
Reproducing and testing distributed system failures with xk6-disruptor
Distributed systems, such as modern microservices-based applications, are highly scalable, but also highly complex. Dependencies and unexpected interactions between services are a common cause of incidents, and these incidents are also notoriously hard to test for.
xk6-disruptor — an extension that adds fault injection capabilities to Grafana k6, the open source reliability and load testing tool — can help overcome these challenges.
In this post, we’ll explore a fictitious but relatable story of an engineering team recovering from an incident caused by a service dependency not behaving as expected. We’ll walk through how the team decided to take measures and, using xk6-disruptor, improve their testing strategies so they can catch these types of issues before they happen again.
The application
Let’s put ourselves in the shoes of an engineering team that works on 🍕 QuickPizza, a web application run by a VC-backed startup that goes by the same name. The goal of QuickPizza is to help end users deal with the often unbearable task of choosing which pizza to order. According to their CEO, they expect to disrupt the food market “by taking the burden of this choice from our customer, and enabling them to focus instead on what’s important: getting things done.”

The QuickPizza application architecture consists of multiple services, running on Kubernetes, that talk to each other using HTTP:

For our example here, two of these services are especially important: Recommendations and Catalog.
As their names suggest, the Recommendations service is a sophisticated recommendation engine that suggests pizza combinations for users, while the Catalog service stores the different ingredients, like doughs and toppings, that can be used to make pizzas. The Recommendations service relies on and communicates with Catalog to retrieve the list of ingredients.
One team maintains the Recommendations service, and a separate team maintains the Catalog service.
The incident
During the night, a link to the QuickPizza web page, which serves the application, was shared on a link aggregator by a happy user of the service. The post gained some traction, and a bunch of users started to ask for pizza recommendations, which increased the load on both the Recommendations and Catalog services.
The maintainers of the Catalog service had accounted for this and the service was able to handle the load without any catastrophic failure. However, the increased load did affect the response time of the Catalog service, causing some user requests to take more time to complete.
This increase in latency was not something that the maintainers of the Recommendations service had anticipated, and it caused some of the requests made to Catalog to time out. This failure was handled by returning an HTTP 500 response, which eventually made its way to the frontend. The maintainers then received an alert in the middle of the night, due to an increase in non-200 responses from the Recommendations service.
The maintainers of the Recommendations service were able to figure out the issue, thanks to the timeout-related messages in the logs. They then deployed some temporary countermeasures, and went back to sleep. In the following days, the team would work on a more permanent solution.
The follow-up — and the value of xk6-disruptor
As an action from the post-mortem the following day, the team decided it was a good idea to cover these kinds of failures in their test suite. The specific actions and goals they decided were:
- Implement a retry and backoff mechanism for calls to other services
- Test the implemented solution before and after it is deployed
- Keep the tests for the implementation as regression tests, so the issue is not brought back accidentally
- Probe for similar situations with other dependencies
Action #1 was not particularly difficult to execute. A number of libraries have built-in functionality to enable retries and backoffs, and other libraries can be wrapped to add this functionality.
After some research, the Recommendations team chose to use xk6-disruptor for actions #2 and #3. xk6-disruptor allows teams to write tests for a service, while injecting faults into other services it depends on. These faults are highly controlled and can simulate increased latency and error codes, enabling engineers to reliably reproduce the conditions that led to an incident. Tests that use xk6-disruptor run directly on a development or staging Kubernetes cluster; this means it will capture cases that integration tests would not, such as failure propagation against multiple dependencies.
The team’s belief is that the tests they write using xk6-disruptor can later be iterated on by other developers and platform engineers for more complex use cases, such as:
- Testing how a service behaves when the dependencies of their dependencies do not behave as expected, which is harder to achieve using integration tests
- Using the hybrid testing approach to understand how the UI behaves when several services deep in the call stack do not behave as expected
- Extending the newly created tests to other services, without requiring code changes
- Writing tests that verify their SLOs, and see which SLOs they would require from their dependencies to meet their own
Reproducing the incident
Note: The commands in this section use the real QuickPizza demo application, so you can run them yourself! Check out the QuickPizza GitHub repository for more details.
The Recommendations team was able to reproduce the failure that led to the incident by first deploying the QuickPizza application into a development cluster:
k apply -k quickpizza/kubernetes/
And then writing a test that:
- Reproduced the delays that the Catalog service experienced
- At the same time, performed some requests to the Recommendations service and confirms they run successfully
The test was fully self-contained and amounted to ~50 lines of JavaScript, including inline comments:
import http from "k6/http";
import { check, sleep } from "k6";
import { ServiceDisruptor } from "k6/x/disruptor";
export const options = {
thresholds: {
// SLA for the Recommendations service: 99% of the requests should succeed.
http_req_failed: ["rate<0.01"],
},
scenarios: {
load: {
// Load scenario, where we make some requests to the recommendations service.
executor: "constant-vus",
vus: 5,
duration: "30s",
startTime: "5s",
},
disrupt: {
// Disruption scenario, runs in parallel with load scenario.
executor: "shared-iterations",
iterations: 1,
exec: "disrupt",
},
},
};
// Disrupt function.
export function disrupt() {
// Create a disruptor for the quickpizza-catalog, a dependency of the quickpizza-recommendations service.
const disruptor = new ServiceDisruptor("quickpizza-catalog", "default");
// Inject a 900ms ±150ms delay on this service for 40s.
// This will cause some requests to take over 1s, which will time out with the default settings.
disruptor.injectHTTPFaults(
{ averageDelay: "900ms", delayVariation: "150ms" },
"40s"
);
}
export default function () {
// Pizza recommendation payload.
const restrictions = {
maxCaloriesPerSlice: 700,
mustBeVegetarian: false,
excludedIngredients: ["pepperoni"],
excludedTools: ["knife"],
maxNumberOfToppings: 6,
minNumberOfToppings: 2,
};
// Perform the request to the quickpizza-recommendations service.
let res = http.post(
`http://localhost:3333/api/pizza`,
JSON.stringify(restrictions),
{
headers: {
"Content-Type": "application/json",
"X-User-ID": 23423,
},
}
);
}
By running the test, the team verified that their service was indeed timing out and returning an error code:
$> xk6-disruptor run timeout-incident.js
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: timeout-incident.js
output: -
scenarios: (100.00%) 2 scenarios, 6 max VUs, 10m30s max duration (incl. graceful stop):
* disrupt: 1 iterations shared among 1 VUs (maxDuration: 10m0s, exec: disrupt, gracefulStop: 30s)
* load: 5 looping VUs for 30s (startTime: 5s, gracefulStop: 30s)
✗ http_req_failed................: 56.75% ✓ 21 ✗ 16
[... Part of the output has been elided for readability]
running (00m40.8s), 0/6 VUs, 38 complete and 0 interrupted iterations
disrupt ✓ [======================================] 1 VUs 00m40.7s/10m0s 1/1 shared iters
load ✓ [======================================] 5 VUs 30s
ERRO[0041] thresholds on metrics 'http_req_failed' have been crossed
Something caught the attention of the Recommendations team: more than 50% of the requests failed. Given that they specified a latency of 900ms ±150ms, and that their service has a 1000ms timeout, this was surprising. Only a few requests, around 16%, should fall over 1000ms.
To better understand why this happened, the team jumped into Grafana Tempo to look at the traces generated by both a request that returned 200, and another one that failed and returned 500:

Visualizing the traces for a request to the Recommendations service revealed why the end-to-end failure rate was higher than what we would expect for a single request: The Recommendations service actually makes several requests to the Catalog service, each with its own timeout. Any one of these requests failing would cause the Recommendations service to abort and return a 500 error.
This kind of failure amplification is very common in distributed systems.
Fixing the issue
As it turns out, retry and backoff functionality was already built into the library QuickPizza used to make HTTP requests, but unfortunately turned off by default. To fix this issue, the Recommendations team only needed to enable retrying failed attempts:
diff --git a/kubernetes/kustomization.yaml b/kubernetes/kustomization.yaml
index 886cffc..02ae06b 100644
--- a/kubernetes/kustomization.yaml
+++ b/kubernetes/kustomization.yaml
@@ -24,4 +24,4 @@ configMapGenerator:
# Trust all incoming TraceIDs for demo purposes.
- QUICKPIZZA_TRUST_CLIENT_TRACEID=true
# You can change other settings by adding entries to this list:
- #- CUSTOM_ENV=CUSTOM_VALUE
+ - QUICKPIZZA_RETRIES=3
By setting QUICKPIZZA_RETRIES to 3, the HTTP library QuickPizza used will perform 3 retries with the default backoff settings.
Running the same test after the fix was deployed confirmed it was effective:
18:56:49 ~/Staging/k6-blog/posts/2023-09-04--iterating-distributed-systems-failures-xk6-disruptor $> ~/Devel/xk6-disruptor/build/k6 run timeout-incident.js
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: timeout-incident.js
output: -
scenarios: (100.00%) 2 scenarios, 6 max VUs, 10m30s max duration (incl. graceful stop):
* disrupt: 1 iterations shared among 1 VUs (maxDuration: 10m0s, exec: disrupt, gracefulStop: 30s)
* load: 5 looping VUs for 30s (startTime: 5s, gracefulStop: 30s)
✓ http_req_failed................: 0.00% ✓ 0 ✗ 19
[... Part of the output has been elided for readability]
running (00m40.7s), 0/6 VUs, 20 complete and 0 interrupted iterations
disrupt ✓ [======================================] 1 VUs 00m40.7s/10m0s 1/1 shared iters
load ✓ [======================================] 5 VUs 30s
The Recommendations team was pleased to see that, despite some requests to the Catalog service being delayed past the timeout threshold, the Recommendations service handled this failure and retries as expected.
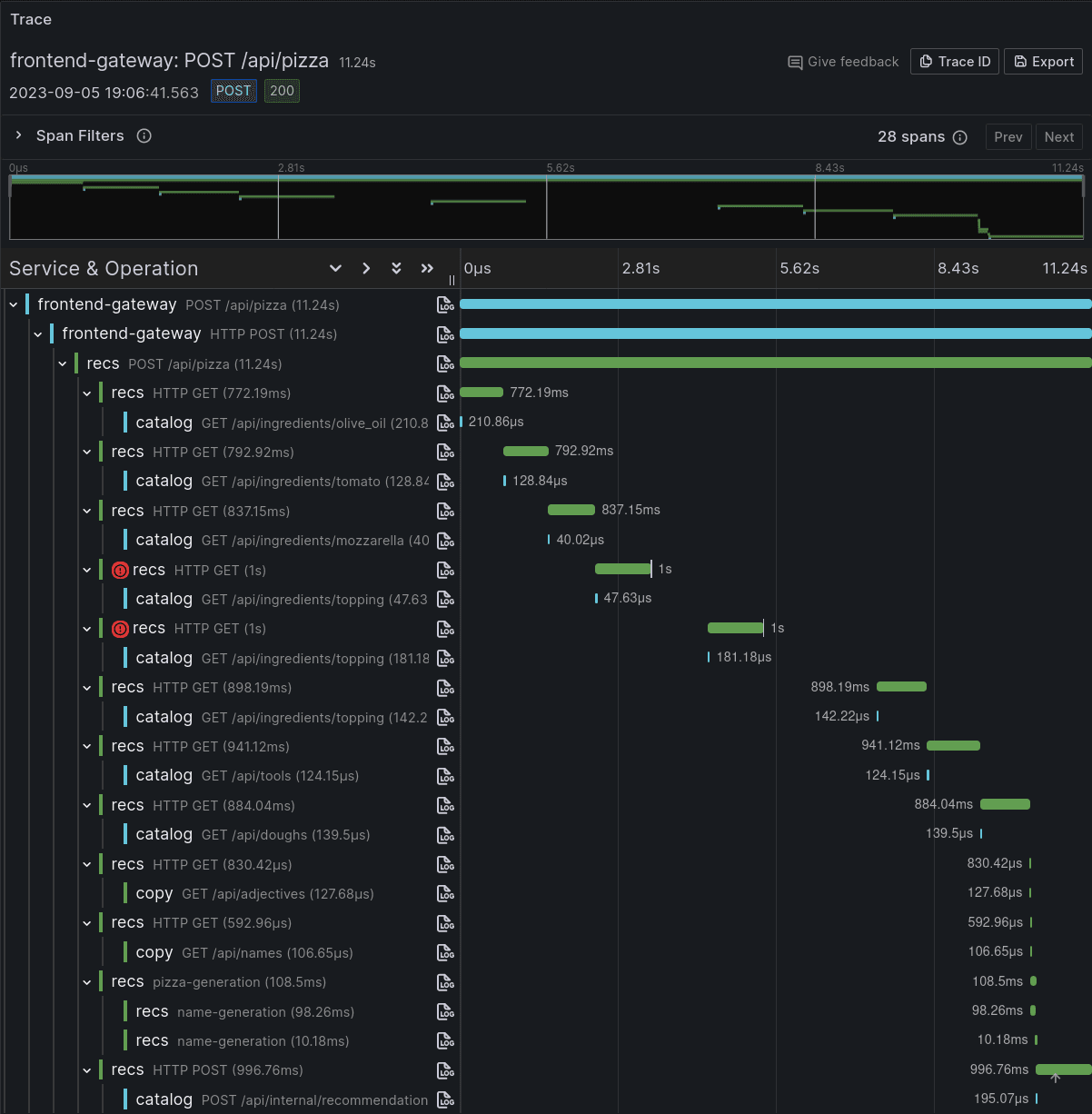
By leveraging traces again, the team could check how the service behaves regarding disruptions. The Trace view below shows how the request to /api/ingredients/topping times out two times in a row, and how the service retries up to a third time. In the timeline view, the team also saw that there is a one-second interval between the request and the first retry, and two seconds between the first and the second retries, indicating the backoff mechanism worked as intended.
Final word and next steps
As illustrated above through our 🍕 QuickPizza example, we believe xk6-disruptor is a useful tool for software and platform engineers to improve the reliability of their applications through testing.
You can learn more about xk6-disruptor by reviewing our project page, GitHub repo, and technical documentation, as well as by watching k6 Office Hours #74 and #92 on YouTube. You can also reach out to us in the Grafana Community forums for more information and guidance. Happy testing!

