Bootstrapping a cloud native multi-data center observability stack
Bram Vogelaar is a DevOps Cloud Engineer at The Factory, and he recently delivered an intro to observability talk during our Grafana Labs’ EMEA meetup.
When I talk to customers, they might tell me about how their applications are running in two data centers, but when we probe a little further, it turns out that their observability stack is only available in one of them.
This revelation hit close to home last March. One of Europe’s largest cloud services providers OVHcloud experienced a massive fire in one of its data centers, which caused a huge outage among prominent clients such as the French government.
The day after the incident, my colleague who oversees quality management asked me if we could survive a similar disaster. This triggered me to look into evolving our single observability stack into a high availability one across multiple data centers.
Thankfully tools we use such as Grafana Tempo for tracing and Grafana Loki for logging are able to replicate across a microservices setup. But could we run multiple instances in multiple data centers? And are we in a place where we could lose a component or an entire campus “comfortably”? (i.e., will we still have the ability to view what’s going on in our applications?)
At a recent Grafana Labs EMEA meetup, I walked through the cloud native multi-data center observability stack we deployed so the answers to all of our above questions were “yes!”
Below is a breakdown of the process.
Introducing Consul
I evolved my observability stack and introduced Consul, an open source service discovery tool with a built-in key value store and service mesh tooling that’s built and maintained by HashiCorp.
We can announce services into Consul by defining Grafana as a consul service in the following JSON blob:
{
"service":
{
"checks":[{"http":"http://localhost:3000","interval":"10s"}],
"id":"grafana",
"name":"grafana",
"port":3000,
"tags":["metrics"]
}
}It will allow Consul to check on the health of the service by sending an http request to the local host and announcing the service to the rest of our platforms when healthy. Once configured, we can query Consul like any other DNS server asking for the whereabouts of your service.
dig @127.0.0.1 -p 8600 grafana.service.consul ANYYou can even incorporate Consul into your data centers’ bind or unbound DNS server.
Connecting Consul clusters
Consul can be made multi-data center aware by federating clusters, but it always uses the data from the cluster in the local data center for key value store and service queries. In our example, we have two data centers — simply called DC1 and DC2 — that are connected.
When connected, the Consul clusters are aware of each other, but a DNS query will not automatically go from one cluster to the other. For that we need a prepared query, which can be built by posting the following JSON blob to your Consul server using curl.
curl http://127.0.0.1:8500/v1/query --request POST --data @- << EOF
{
"Name": "grafana",
"Service": {
"Service": "grafana"
"Failover": {
"Datacenters": ["dc2"]
}
}
}
EOFThe above prepared query called “grafana” will set up the two clusters so that in case of a failure in DC1, the DNS request will be forwarded to DC2. For the Grafana service in DC2, we set up the opposite query. In either scenario, if there is a disruption in services, it will automatically failover to the other side without anyone noticing, except for the brief time lapse in which Consul needs to work out that your service is down in your local data center.

Connecting Grafana instances
Now I needed some way to have the two Grafana instances communicate with each other. Grafana has three database backends: SQLite, PostgreSQL, and MySQL. SQLite is a database that uses a local file on disk and that obviously doesn’t scale. PostgreSQL has no open source main-main replication so there will always be a primary data center and a secondary data center with lags in data being written. So my database of choice would be MySQL, which has main-main replication. Grafana will then always write to the local MySQL, which is then copied to the other instance and vice versa.
Next up is updating your data sources in Grafana. Instead of pointing those towards your local Loki or Prometheus directly, you can easily use the DNS entry that was created with the prepared query as each data source (e.g., loki.query.consul:3100 instead of 192.168.43.40:3100)
Connecting Prometheus
How should we achieve high availability in Prometheus? Do we do federation? Do we read twice? Do we write twice?
For this solution, I’m proposing the following: Prometheus, conveniently, has a built-in Consul service discovery option. So instead of having a long list of targets to scrape, I changed the DC1 configuration so it uses my local Consul cluster to discover all services announced in DC1 that have the tag “metrics” and those will be scraped. Therefore, everything that’s in Consul with the right tag is automatically scraped into Prometheus and from there you can build your dashboards. For DC2, we copy the config and replace DC1 with DC2.
- job_name: DC1
scrape_interval: 10s
consul_sd_configs:
- server: localhost:8500
datacenter: dc1
tags:
- metrics
- job_name: DC2
...Connecting Grafana Loki
For Grafana Loki, the solution is simple: You can configure your local Promtail to push your logs to two endpoints. (Note: I use the IP addresses instead of the queries here because I want to be sure I write it twice.)
clients:
- url: https://192.168.43.40:3100/loki/api/v1/push
- url: https://192.168.43.41:3100/loki/api/v1/pushConnecting Grafana Tempo
Grafana Tempo was the most challenging tool to configure. We asked a lot of the same questions we did throughout the stack: Send twice? Write twice? Read twice?
Then the question became: Do we introduce a proxy?
And here’s where the Grafana Agent configuration comes in:
tempo:
configs:
- name: default
receivers:
zipkin:
remote_write:
- endpoint: 192.168.43.41:55680
- endpoint: 192.168.43.40:55680In Grafana Agent v0.14, they released `remote_write` for Tempo, making it an excellent proxy and exactly what we needed.
In our use case, instead of pushing directly to Tempo, all my tracing agents use Grafana Agent as an endpoint, and then they remote write into both my Tempo instances. That requires a bit of a change in the config: Grafana Agent now has a receiver, in this case Zipkin, and I write into two different endpoints. One is my local data center, the other in the second (failover) data center.
Now we will be using a receiver for the OpenTelemetry data, listening on different endpoints and different ports so make sure your firewalls are adjusted accordingly. (Trust me, those were two hours of my life I’ll never get back!)
distributor:
receivers:
zipkin:distributor:
receivers:
otlp:
protocols:
grpc:Connecting Alertmanager
For the Alertmanager HA, it’s much simpler! You start with an additional flag that basically says, I am a cluster, and my peers live on the following ports. Then they start communicating and de-duplicating alerts. In Prometheus, you need to add an extra target to your prometheus.yaml file.
[Unit]
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yaml \
--storage.path=/var/lib/alertmanager \
--cluster.advertise-address=192.168.43.40:9094 \
--cluster.peer=192.168.43.41:9094alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.43.40:9093
- 192.168.43.41:9093Conclusion
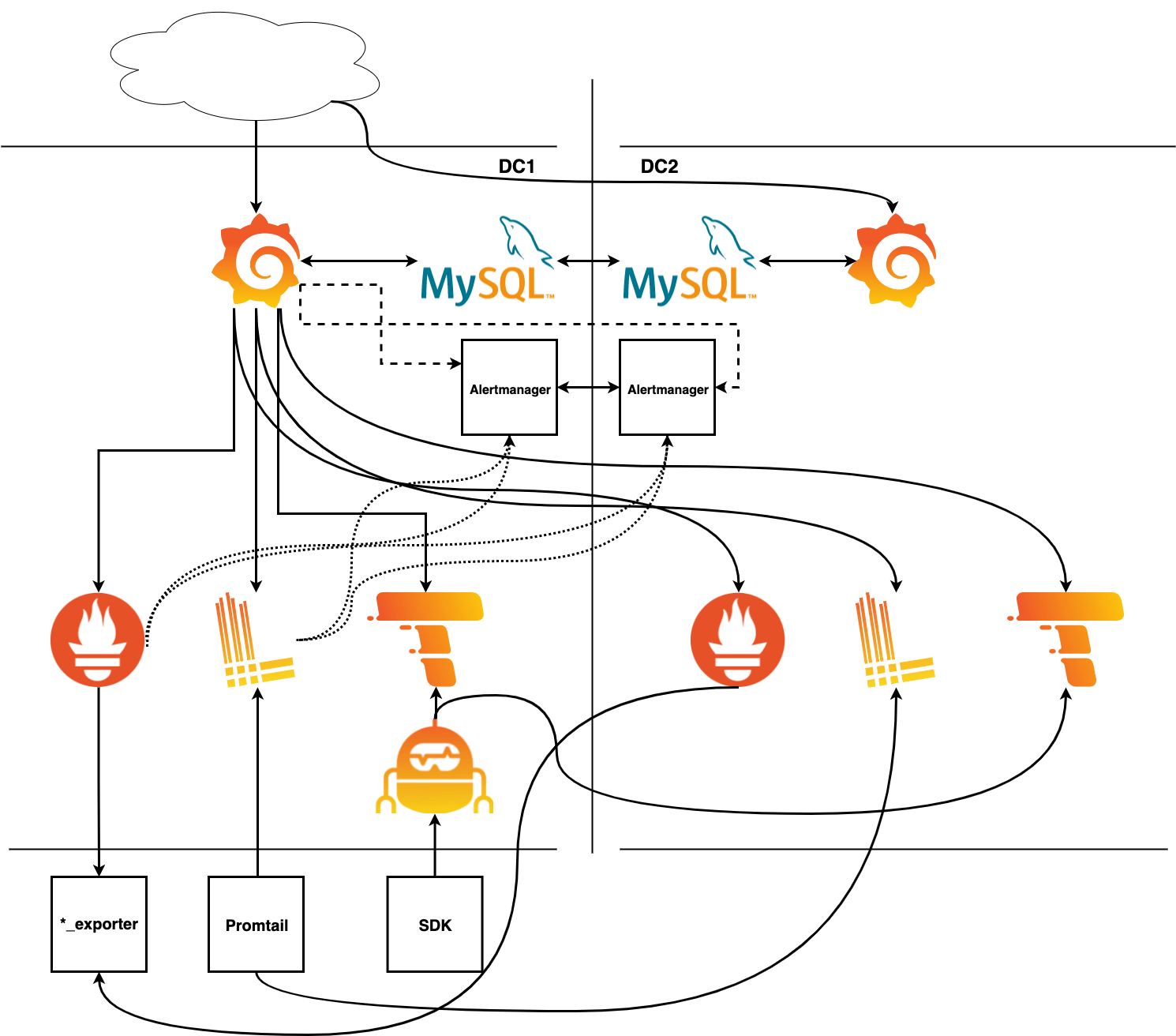
In my fully duplicated observability setup, I didn’t have to copy all the lines of code because that would basically become one big hot mess. Instead I’ve added all the additional lines necessary and all the key components to have the same stack running in two different data centers. Now I can kill any element, or an entire data center, knowing I’ll still have a fully functioning observability stack.
Keep up with the Grafana Agent open source project on GitHub and join the discussion in the #agent channel on the Grafana Labs Community Slack.
Want to share your Grafana Agent tips with the community? Drop us a note at stories@grafana.com.