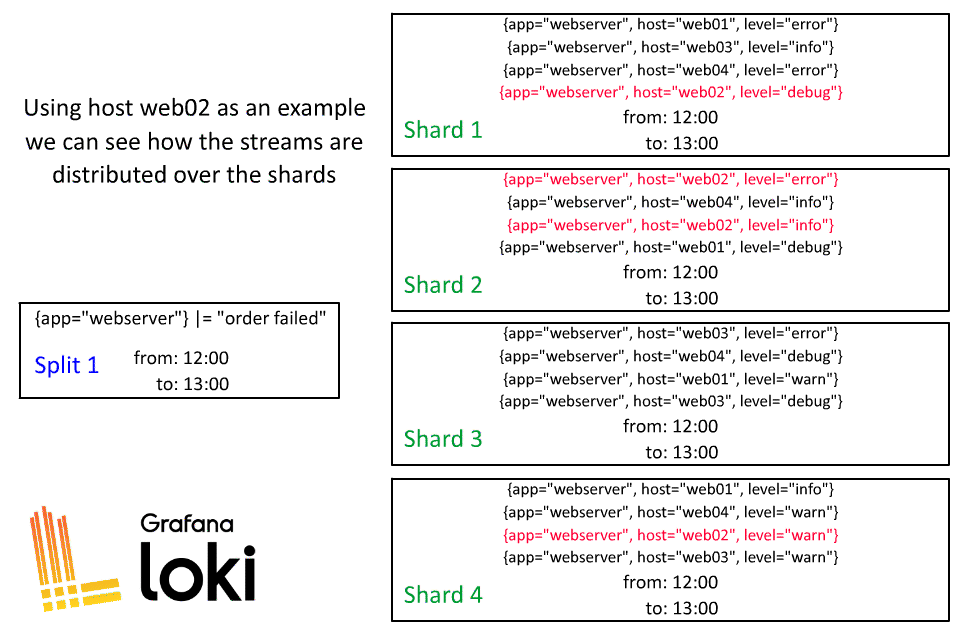
Sharding is a dynamic process in Loki, after the query is split by time, each of those splits then is divided into shards. The number of shards will be based on how much data will be processed, some splits may have a lot of shards while others may only have a few.
Once a query is split and sharded into subqueries, they are placed into a queue where a pool of querier workers will process all the subqueries.
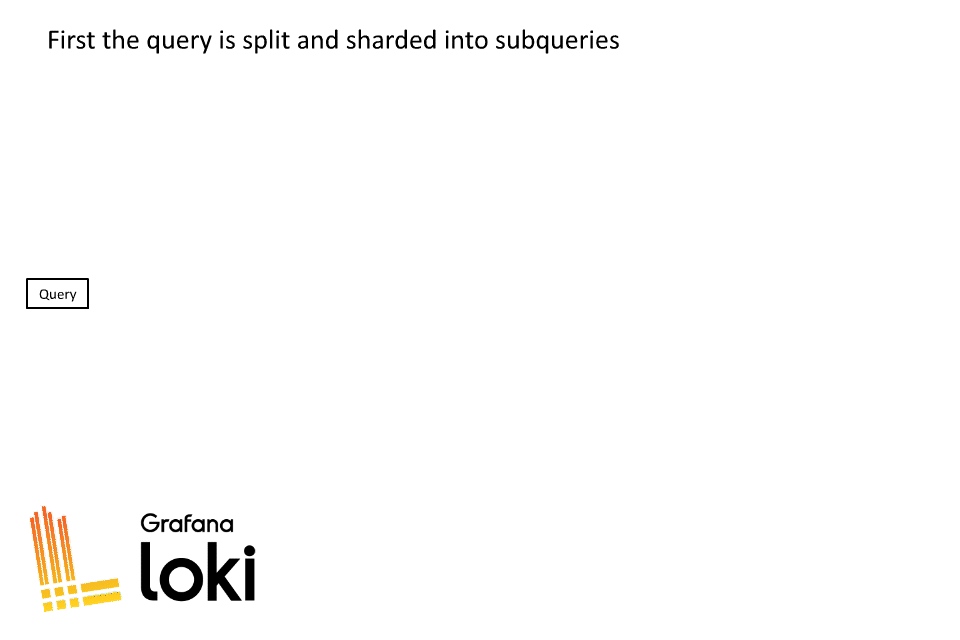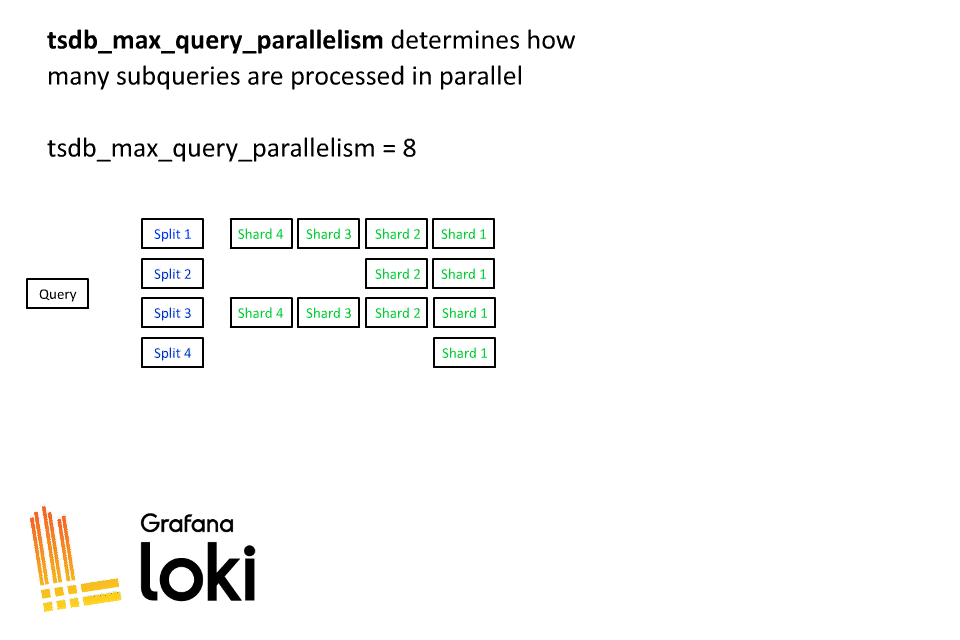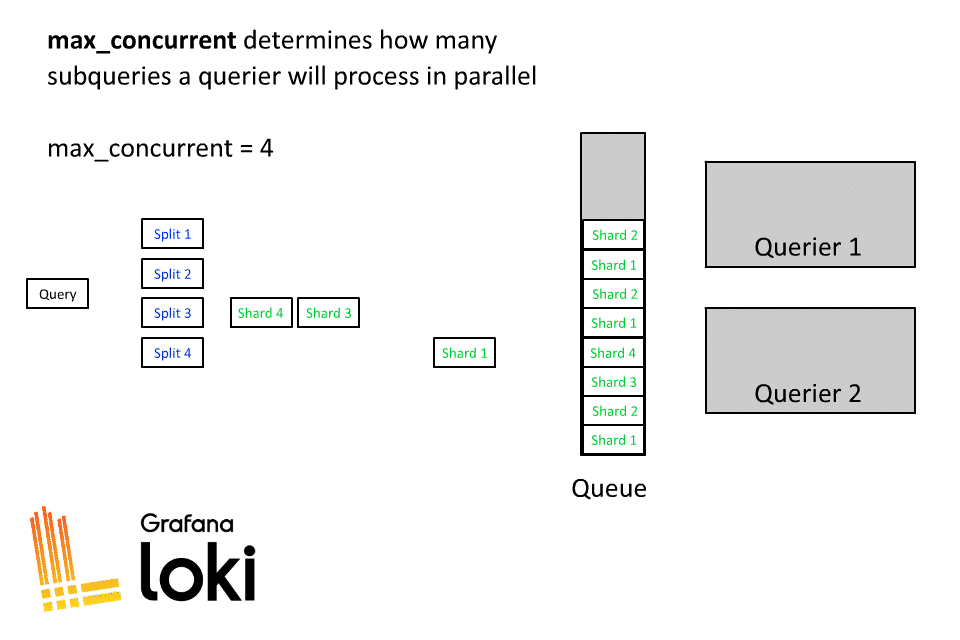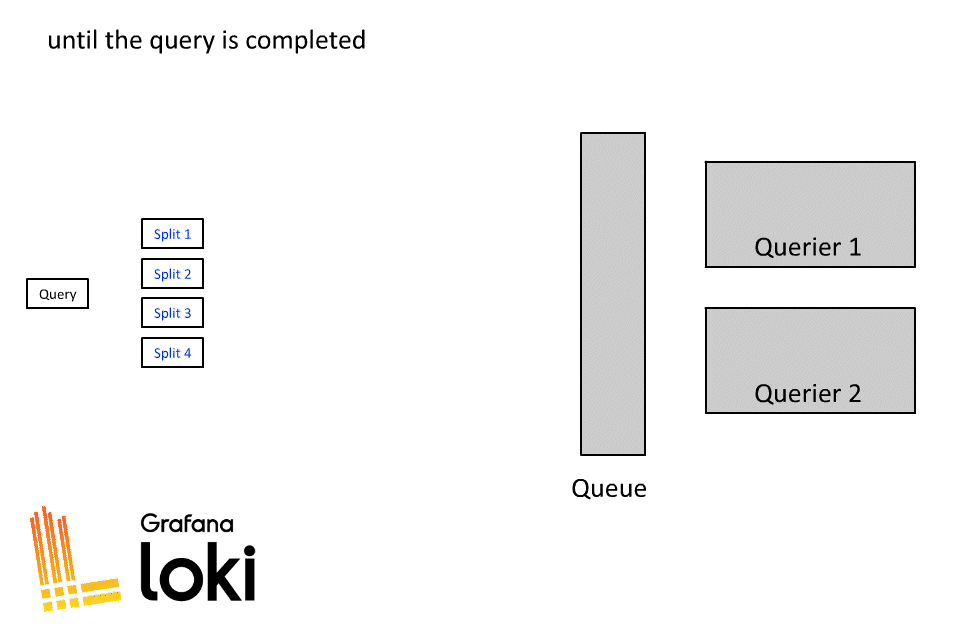
Where to start: Sizing and configs
Before you can even start troubleshooting performance issues, you need to have a rough understanding of your infrastructure and how it impacts your queries. Unfortunately, CPU and memory requirements are not entirely predictable — there are many types of queries that have very different requirements, depending on the machines that process them. However, to give you a reference point, we run our queriers with 2 CPU cores and 3 GB of RAM. More specifically, we run in Kubernetes and use requests of 2 CPU and 3 GB of RAM and limits of 5 cores and 12 GB of RAM. This works well for us as these can be scheduled in our environment fairly easily.
We run a max_concurrent setting of 8 and generally this is OK. If you have tighter requirements on resource usage, reduce max_concurrent. If you are seeing queriers crash on Out Of Memory, reduce max_concurrent (some amount of OOM crashing can be normal; Loki has a retry mechanism within queries, and queries often succeed just fine when they’re rescheduled).
*Note: Generally, we prefer horizontal scaling to vertical scaling with Loki. We’d rather run more components with smaller CPU/memory than fewer components with larger CPU/memory. You can definitely take the approach of running fewer queriers with higher CPU/memory and higher max_concurent, however, there are a couple disadvantages to this approach. The biggest impact can come from large queries that are executing in all the queriers that use a lot of memory and CPU. These queries can negatively impact the cluster or other users of the cluster. Also — admittedly, I’m not really an expert on this one — I believe the Go runtime goroutine scheduler may see some negative effects from making larger and larger single processes with more and more running goroutines.*
For tsdb_max_query_parallelism (formerly max_query_parallelism) and split_queries_by_interval, we run Loki with tiers that are tied to ingestion rate. The more data a tenant ingests, the more parallelism they get for querying. This is actually better for both smaller and larger tenants, as over-parallelizing does have a penalty, and if you over-parallelize a small amount of data, you can find Loki spending more time in the mechanics of parallelizing and executing a query than actually processing data.
*Note: A few years ago I decided to configure the single binary to also run exactly the same as SSD and microservices where it parallelizes the queries exactly as those larger deployment models do. In retrospect, I think this has hurt the performance of the single binary, specifically because the defaults are too aggressive (e.g.,
max_concurrentdefaults to 10). If you are running a single binary you might actually want to try reducingmax_concurrentto something more fitting for how many cores you have (2x number of cores or less), reducingtsdb_max_query_parallelismto something smaller like 32 (default is 128) and increasingsplit_queries_by_intervalto 6h or 12h (default is 1h). I’m sorry I haven’t had much time here to test this, but I would love to know if folks find a better experience with the single binary by reducing parallelism.*
Our user tiers for these values range from small tenants to large tenants in these ranges:
tsdb_max_query_parallelism128 → 2048split_queries_by_interval1h → 15m
Expectations for query performance
Different types of queries will have different performance characteristics. Perhaps unsurprisingly, the more complicated the query is, the slower it will execute. The fastest queries Loki will execute are filter queries like:
{namespace=”loki-ops”,container=”querier”} |= “metrics.go” |= “org_id=233432”
And simple metric queries like:
sum(count_over_time({namespace=”loki-ops”,container=”querier”} |= “metrics.go” |= “org_id=233432”[$__auto]))
sum(rate({namespace=”loki-ops”,container=”querier”} |= “metrics.go” |= “org_id=233432”[$__auto]))
*Note: Regular expressions can really do a number on the CPU consumption of queries. Almost nothing will use as much CPU as complex regular expressions either in the
|~regex filter matcher of theregexpparser, or in=~regular expression matchers after a parser. There are many cases where regular expressions are necessary, but you should avoid them if you can, and always go with the pattern parser instead of theregexpparser.*
These queries should execute in the range of 100 MB/s - 400 MB/s throughput at each subquery. I mentioned on the high end we use a tsdb_max_query_parallelism value of 2,048, so let’s do some quick napkin math:
100 MB/s 2048 parallel queries =~ 200 GB/s
400 MB/s 2048 parallel queries =~ 800 GB/s
Also worth noting in this napkin math exercise: To execute a single query we would need a minimum of 256 queriers (2048 (tsdb_max_query_parallelism) / 8 (max_concurrent)). And this is just to fully execute a single query in parallel. In reality, there are often multiple simultaneous users executing queries. In huge clusters with hundreds of active users, we may autoscale to more than 1,000 queriers to ensure there is enough capacity for everyone.
As you add complexity to the query, it will execute more slowly, but there are other factors that affect query performance, such as:
- The number of streams the query matches
- The size of your chunks
- Whether the query is shardable
- The speed of your object storage
That’s a lot of potential bottlenecks, so next we’ll dig into how you can help narrow down what might be causing the slowness.
How to troubleshoot performance issues
Still not getting the performance you want, even with all the best practices I’ve discussed so far? The tool we use most to troubleshoot Loki query performance is … another Loki.
In any reasonable size setup you’ll want to make sure your Loki logs are captured in another Loki instance (You can even use a free Grafana Cloud account for this). Of course, you can have Loki ingest its own logs, but unless you’re using very small instances, I wouldn’t recommend it, as you won’t be able to troubleshoot an outage of Loki itself.
Every query and subquery executed by Loki emits a log line we call “metrics.go.” This line contains a bounty of statistics from the executed query. Every subquery will emit this line in the queriers (or the read pods with component=”querier” in SSD mode), and every query will have a single summary “metrics.go” line emitted by the query-frontend (or the read pods with component=”frontend” in SSD mode).
Query-frontend “metrics.go”
{container=”query-frontend”} |= “metrics.go”
{container=”read”} |= “component=frontend” |= “metrics.go”
You can use the query-frontend metrics.go lines to understand a query’s overall performance. Here are the most useful stats:
- total_bytes: how many total bytes the query processed
- duration: how long the query took to execute
- throughput: total_bytes/duration
- total_lines: how many total lines the query processed
- length: how much time the query was executed over
- post_filter_lines: how many lines matched the filters in the query
- cache_chunk_req: total number of chunks fetched for the query (the cache will be asked for every chunk so this is equivalent to the total chunks requested)
- splits: how many pieces the query was split into based on time and
split_queries_by_interval - shards: how many shards the query was split into
Look for queries that are taking longer than you’d like and see how much data they are querying, how many chunks they requested, and how much parallelism the query had (i.e., how many splits and shards). I usually start with something like this, which will return all the queries that took longer than 20 seconds with a throughput less than 50 GB/s:
{container=”query-frontend”} |= “metrics.go” | logfmt | duration > 20s and throughput < 50GB
This would reduce the results to only queries longer than 20 seconds that were processed at less than 50 GB/s. From here I often take the traceID from the query and then search the “metrics.go” line in the queriers to look at how all the subqueries were processed (example query coming up in a bit).
There is one thing you can glean quickly from the frontend logs: If the shard count is 0 or 1, this means the query was not sharded. That’s because not every query type in Loki is shardable (e.g., quantile_over_time is not shardable). Sharding actually breaks up the streams in a query and executes them in parallel on separate queriers, and some operations can’t produce an accurate result this way because they need all the logs in the same place at the same time to do something like calculate the quantile.
We are actively working to improve this. For example, we are currently adding functionality to use probabilistic data structures as an option where you don’t need 100% accuracy but you do need a close and fast result.
Some additional notes about the stats in this line related to the query-frontend: queue_time, chunk_refs_fetch_time, store_chunks_download_time, really any of the stats that end with **_time** can be confusing in the frontend logs. These stats will show the accumulated values for all the subqueries, and because Loki does lots of this work in parallel, it’s possible for values here to show minutes or hours here even though the total query duration was only seconds.
My best/worst analogy here is this: Imagine 1,000 porta potties side by side at a huge concert with a line of people waiting at each. If everyone took 30 seconds in the bathroom the total time it takes for one complete cycle of 1,000 people would be 30 seconds (this is the query duration). But if you added up the time each person experienced, the total time would be 1000*30=8.3 hours (this would be queue_time as reported by the query-frontend).
Splits and shards count independently of each other; every split by time is counted and added to splits, and every shard is counted and added to shards. Knowing exactly how many subqueries a query processed therefore requires a little deduction, because sharding happens after splitting, if the shard count is greater than one, this will be the number of subqueries executed. If shards are equal to zero or one, this means the query did not shard and the subquery count will be the number of “splits.”
Querier “metrics.go”
{container=”querier”} |= “metrics.go”
{container=”read”} |= “component=querier” |= “metrics.go”
The “metrics.go” line output by the queriers contains the same information as the frontend but is often more helpful in understanding and troubleshooting query performance. This is largely because it can tell you how the querier spent its time executing the subquery.
This can help to understand what is taking all the time during query execution, and it will largely fall into these four buckets:
- Waiting in the queue to be processed:
queue_time - Getting chunk information from the index:
chunk_refs_fetch_time - Getting chunks from cache/storage:
store_chunks_download_time - Executing the query
Here is a query which can break down these stats to make it easier to see how Loki is spending its time on subquery execution
{container=”querier”}
|= "metrics.go"
# |= "traceID=e3574441507879932799daf0f160102a" # search for all the subqueries from a specific query
| logfmt
# | duration > 5s # optionally you can filter queries here
| query_type="metric" or query_type="filter" or query_type="limited"
# Note: You can't use a newly created label in the same label_format as it was created, so we use a few steps to create our labels
| label_format
duration_s=`{{.duration | duration}}`,
queue_time_s=`{{.queue_time | duration}}`,
chunk_refs_s=`{{.chunk_refs_fetch_time | duration}}`,
chunk_total_s=`{{.store_chunks_download_time | duration}}`
| label_format total_time_s=`{{addf .queue_time_s .duration_s}}` # Queue time is in addition to query execution time
| label_format
queue_pct=`{{mulf (divf .queue_time_s .total_time_s) 100 }}`,
index_pct=`{{mulf (divf (.chunk_refs_fetch_time | duration) .total_time_s) 100 }}`,
chunks_pct=`{{mulf (divf .chunk_total_s .total_time_s) 100}}`,
execution_pct=`{{mulf (divf (subf .duration_s .chunk_refs_s .chunk_total_s) .total_time_s) 100}}`
| line_format `| total_time {{printf "%3.0f" (.total_time_s | float64)}}s | queued {{printf "%3.0f" (.queue_pct | float64)}}% | execution {{printf "%3.0f" (.execution_pct | float64)}}% | index {{printf "%3.0f" (.index_pct | float64)}}% | store {{printf "%3.0f" (.chunks_pct | float64)}}% |`
Generally, you want to see as much time as possible spent in execution. If this is true for your cluster and the query performance is not what you want it to be, this may be for a few reasons:
- Your queries do a lot of CPU-expensive operations like regular expression processing. Perhaps you are hitting CPU limits? See if your queries can be modified to reduce or remove regular expressions or give your queriers access to more CPU.
- Your queries have a LOT of small log lines. Typically Loki is bound on moving data around and not iterating on log lines, but it does happen with huge volumes of tiny lines where execution speed is bound to how fast Loki can iterate the lines themselves. Interestingly, this becomes somewhat of a CPU clock frequency bottleneck. To make things faster you need a faster CPU, or you can try more parallelism.
If your time is spent in queued you don’t have enough queriers running, if you can’t run more queriers then you probably can’t do much here, you could reduce parallelism settings however, as having a high amount of parallelism won’t help you if you don’t have hardware to execute it.
If your time is spent on the index, you likely need more index-gateways (or backend pods in SSD mode). Or make sure they have enough CPU, since they can use quite a bit of CPU for queries that match a lot of streams.
If your time is spent on storage, even cloud object storage may still be the long tent pole on queries. You can check the average chunk size by dividing total_bytes by cache_chunk_req. This would represent the average uncompressed bytes per chunk. Being an average, it’s not an exhaustive way to spot chunk size problems, but it can clue you in to an obvious problem if the average value is only a few hundred bytes or kilobytes and not megabytes (which would be best). If your chunks are too small, revisit your labels and see if you are over splitting your data, Part 2 of this series has lots of information about labels.
Summary
I think for most folks, poor query performance usually stems from a few common issues:
- Incorrect
max_concurrentand parallelism settings (tsdb_max_query_parallelismandsplit_queries_by_interval). - Not having enough queriers running to take full advantage of the parallelism they have configured.
- Overzealous use of labels, leading to too many tiny chunks.
- Object storage that isn’t able to provide chunks as fast as Loki can query them.
Hopefully this guide was helpful in demystifying how Loki executes queries and will help most folks to tune in some better query performance. Come back next week for another installment in “The concise guide to Loki”!
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!

