
Managing Prometheus cardinality in Grafana Cloud: Adaptive Metrics FAQ
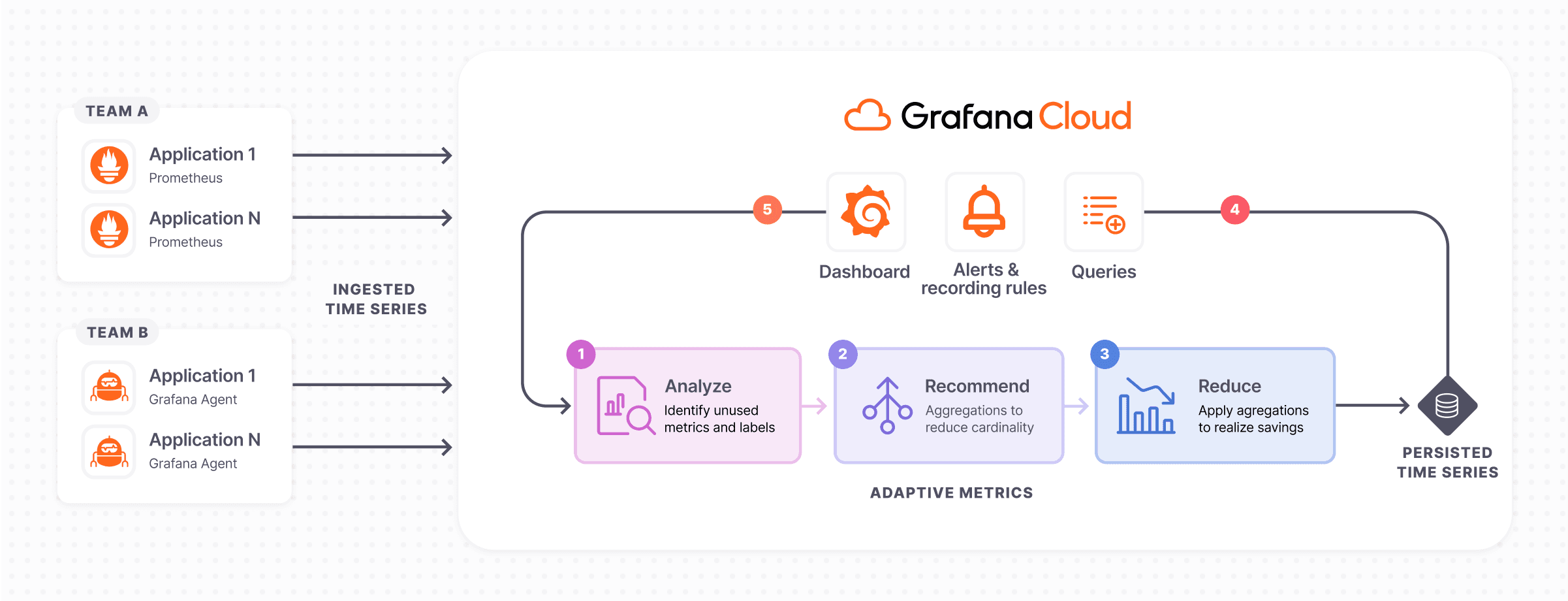
One of the most talked about topics in observability today is centered around the question of how to get more value out of the ever-increasing amount of data collected by agents, collectors, scrapers, and the like. Back in May, we announced Adaptive Metrics, a new feature in Grafana Cloud that allows you to reduce the cardinality of Prometheus metrics and the overall volume and costs of your metrics.
In our recent webinar “Grafana Cloud Adaptive Metrics: Reduce Prometheus high cardinality metrics,” we showed a live demo of how Adaptive Metrics works and how you can dramatically reduce the footprint of your metrics and save on observability data costs. During the webinar (which is now available on demand), our users also brought up a number of interesting and common questions around the issue of cardinality. In this blog post, we’d like to share some of those questions (and answers) around scaling and managing metrics with Adaptive Metrics.
Q: Can you scale to millions of metrics with Adaptive Metrics?
A: Yes, we have tested Adaptive Metrics on our internal cluster, which is running at the scale of tens of millions of metrics. We also have a growing list of Grafana Cloud users with millions of metrics and several million being aggregated, all with no impact to their operations.
Q: Can the recommendations for metric aggregations be applied automatically?
A: We do have some users who are applying their own automation using our API, by pulling down recommendations and applying them daily. The Adaptive Metrics development team is also considering adding a built-in way to apply recommendations in an automated fashion in the near future. For now, users can download recommended aggregations and then apply them through either the API or CLI.
Q: Does Adaptive Metrics use any type of machine learning?
A: Currently, the recommendations are based on data coming straight from dashboards, alerting rules, recording rules, and query logs from the past 30 days, which is generally sufficient to know what is in use and what is not. We have considered using machine learning to get even more accurate recommendations and will continue exploring any potential applications of AI/ML in the future.
Q: Doesn’t aggregation of Prometheus metrics inherently go against the fundamental principle of observability? How can we reduce our metric resolution, and thus the observability of our metrics, if we don’t know what we are looking for in the first place?
A: It’s all about trade-offs! In an optimal scenario, we would have deep visibility into every aspect of our system from all angles — and we would have unlimited budgets.
One thing is for certain: When performing aggregations on metric data, the approach needs to continuously adapt to the shape of your data and how it is being utilized. This is why our recommendations engine runs once a day and provides recommendations that are continuously evolving as your data evolves and as data access patterns change. Another important note is that aggregations can easily be unapplied, and moving forward, you’ll have access to the metrics whenever the need arises to answer certain questions from your relevant data.
Q: What types of deployment models are supported?
A: Adaptive Metrics is available in all tiers of Grafana Cloud, including our generous forever-free tier.
Q: What’s the definition of an unused metric?
A: An unused metric is one that is not being used in any alerting or recording rules or any dashboards. It has also not been queried in the last 30 days. For more information, please refer to our recent blog post on cardinality management dashboards and our recommendations documentation.
Q: Are there any guardrails in place to prevent aggregations from breaking any dashboards?
A: The way the recommendations engine works is that it analyzes all the dashboards in Grafana, so we know for certain that if a recommendation comes up, it will not break any dashboards or any queries that have been run in the last 30 days.
Q: Is there an easier way to reduce the costs due to cardinality with Grafana OSS or Prometheus?
A: Adaptive Metrics is analyzing data that is remotely written into Grafana Cloud, so it doesn’t work with any on-premises time series database you are leveraging and visualizing with Grafana. For those open source backends, there are other options available from the community. For example, Prometheus ships with a TSDB status page in the UI to help identify high cardinality metrics and labels, and Grafana Mimir provides endpoints that can identify labels with a high number of values.
Q: Do the dashboards need to be queried or is their existence enough to count the metric as used?
A: The existence of a metric-label combination in a dashboard is enough to count as being used and will not be aggregated.
Q: Could we mark some metrics to keep them because we know that we use them once a quarter or so, and the Adaptive Metrics algorithm would skip them in analysis?
A: We cannot currently bookmark metrics to keep. Recommendations rely upon whether the metric has been queried in the last 30 days, or utilized in an alerting rule, recording rule, or dashboard. But this is an interesting feature request and a potential roadmap item. Since recommendations are not applied automatically, in this case, you can simply choose not to apply the recommendation and retain the original resolution of those particular metrics.
Q: Is there a minimum threshold for when a recommendation is given?
A: Being able to control the sensitivity of when a recommendation is given has been requested from a few users and although we cannot do this at present, we might consider incorporating this feature in our upcoming roadmap.
The Grafana Labs team is thrilled to be able to help our community realize metric cost savings and would love for you to try it out yourself. To get started, sign up for a free Grafana Cloud account. If you are already a Grafana Cloud user, check out the Adaptive Metrics documentation to learn how you can apply recommendations and start improving on your metric costs today!

