New in Grafana Tempo 2.0: Apache Parquet as the default storage format, support for TraceQL
Grafana Tempo 2.0 is finally here, and it’s being released with two new important features.
It took us longer than we would have liked to get this release going, but it turns out that rewriting your backend AND building a new query language is quite difficult. Thanks to a massive team effort, we are proud to release Tempo with support for TraceQL and with Apache Parquet as the default backend storage format.
Read on to get a quick overview of this huge release. And if you’re looking for something more in-depth, don’t hesitate to jump into the changelog, release notes, or upgrade guide.
In this video from ObservabilityCON 2022, Grafana Labs previewed Tempo 2.0.
New features in Grafana Tempo 2.0
TraceQL
TraceQL is a new language designed from the ground up for discovering traces. It is inspired by LogQL and PromQL, so we anticipate users will find the learning curve to be straightforward. TraceQL gives Tempo capabilities that cannot be found in any other open source tracing solution, making it the fastest way to get precisely what you’re looking for in your traces.
Check the core concepts document for the long-term vision and the TraceQL documentation for the current feature set. But here are just a few examples of the capabilities that we’ve been excited to use internally.
With TraceQL you can easily search for all successful HTTP status codes and jump immediately to the spans matching your issue:
{ span.http.status_code >= 200 && span.http.status_code < 300 }
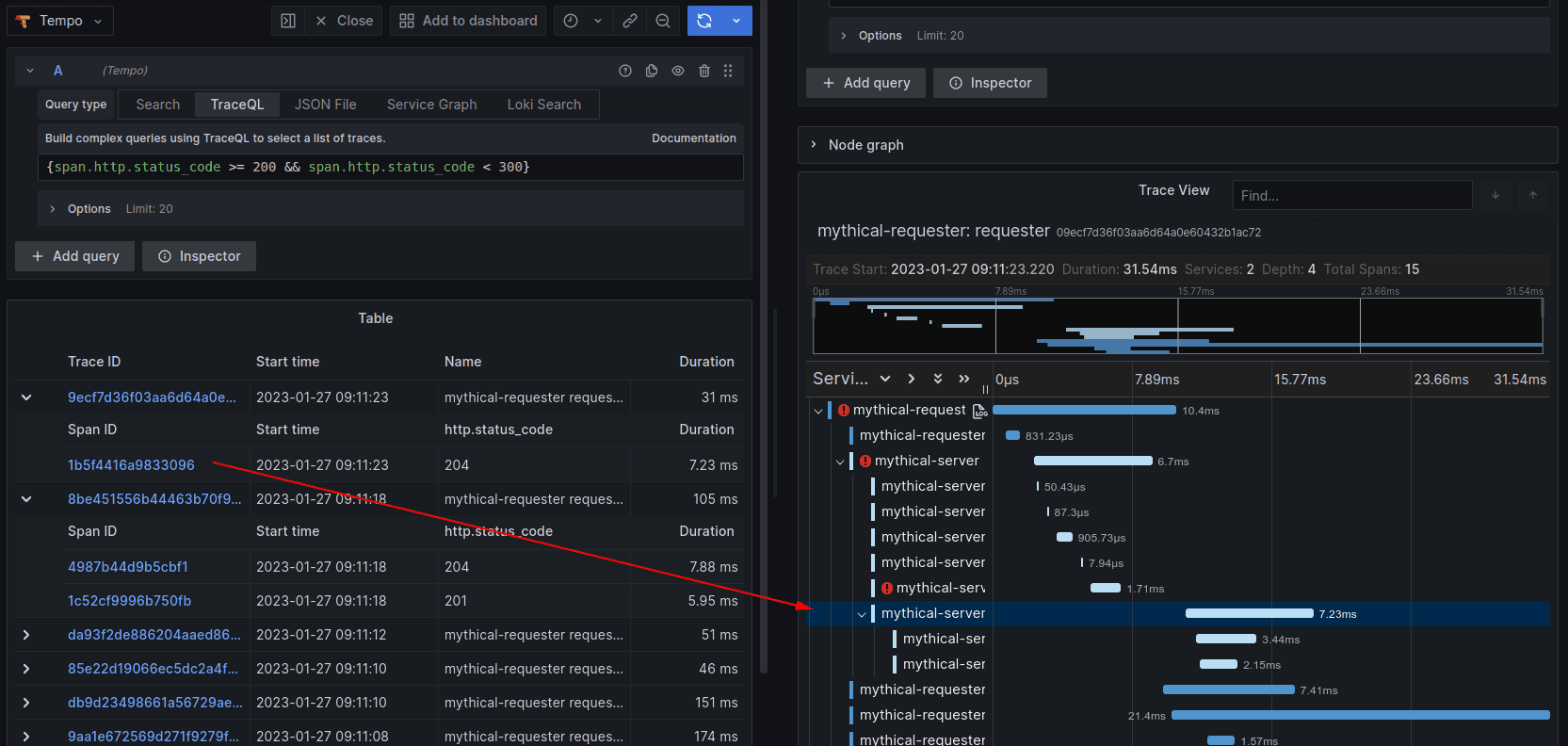
Also, while exploring our data recently with TraceQL, we found an issue with memcached timeouts in some of our internal clusters by using our average aggregator:
{ name="memcache.get" } | avg(duration) > 100ms
We’ve also been able to track down and eliminate low value traces using count:
{ } | count() < 3
TraceQL is just getting started. We have a lot of functionality on the horizon and we’re already getting a ton of value out of it. The best TraceQL experience can be found in Grafana 9.4. Grafana 9.3 also has a functioning TraceQL editor, but results may vary.
The next few releases will continue to add capabilities, and if you’re interested in participating in prioritizing the roadmap, join us in our monthly community calls!
Apache Parquet
The second major feature we are excited about in Tempo 2.0 is the Apache Parquet trace storage backend. The new default backend will store your trace data in an open and easily consumable format.
There is an entire ecosystems of databases, batch/stream processing, and querying engines that can work directly with data in the Parquet format. With Tempo, we’re striving to build a comprehensive distributed tracing database, but we also want you to be able to build the tools and gather the insights that work for you. With Tempo 2.0 your tracing data will no longer be locked inside a proprietary format or hidden away in a vendor’s backend. Go make something awesome with your tracing data!
Previous iterations of Tempo used a format we call v2 that was incredibly efficient at storing and retrieving traces by ID. Parquet is more costly due to the extra work of building the columnar blocks, and operators should expect at least 1.5x increase in required resources to run a Tempo 2.0 cluster.
Most users will find these extra resources are negligible compared to the benefits that come from the additional features of TraceQL and from storing traces in an open format. However, Tempo is committed to its original vision of being a highly efficient trace by ID store. If this is your bag, check out the documentation on how to continue running v2.
Please Note: there is a potential issue loading Tempo 1.5’s experimental Parquet storage blocks. You may see errors or even panics in the compactors. We have only been able to reproduce this with interim commits between 1.5 and 2.0, but if you experience any issues please report them so we can isolate and fix this issue.
Bug fixes
We may have fixed a few bugs in Tempo 2.0.
- PR 1887 Stop distributors on OTel receiver fatal error
- PR 1700 New wal file separator ‘+’ for the NTFS filesystem and backward compatibility with the old separator ‘:’
- PR 1781 Make multitenancy work with HTTP
- PR 1799 Fix parquet search bug fix on http.status_code that may cause incorrect results to be returned
- PR 1920 Fix docker-compose examples not running on Apple M1 hardware
- PR 1947 Don’t persist tenants without blocks in the ingester
- PR 2003 Return more consistent search results by combining partial traces
Breaking changes
Tempo 2.0 has a number of breaking changes from v1.5. We took the opportunity of the major version bump to do some cleanup of our configuration. Additionally, we adjusted defaults for a number of configuration options to better work with Apache Parquet. To keep this blog post from exploding in size, we are only going to list the renamed configuration options. Please refer to the release notes for a complete list.
search_enabled: // removed and defaults to true
metrics_generator_enabled: // removed and defaults to true
query_frontend:
query_shards: // removed. use trace_by_id.query_shards
querier:
query_timeout: // removed. use trace_by_id.query_timeout
compactor:
compaction:
chunk_size_bytes: // renamed to v2_in_buffer_bytes
flush_size_bytes: // renamed to v2_out_buffer_bytes
iterator_buffer_size: // renamed to v2_prefetch_traces_count
ingester:
use_flatbuffer_search: // removed. automatically set based on block type
storage:
traces:
wal:
encoding: // renamed to v2_encoding
block:
index_downsample_bytes: // renamed to v2_index_downsample_bytes
index_page_size_bytes: // renamed to v2_index_page_size_bytes
encoding: // renamed to v2_encoding
row_group_size_bytes: // renamed to parquet_row_group_size_bytes
storage:
trace:
azure:
storage_account_name: // all fields set to snake_case
storage_account_key:
container_name:
What’s next in Grafana Tempo?
TraceQL all day, every day. We have a ton of upcoming features and the team is excited to grow into our new language. Additionally, we will likely continue to push performance improvements and scaling options for those who are operating in the hundreds of MB/s range.
With the release of 2.0, it feels like Tempo is just hitting its stride. An Apache Parquet backend to support an amazing new query language OR a highly performant trace by ID backend for those looking for a massive trace warehouse. Do what you will! Your traces are yours!
Happy tracing!
If you are interested in more Grafana Tempo news or search progress, please join us on the Grafana Labs Community Slack channel #tempo, post a question in our community forums, reach out on Twitter, or join our monthly community call. See you there!
And if you want to get even closer to where the magic happens, why not have a look at our open positions at Grafana Labs?
The easiest way to get started with Grafana Tempo is with Grafana Cloud, and our free forever tier now includes 50GB of traces along with 50GB of logs and 10K series of metrics. You can sign up for free!