
The concise guide to Grafana Loki: Everything you need to know about labels
Welcome to Part 2 of “The concise guide to Loki,” a multi-part series where I cover some of the most important topics around our favorite logging database: Grafana Loki. As I reflect on the fifth anniversary of Loki, it felt like a good opportunity to summarize some of the important parts of how it works, how it’s built, how to run it, etc. And as the name of the series suggests, I’m doing it as concisely as I can.
In last week’s blog, which served as a concise guide to the log aggregation tool, I briefly described Loki’s index as “Prometheus-style labels that define what we call a log stream.” But what does that mean exactly? In this week’s blog, let’s dig deeper into Loki’s labels, how they work, what’s changed over the years, and what you need to know to use Loki’s index for maximum efficacy.
How labels work in Grafana Loki
Labels are both the keyspace on which Loki shards incoming data, as well as the index used for finding your logs at query time. Using them correctly is critical to success with the application, so it was an obvious choice for me to dedicate a post in this series to how they work and the best practices surrounding labels.
In concept, labels are simple; they’re a set of arbitrary key-value pairs you assign to your logs at ingestion. In practice, however, they can create some issues for newer users. Folks may have a preconceived notion of how they think Loki’s index should work based on experiences with other databases, or perhaps they attempt to use the same amount of cardinality in their Loki labels as they do with their metrics in Prometheus.
Perhaps then a good starting point is an example/demonstration of how labels work in Loki. Imagine the source of your log data — an application or system generating logs. Years ago that may have been one machine, and it may have had a name like “Rook” and been a Unix system running Solaris on SPARC hardware. It may, in fact, haunt your dreams to this day.
Let’s send the logs from this server to Loki. To do so, we will assign a very basic single label:
{host=”rook”}
Loki will receive that data and start building chunks for that stream.
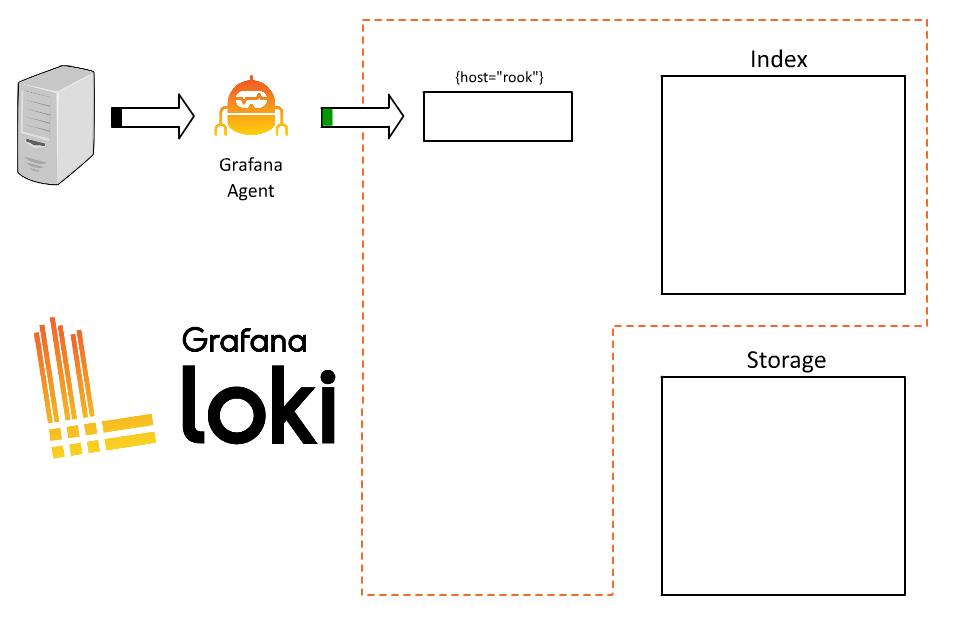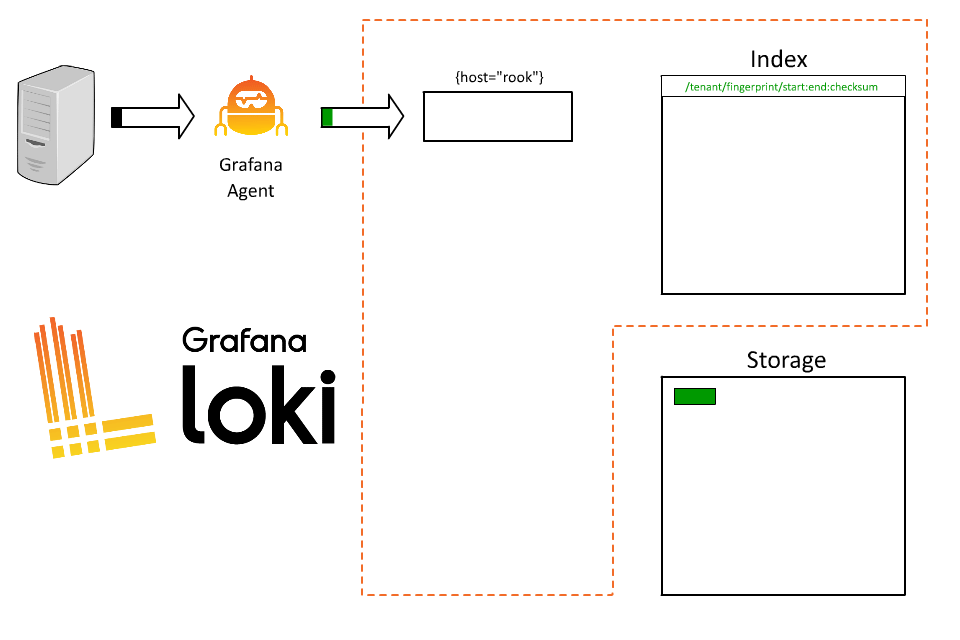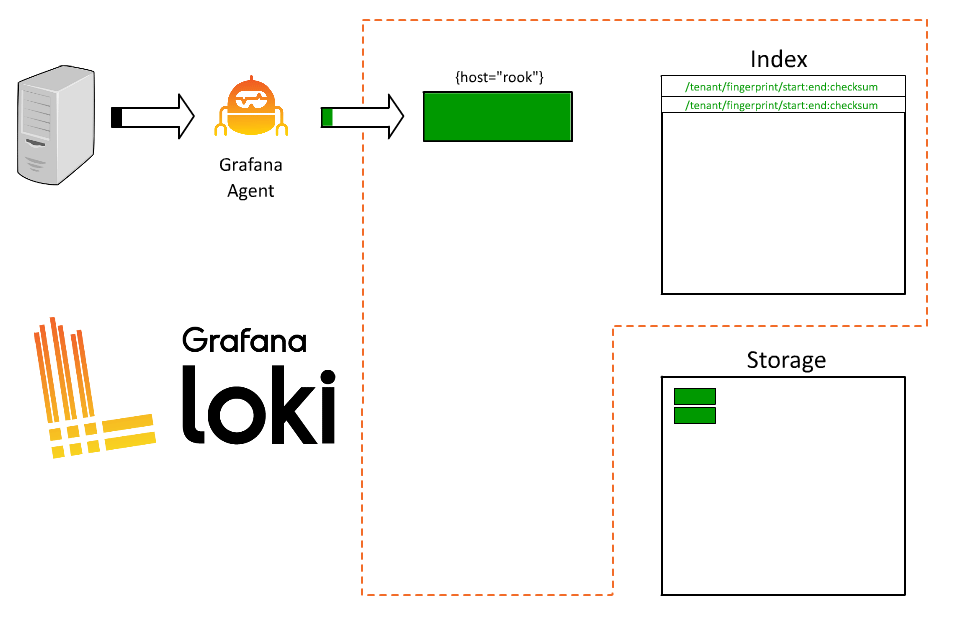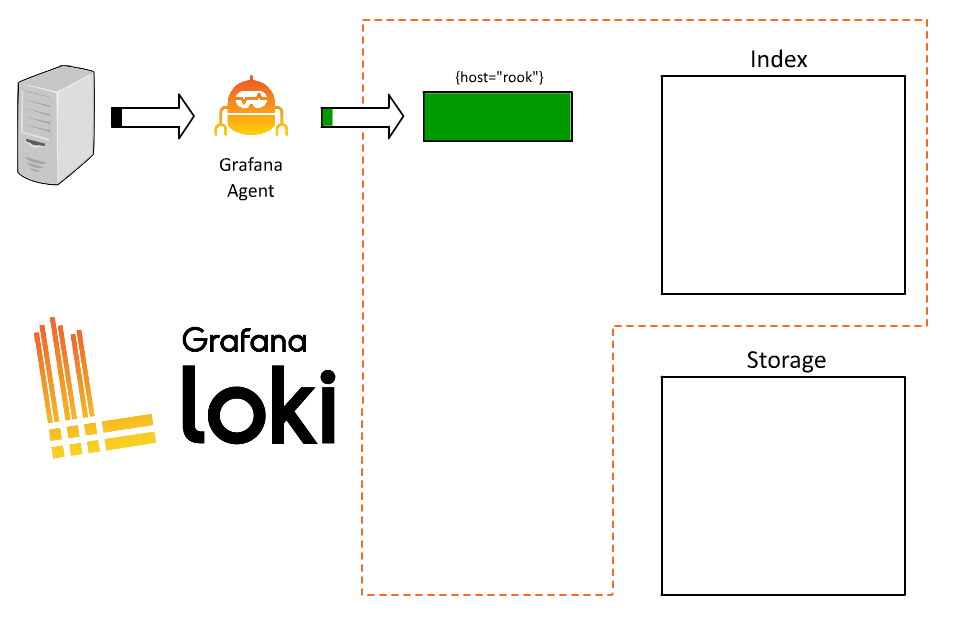
There’s a problem here though. Rook runs a bunch of applications and every query we run has to query all of them. As a result, users are frustrated trying to understand which logs are from which system and queries are slow.
Let’s use labels to improve the situation.
{host=”rook”, app=”webserver”}
{host=”rook”, app=”ftp”}
{host=”rook”, app=”middleware”}
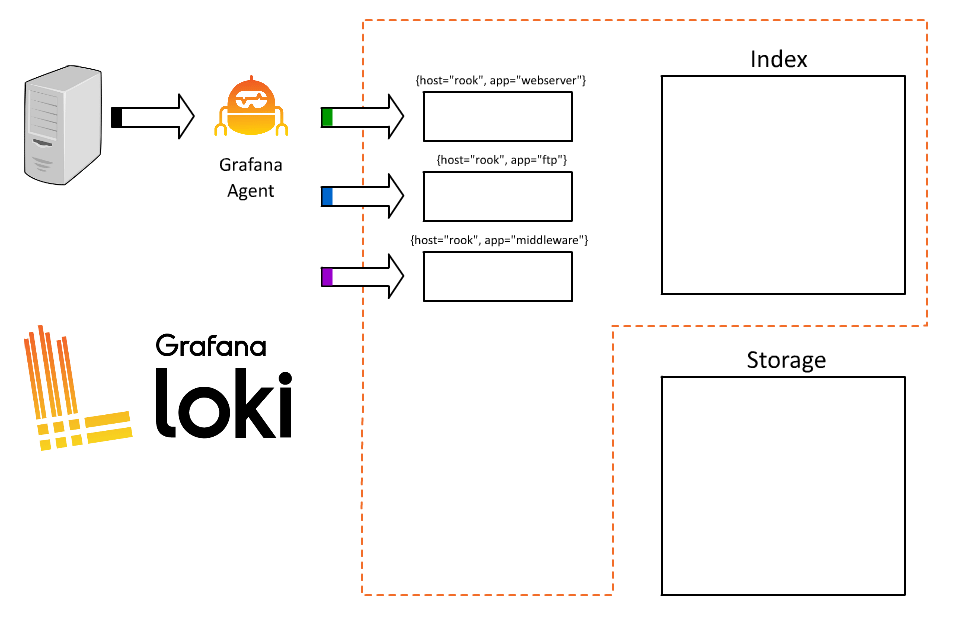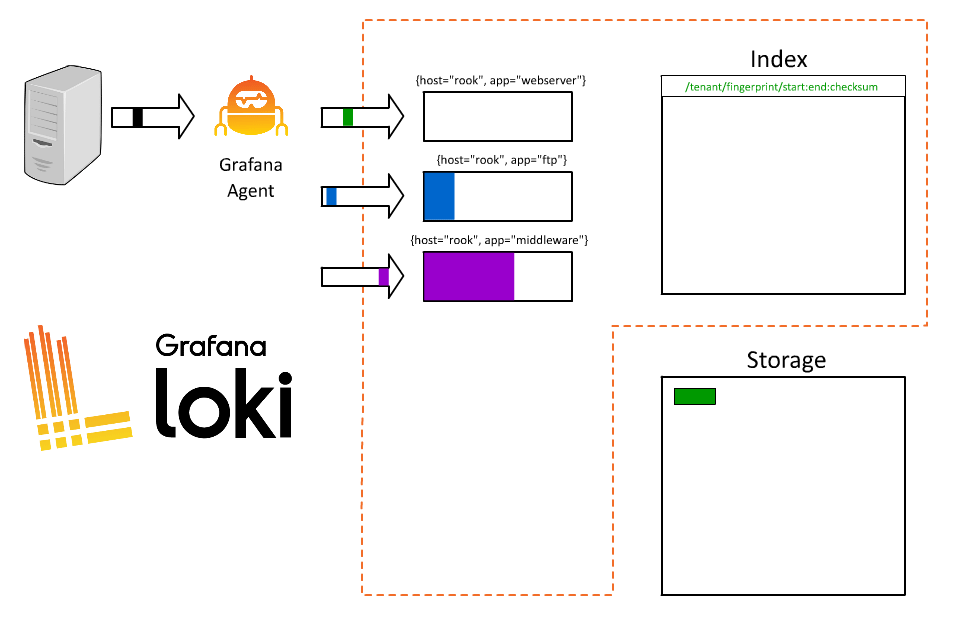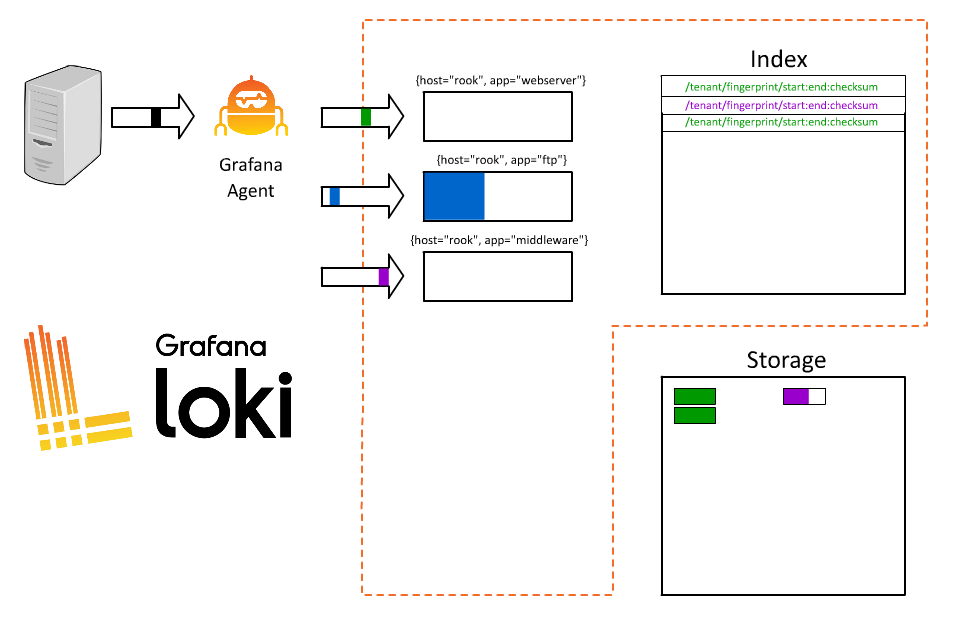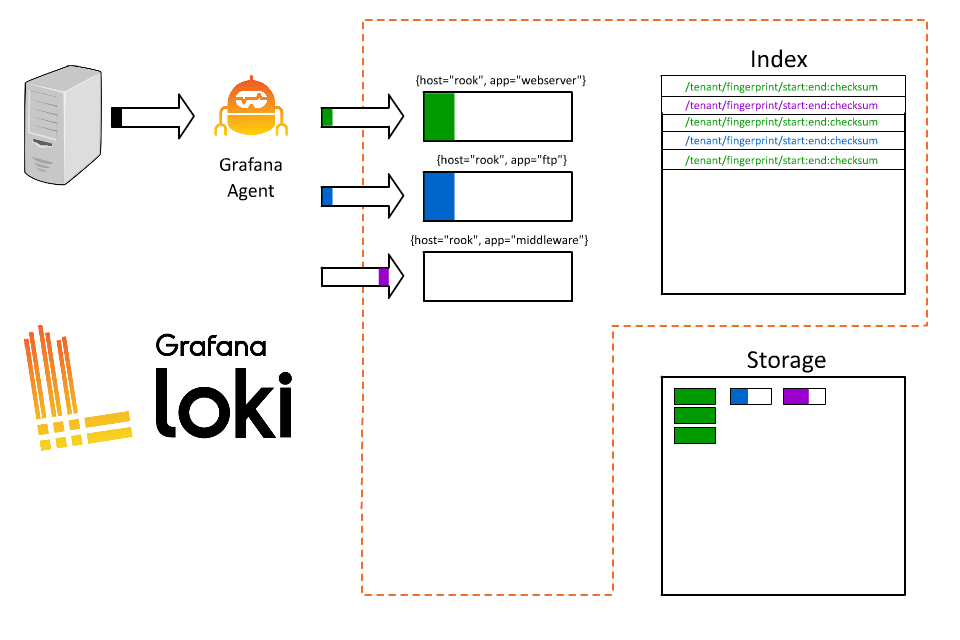
OK, great. Now everyone can query and they only have to fetch the logs for their specific application. But why stop here? I’ve played this game before; the more I put in the index the better, right? Our systems process a lot of orders, so why not index order ID too?
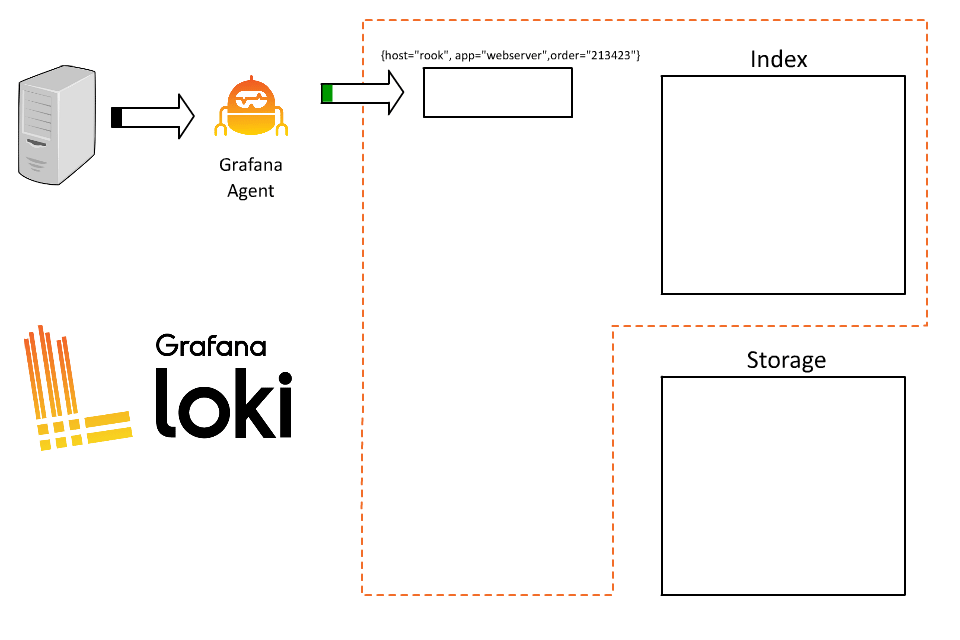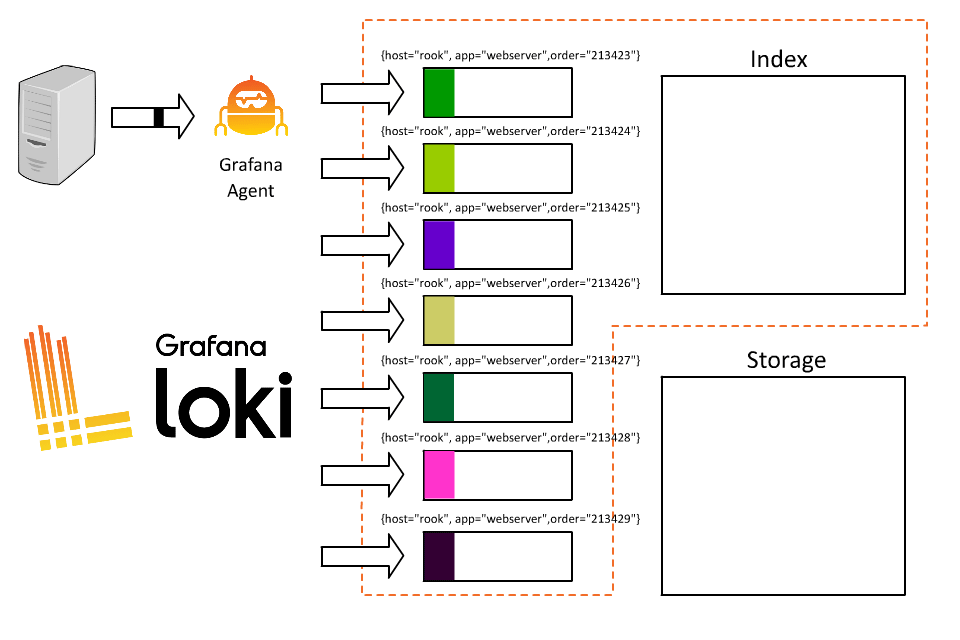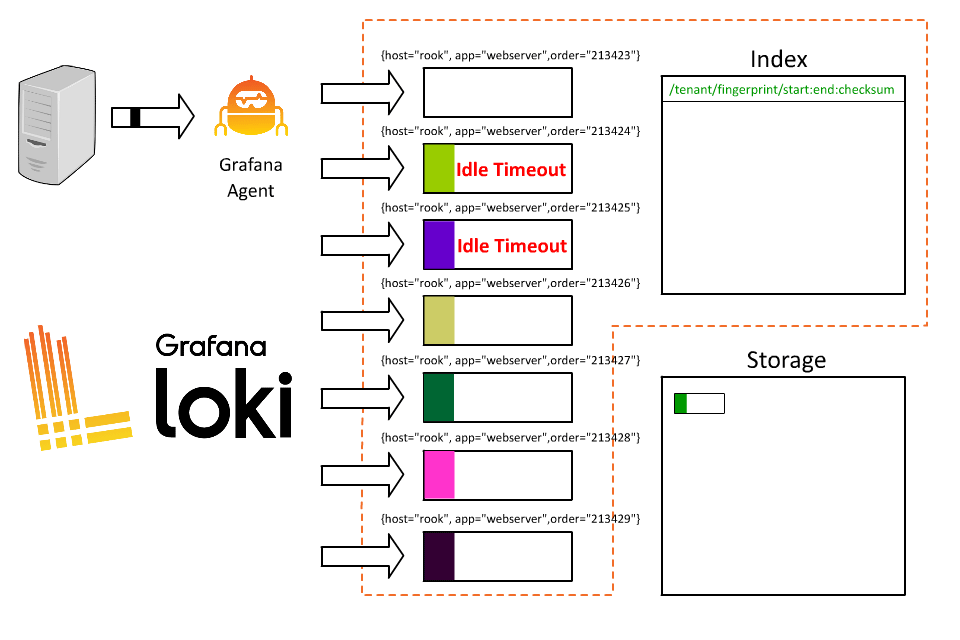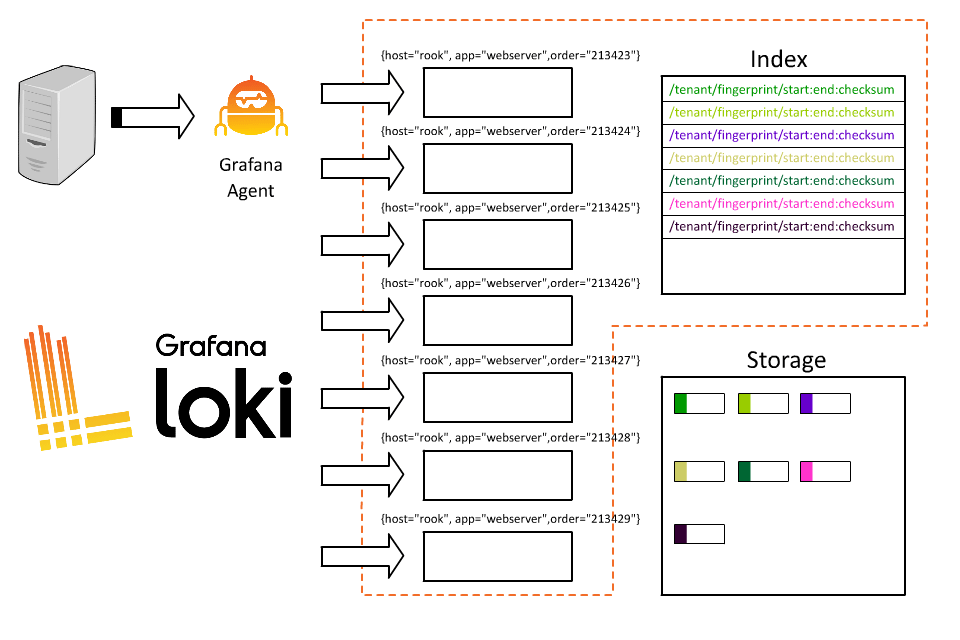
Hrm, I think I broke it.
So what went wrong? By introducing order ID as a label, we took all those logs coming from Rook and fragmented them into thousands of short-lived streams. As each stream then writes to a separate file, Loki will then create thousands of tiny files, each of which requires an entry (and therefore space) in the index.
Loki was not designed or built to support high cardinality label values. In fact, it was built for exactly the opposite. It was built for very long-lived streams and very low cardinality in the labels. In Loki, the fewer labels you use, the better.
Here are a few qualities of good labels:
- They describe infrastructure. This could include regions, clusters, servers, applications, namespaces, or environments.
- They’re long-lived. Label values should generate logs perpetually, or at least for several hours.
- They’re intuitive for querying.
That last bullet is quite important. Labels are the only thing that controls how much data is queried, so it’s important to use labels that can be easily learned and are intuitive for use at query time.
What’s changed?
Fundamentally, Loki still uses labels the same way it did five years ago, and the advice on using them is largely unchanged. However, we have made improvements in several areas where users ran into friction, so let’s take a look at those.
Too much data into a single stream
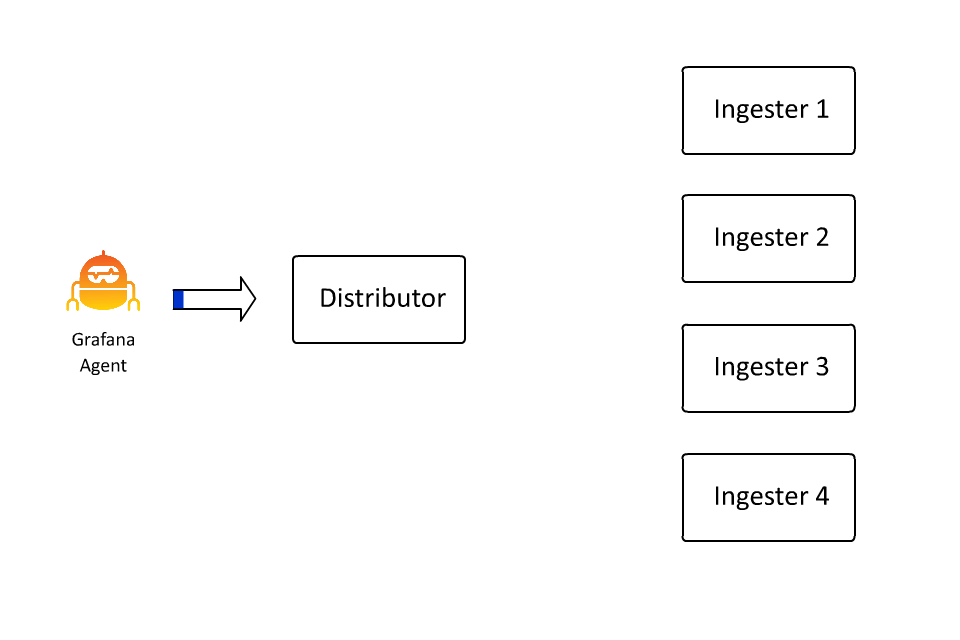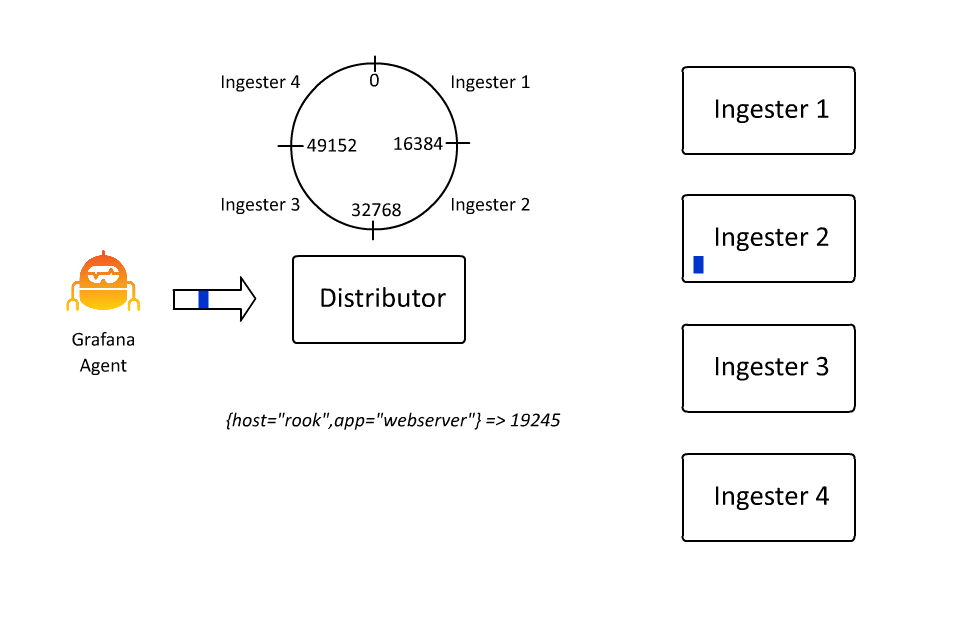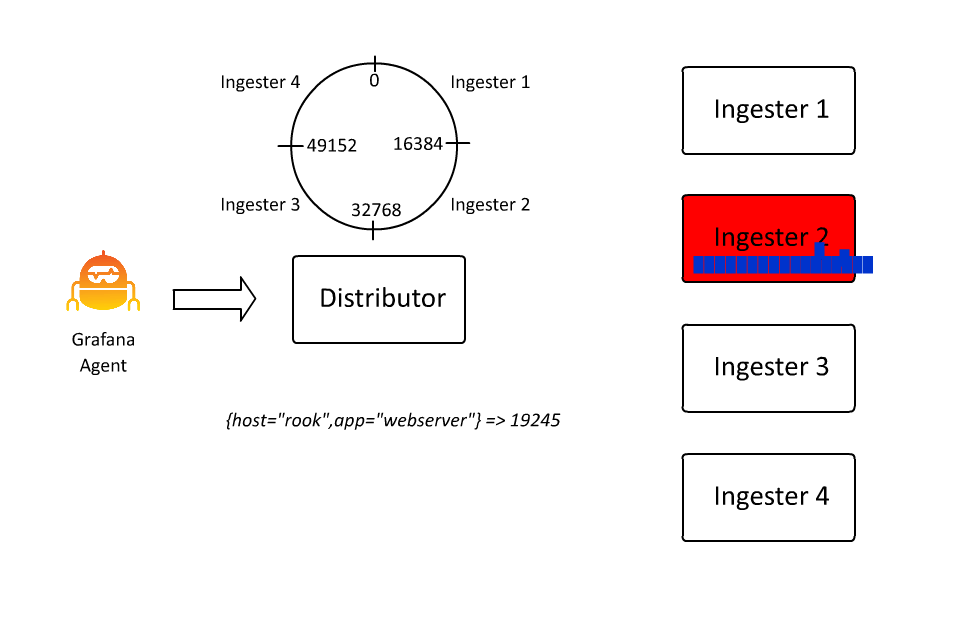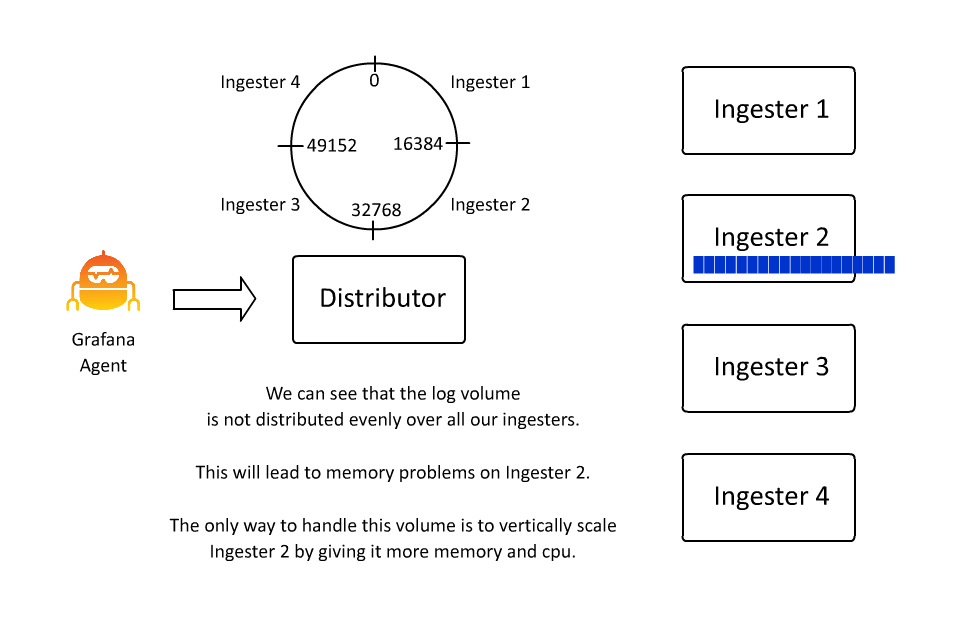
The set of key-value pairs that define a stream also define the keyspace over which data is partitioned, or sharded, within Loki. The set of key-value pairs is hashed into a number, and that number determines a spot on a hash ring. And that spot determines which ingester receives the data for that stream. I spent about 100 hours in the last few days learning how to create animations because in this case I do think “a picture is worth a thousand words” (even if I wrote the words anyway):
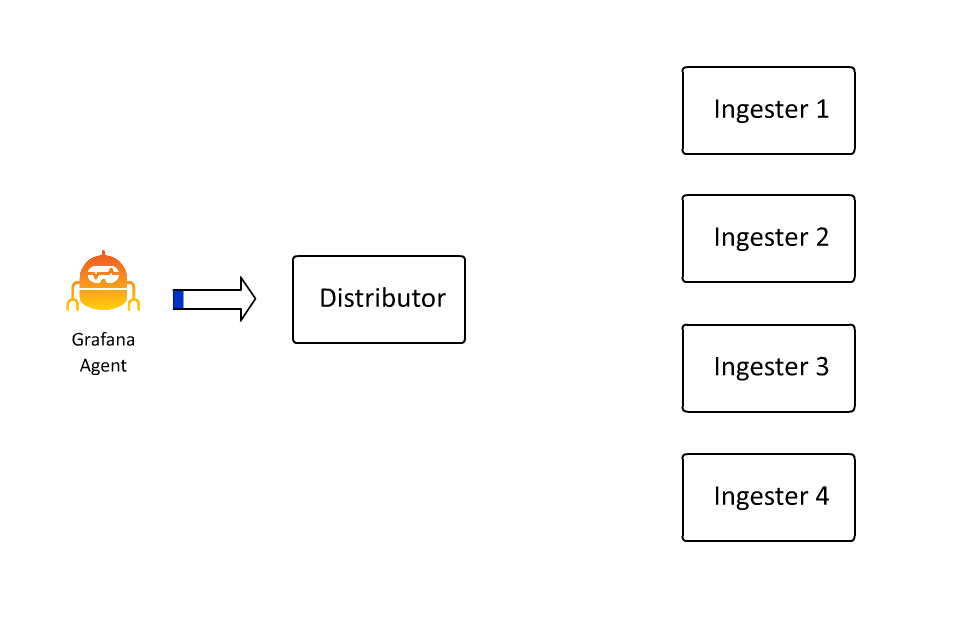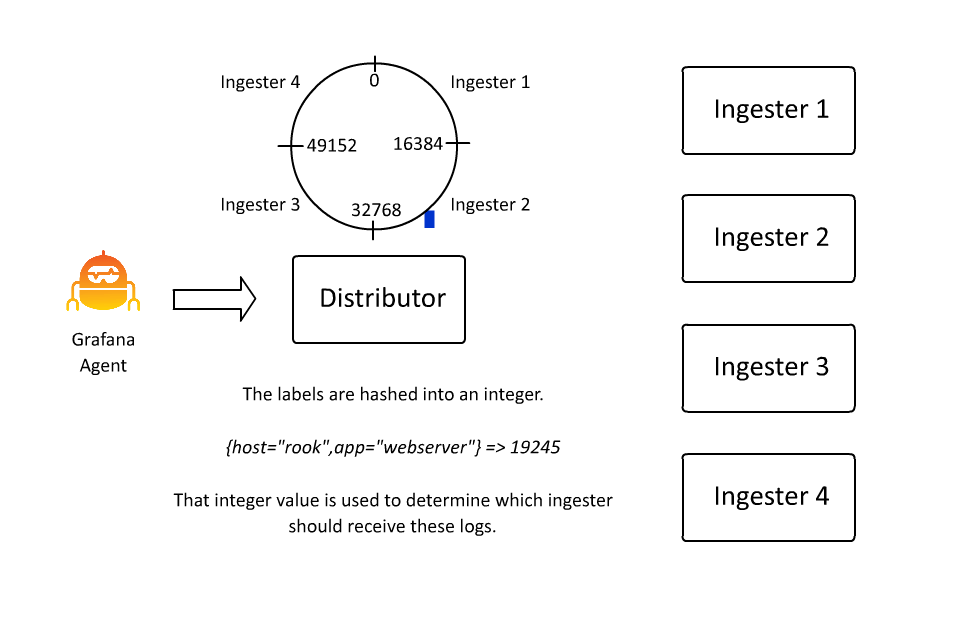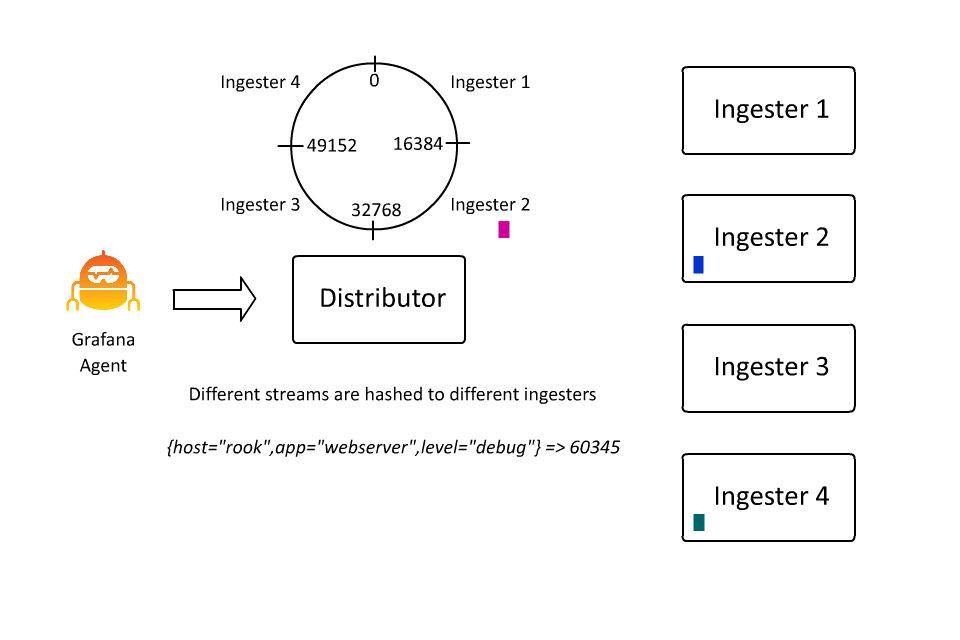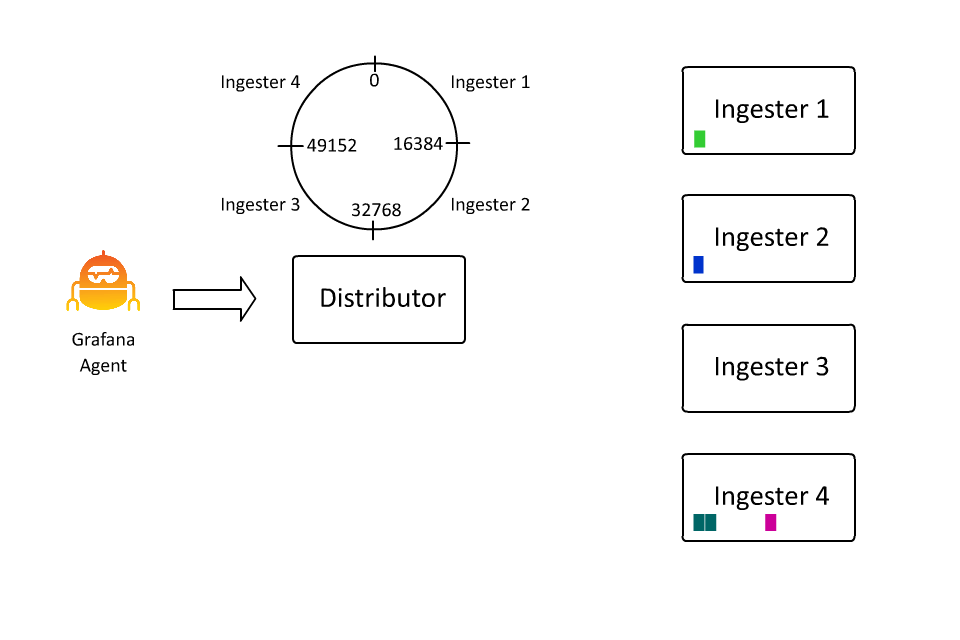
This allows Loki to continue to accept more and more data by inserting more and more machines, as ingesters are only responsible for a subset of all the streams. However, there is a problem here: What if a stream gets really big?
This is a scenario most commonly seen when pulling logs from something like Pub/Sub or Kafka or other systems that can aggregate a lot of logs. Because the key in Loki’s keyspace is a stream, if a stream’s volume grows unbounded, it requires the ingester who owns that stream to also scale vertically with more CPU/RAM to handle it.
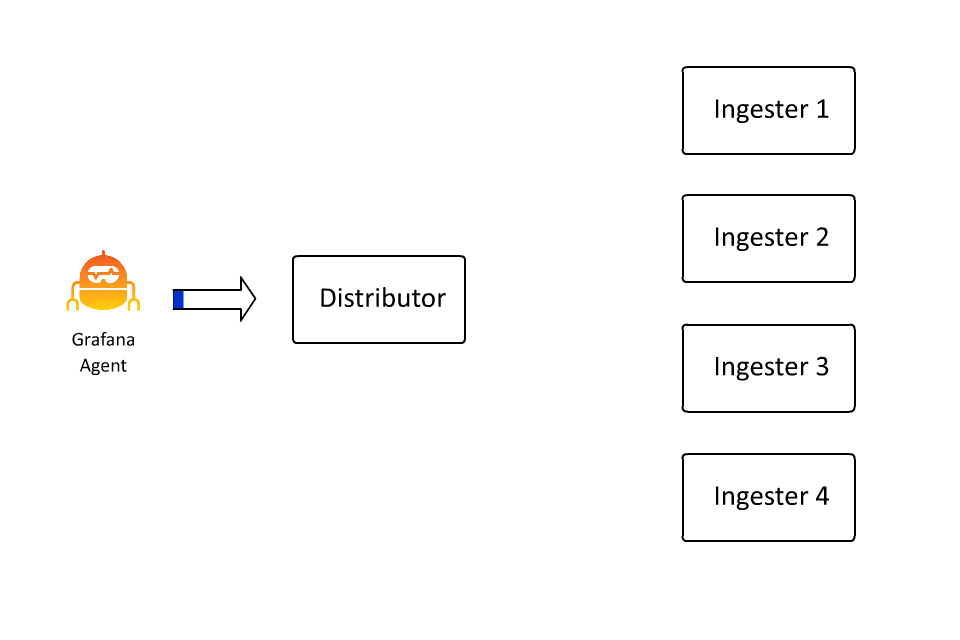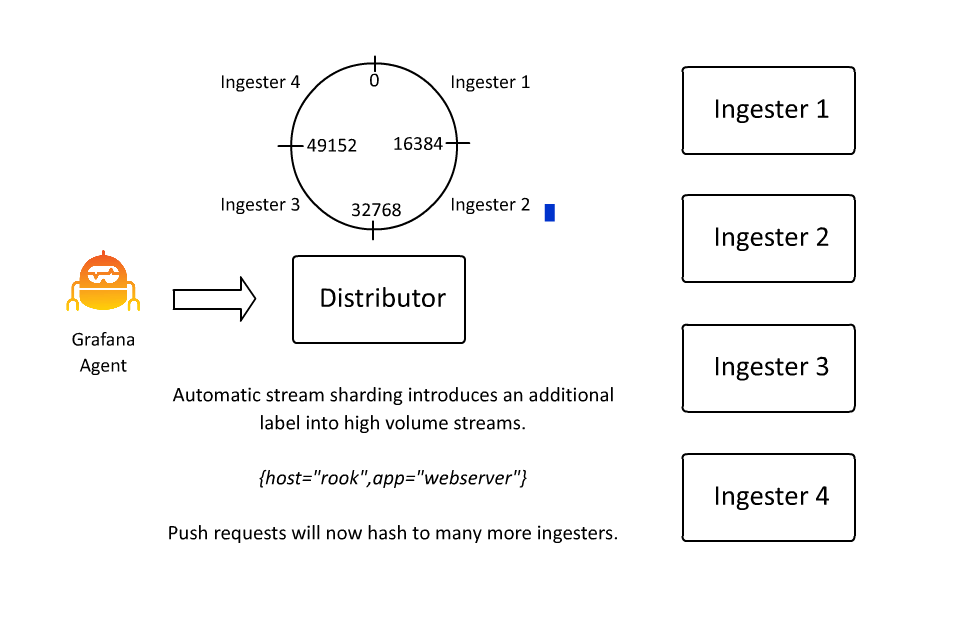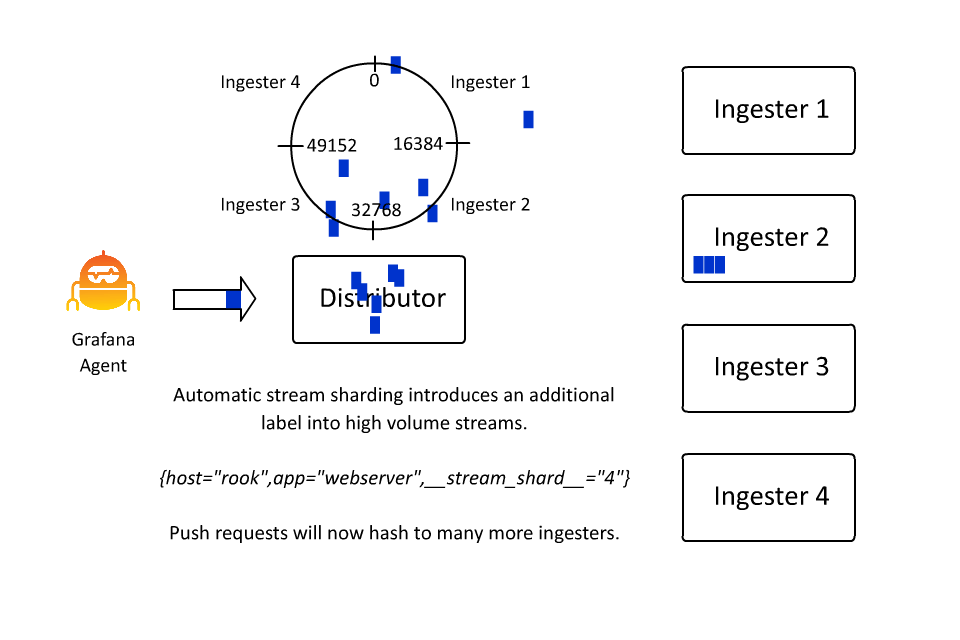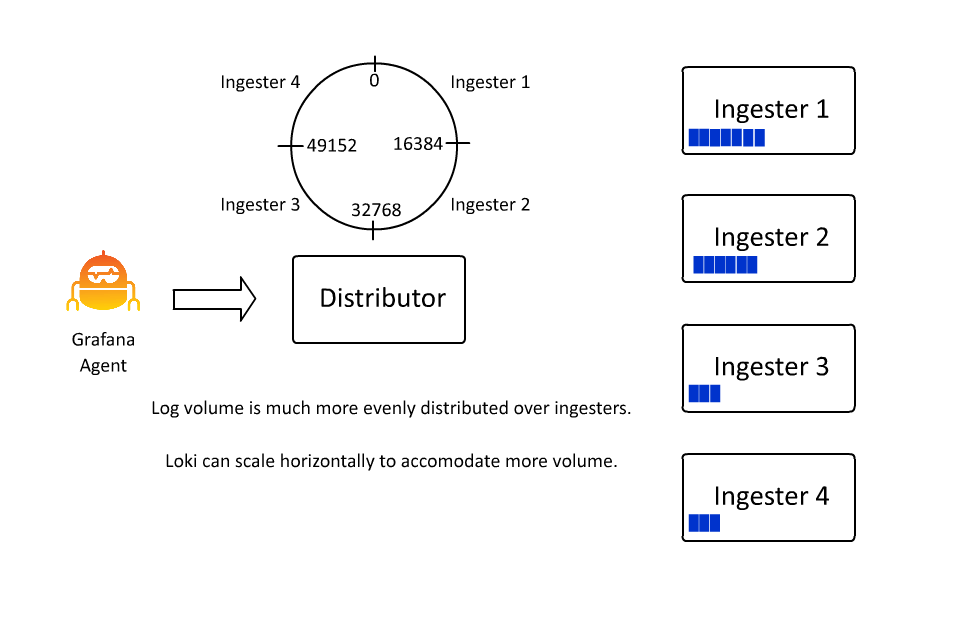
This isn’t very desirable from an operations standpoint, so about a year ago we introduced automatic stream sharding. This code sees streams that exceed a desired max stream rate and introduces an additional label __stream_shard__ to split that stream into multiple streams automatically.
As a stream grows in volume, the __stream_shard__ label is automatically applied with more and more values to evenly distribute the high volume stream over more streams to prevent overwhelming a single ingester.
What about the pod label?
A pod is a Kubernetes concept defined as “the smallest deployable unit of compute.” For some Kubernetes workloads, pods get ephemeral names. This can create an interesting dilemma for Loki: the pod label may be required to disambiguate logs in an important way at query time. However, pods can be short-lived due to autoscaling or work scheduling, leading to high amounts of cardinality and subsequent unhappiness in Loki.
Historically, we would solve this in one of two ways. We’d index the pod label if the overall cardinality could be kept to less than, say, 100,000 streams in an hour. Or, if it was higher than this, we’d use the pack stage in Promtail to embed the cardinality in the log line. Neither of these are great solutions.
Fortunately, Loki now has a better solution for this situation: structured metadata (Experimental in 2.9; will be GA in 3.0). Structured metadata is a place where you can store key-value pairs alongside the log line and not in the index. This lets us keep long-lived streams with low cardinality labels, while also having a place to store high cardinality data, which is necessary for filtering and grouping at query time.
I want to search all my logs for a unique ID
One thing we’ve noticed as a consistent behavior in our Loki users: they run a lot of “needle in a haystack” queries. Specifically, they’re looking for something like an order ID or a UID over large periods of time and very generic label matchers. Such a query may look like: {env=”prod”} |= “603e0dcf-9b24-4c37-8f0d-6d8ebe5c5c8a”
These types of queries can be a lot of work for Loki to execute when {env=”prod”} matches terabytes or tens of terabytes of data. Loki’s parallelism allows it to process these queries at pretty tremendous speeds, around a half a terabyte a second! However, I’ve learned the data volume can be so big, or the time range so long, that even this isn’t fast enough.
So realizing that this use case is common enough, the team decided to expand Loki to optimize this type of search. One might be tempted to try putting these IDs in a label and therefore in Loki’s index, right? This certainly would allow you to more quickly find the logs containing a UID. However, as we demonstrated above, this has some bad side effects, one of which is creating a much much larger index. In fact, it essentially turns Loki’s index into an inverted index, which has many known scaling challenges and is contrary to Loki’s design.
Instead we have settled on a design using Bloom filters. Bloom filters are space-efficient probabilistic data structures that are extremely well suited to this application. Instead of building an inverted index that tells Loki exactly where it does have to look, Bloom filters can tell Loki where it does not have to look, in a much more space-efficient and scalable way. I suspect we will have dedicated posts around Bloom filters in the future, or you can watch the great intro Grafana Labs Software Engineer Vlad Diachenko gave at ObservabilityCON:
Bloom filters are being built and tested now and will be available in Loki 3.0, which is coming soon.
What you need to know about labels (TL;DR)
I know I used the word “concise” to describe these blog posts …

Haha, I’m trying. But now that we’ve gone over how they work and how they’ve changed, I want to address common questions about using labels in Loki. Similar to what I did in a previous post in the series, I’ll summarize some best practices through examples below.
How can I query all my logs for a given trace ID?
Never put a high cardinality field in a label value. Loki was not built for this and it will hate you. Keep this data in the log lines and use filter expressions in your search. Use label matchers to narrow the search space as much as you can. However, in Loki 3.0 this type of search will be substantially improved with the assistance of Bloom filters.
{cluster="ops-cluster-1",namespace="loki-dev"} |= “traceID=2612c3ff044b7d02”
But what if the label is low cardinality? What if you extracted the log level into a label, and we only have five values for our logging level?
Over the years level has been somewhat of a contentious label, as it can cause small streams to be split even smaller. However, the utility of the level label at query time is quite high, and it also aids in providing a better experience in Explore’s log volume histogram.
So go for it; you can extract the log line level and use it as a label.
The only other time you should extract data from a log line is when:
- It’s low cardinality, maybe tens of values
- The values are long lived (e.g., the first level of an HTTP path: /load, /save, /update)
- Your users will use these labels in their queries to improve query performance.
If even one of these bullets is not true, then don’t do it! Leave that data in the log line and use filter expressions to search it.
But if I want to write a metric query and I want to add a sum by (path), how can I do this if path isn’t a label?
And why, when I send logs from my Lambda or function, do I get “out of order” errors unless I include a request ID or invocation ID?
I took these two questions from the previous guide, and combined them because in both cases Loki has improved to render these questions obsolete.
Loki 2.0 introduced a query language capable of extracting any content at query time into labels, and Loki 2.4 allowed for receiving out of order logs.
Summary
If you take nothing else away from this blog, let it be this: use the fewest labels possible. While Loki and Prometheus share the concept of labels, the application is quite different. If you’re properly using labels in Loki, you shouldn’t have any cardinality problems.
So, to reiterate, good labels have these qualities:
- Describe infrastructure: regions, clusters, servers, applications, namespaces, environments
- Have long lived values. Label values should generate logs perpetually, or at least for several hours
- Are intuitive for querying
Only extract content from log lines if you have a query pattern that will directly benefit from a small number of additional label-value pairs, and the labels will meet these criteria:
- It’s low cardinality, maybe tens or hundreds of values
- As a general rule you should try to keep any single tenant in Loki to less than 100,000 active streams, and less than a million streams in a 24-hour period. These values are for HUGE tenants, sending more than 10 TB a day. If your tenant is 10x smaller, you should probably have at least 10x less labels.
- The values are long lived (e.g., the first level of an HTTP path: /load, /save, /update)
- Do not extract ephemeral values like a trace ID or an order ID into a label, the values should be static, not dynamic.
- Your users will use these labels in their queries to improve query performance.
- Don’t increase the size of the index and fragment your log streams if nobody is actually using these labels. If nobody uses them, you’ve made things worse.
Thanks for joining me on this multi-blog-post journey, and I hope the series helps you on your own Loki journey. Come back next week for the concise guide on tuning Loki query performance.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!

