New in Grafana Mimir: Introducing out-of-order sample ingestion
Traditionally the Prometheus TSDB only accepts in-order samples that are less than one hour old, discarding everything else. Having this requirement has allowed Prometheus to be extremely efficient with how it stores samples. And in practice, it really hasn’t really been much of a limitation for users because of the pull-based model in Prometheus, which scrapes data at a regular cadence off of the targets being observed.
Several use cases, however, need out-of-order support. For example:
- IoT devices waking up asynchronously and writing metrics.
- Complex metric delivery architectures using message buses like Kafka with randomized sharding and delay due to congestion.
- Standalone Prometheus instances isolated from a network connection for some time trying to push old samples.
As Prometheus continues to be adopted in new fields and industries, the limitation of in-order sampling poses an increasingly hard problem. Our solution? Grafana Mimir 2.2 was recently released with experimental support to accept out-of-order samples. This feature is also available to Grafana Enterprise Metrics customers using Grafana Enterprise Metrics v2.2 or above. In this blog post, we will see how this experimental feature works and how to use it in Grafana Mimir.
Designing out-of-order support
We along with Dieter Plaetinck wrote a design document for solving the out-of-order problem that was shared with the Prometheus community.
Here is a high-level description of how it works.
Ingestion
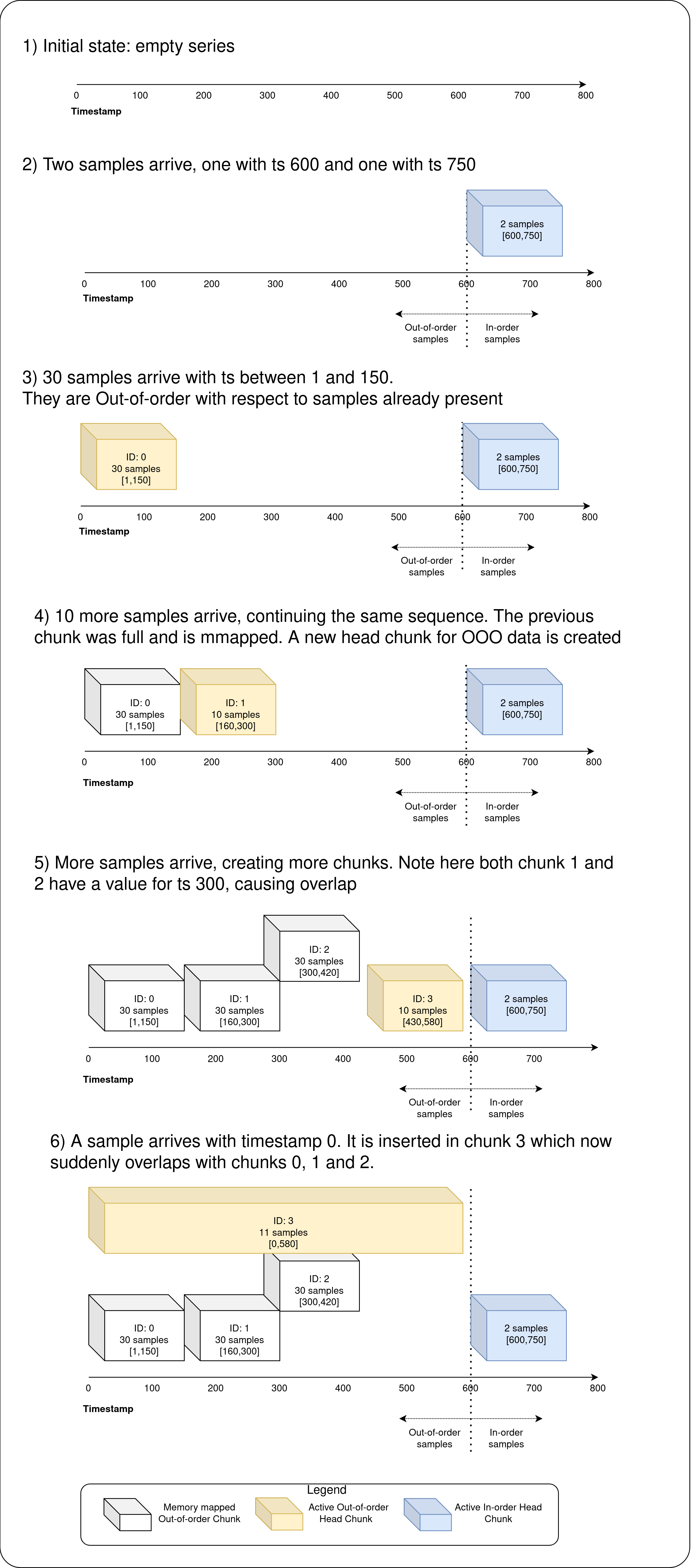
Prometheus TSDB has an in-memory part called the head block. We share the head block to not duplicate the in-memory index, which helps decrease memory consumption. For every time series in the head block, we store the last 30 out-of-order samples uncompressed in the memory, totally isolated from the in-order samples. After the in-memory chunk has reached 30 out-of-order samples, it is compressed and flushed onto the disk and memory-mapped from the head block.
This is similar to how the head block usually handles in-order samples: In-order samples in the memory stay in a compressed chunk and up to 120 samples are stored. Since in-memory, out-of-order chunks have uncompressed samples in memory, we limit the number to 30 samples as a measure to avoid high memory consumption.
We have also introduced a new artifact called a Write-Behind-Log (WBL). WBL is similar to the Write-Ahead-Log (WAL) present in the Prometheus TSDB. In WBL, the data is written after adding samples to the TSDB; in WAL data is written before making any changes to the TSDB. We use the WBL to record the out-of-order samples that were ingested, because until the ingestion actually happens, we cannot be sure if the sample was in-order or out-of-order.
Below is a diagram visualizing the process. Note that the out-of-order chunks can both overlap in time with each other and also with in-order chunks. (In the diagram: OOO = Out of Order)
Querying
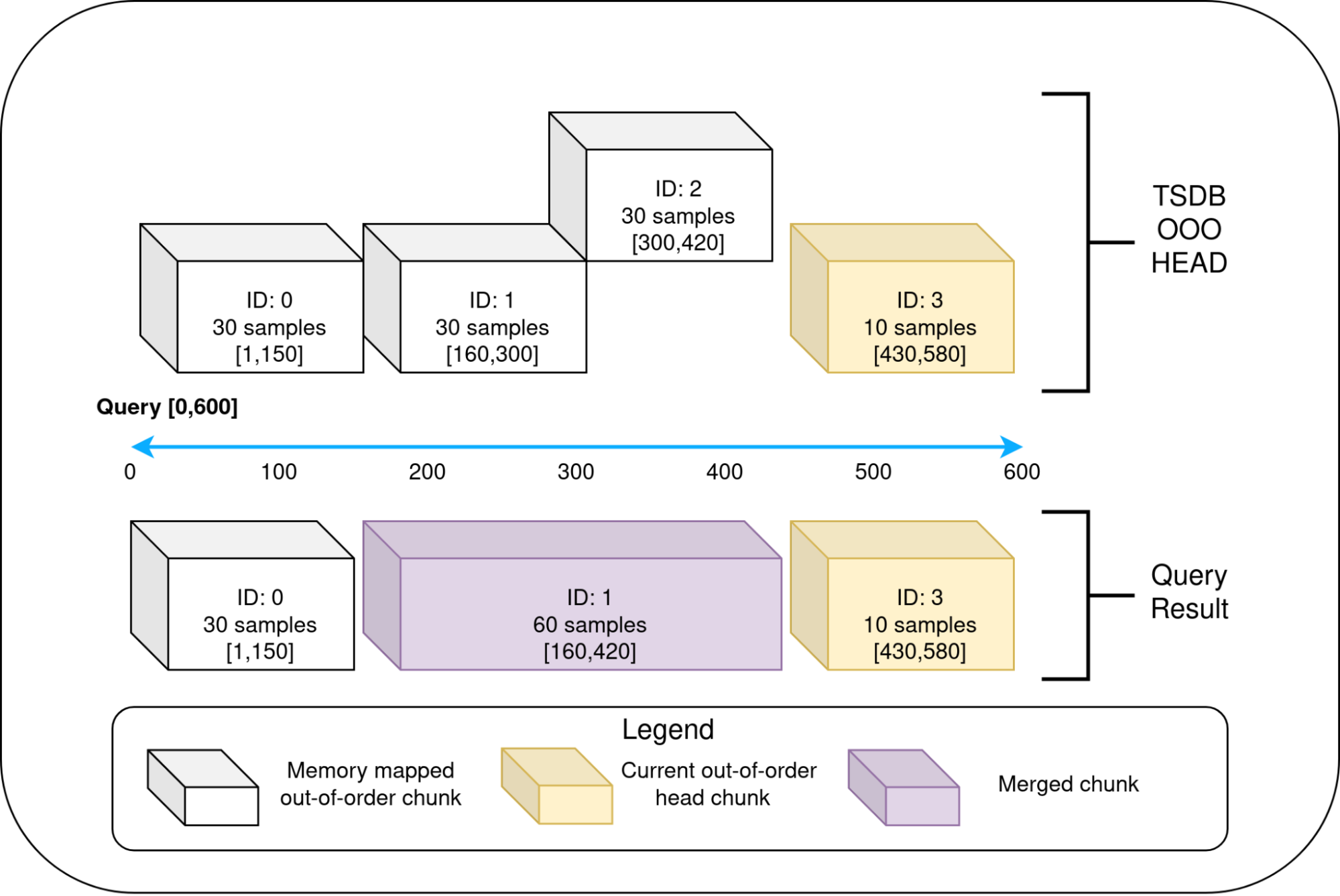
The Prometheus TSDB has useful abstractions where the querier sees everything as a “block reader” for both the head block and the persistent block that are on the disk. The TSDB already uses a wrapper around the head block to read the in-order data from the head in a fixed time range. Similarly, we implemented another wrapper around the head block that only reads the out-of-order chunks. This way, using the abstractions, the head block can be represented as two block readers: one that only reads the in-order data and another that reads only the out-of-order data.
The existing querying logic seamlessly takes care of merging the results from both the block readers and other persistent blocks. However, the querier requires the block readers to provide non-overlapping chunks in a sorted order. Hence, the out-of-order block reader for the head merges the overlapping chunks during a query as seen in the diagram below. The merging happens in flight when accessing the samples. The chunks, however, are not recreated. (In the diagram, OOO = Out of Order)
Compaction
The persistent blocks in the TSDB are aligned to a 2-hour Unix timestamp. Every 2 hours, for the in-order data, we take the oldest 2 hours of data from the head block and turn it into a persistent block. This is called a compaction of the head block. Right after the in-order data is compacted, the out-of-order data is also compacted.
Due to the nature of out-of-order data, it can contain samples that span multiple 2-hour block ranges. Hence, we produce multiple persistent blocks as necessary during a single compaction of out-of-order data as visualized below. These persistent blocks are like any other persistent block. After compaction, WBL and other artifacts are cleaned up as necessary. These blocks can overlap in time with existing blocks on the disk or even the in-order data in the head block.
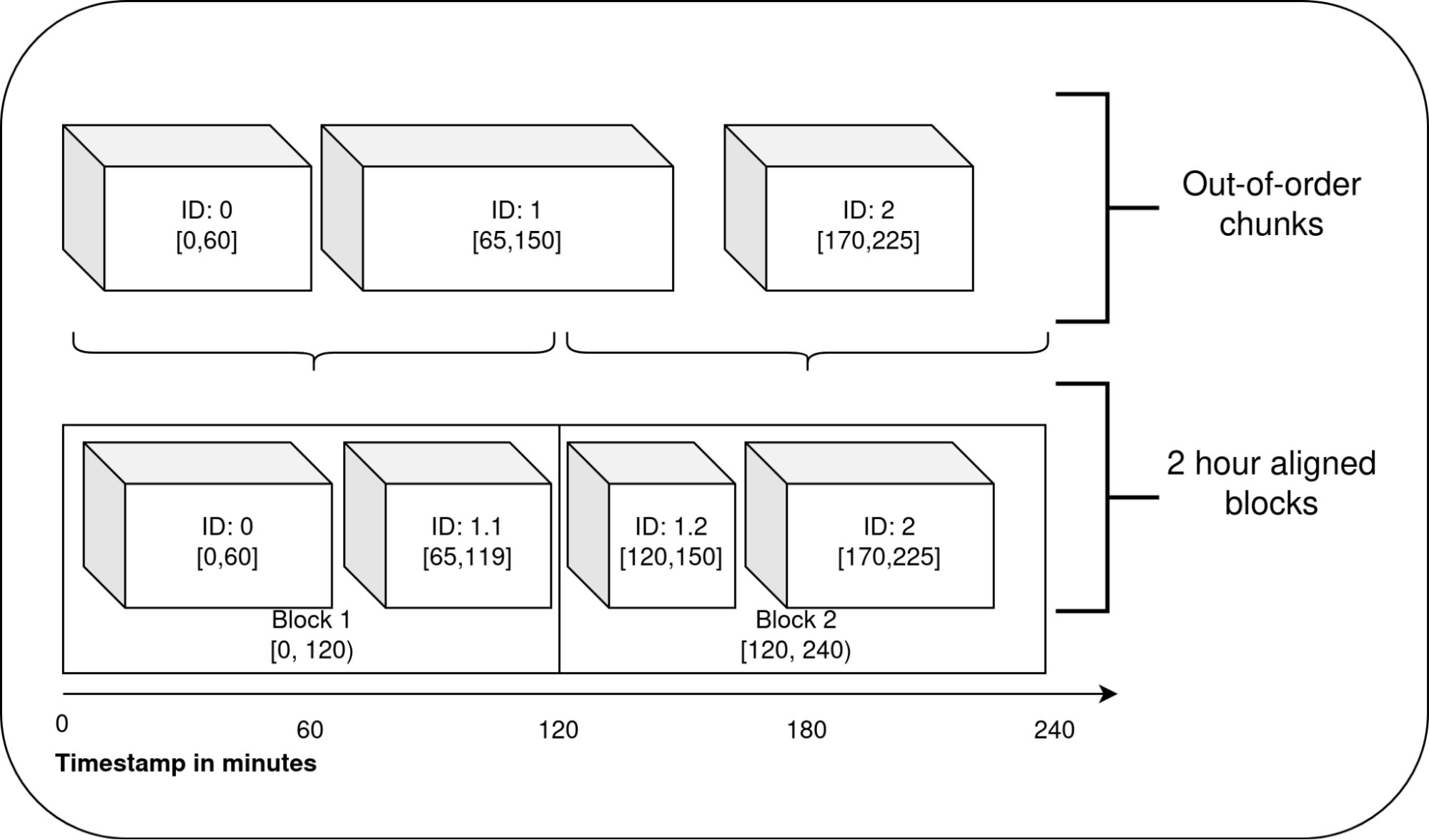
Once these blocks are produced, the role of out-of-order code ends. The TSDB is already capable of querying data from overlapping blocks and also merging overlapping blocks as necessary.
Out-of-order sample ingestion in Grafana Mimir and Grafana Cloud
We have introduced a new configuration parameter called out_of_order_time_window to specify how old an out-of-order sample can be. By default, it is set to 0 so no out-of-order samples are allowed. If you set this parameter to 1 hour, for example, Grafana Mimir will ingest all the out-of-order samples that are within the last hour, which would have been discarded earlier.
You can learn more about how to enable out-of-order support in Grafana Mimir 2.2 and later versions in our Grafana Mimir documentation.
We have already enabled out-of-order support in Grafana Cloud for some users who beta-tested this feature. The out-of-order support feature will be enabled for all Grafana Cloud users by default after more testing. The initial configuration will allow the out_of_order_time_window value to be up to 10 minutes.
For Grafana Cloud users interested in learning more about the out-of-order support feature, please open a support ticket.
Contributing out-of-order support upstream
All the above work was done in the grafana/mimir-prometheus GitHub repository that Grafana Mimir uses instead of upstream Prometheus. This allowed us to experiment more and identify problems earlier by running in our cloud environments.
Now that we have beta-tested this feature in production for some of our users at a decent scale — and fixed some critical issues — we are excited to introduce this experimental feature to more users. We have already opened a PR to contribute this upstream.
Performance characteristics
We have seen vastly different performance characteristics depending on:
- The pattern of out-of-order ingestion.
- The number of series getting out-of-order samples.
- The rate of out-of-order samples being ingested.
In many cases, there is an increase in CPU usage in ingesters that actually does all the above out-of-order sample handling. With the limited number we have, we have seen anywhere between no change in CPU and also as high as 50% more CPU on ingesters where the rate of out-of-order samples processed (ingestion and querying) was quite high. Note that no other component in Grafana Mimir was affected.
The increase in memory usage was not noticeable in our environments. However, this will change if you have a high volume of out-of-order samples incoming for a large percentage of the time series. The overall increase should still be minor.
Conclusion
With the introduction of out-of-order support, Grafana Mimir can now accept time series data from any metrics system that requires old samples to be ingested. This makes Grafana Mimir a general purpose TSDB, beyond just a long-term storage for Prometheus. See this blog post on the Grafana Mimir proxy to learn more about how a single backend of Grafana Mimir can accept Graphite, Datadog, Influx, and Prometheus metrics.