

How we live-migrated massive Cortex clusters to blocks storage with zero impact to Grafana Cloud customers
January 20, 15:01 UTC. I was sitting in my home office, watching the screen and feeling a mix of emotion and nostalgia as a pod was getting terminated.
We have thousands of pods, continuously starting and terminating, and I’m definitely not spending my days watching them, so why was this one special? The terminating ingester-0 pod was the very last Cortex ingester running on chunks storage in Grafana Labs’ infrastructure. It was the watershed between the old and the new, the past and the future.

Today I want to share with you the story of how we live-migrated dozens of Cortex clusters between two different storage engines with zero impact on our customers.
The need for a plan
As a software engineer, I’m both fascinated and genuinely scared by databases. They’re typically complex, mission-critical systems storing large amounts of data, and there’s always the specter of data loss.
Cortex, the open source project for scaling Prometheus that powers Grafana Cloud Hosted Metrics, is no exception. A lot of companies of all sizes rely on Grafana Cloud Hosted Metrics as the core of their observability stack, and an incident in our service would seriously impact their operations. Stakes are high.
In my role as a Cortex maintainer, I spent much of 2020 working on a new blocks storage engine, and by the middle of the year, things were shaping up. At Grafana Labs, we started planning for a production rollout. We were already using it internally, and this was giving us some confidence on stability, correctness, and performances, but that was not enough. We wanted higher confidence before migrating our production clusters.
We needed a plan.
Raising confidence
That’s when we came up with the idea to use shadow clusters.
We selected a production cluster, set up a parallel Cortex cluster running on blocks storage, and mirrored all production traffic to the shadow one. And we did it for multiple clusters.
We used Envoy HTTP traffic mirroring features to mirror writes to the shadow cluster and built a Cortex query-tee service to mirror reads, and compared query response times and results. We basically made the old chunks storage and the new blocks storage compete in terms of performance, while confirming that query results matched. On response time, blocks storage queries outperformed chunks.
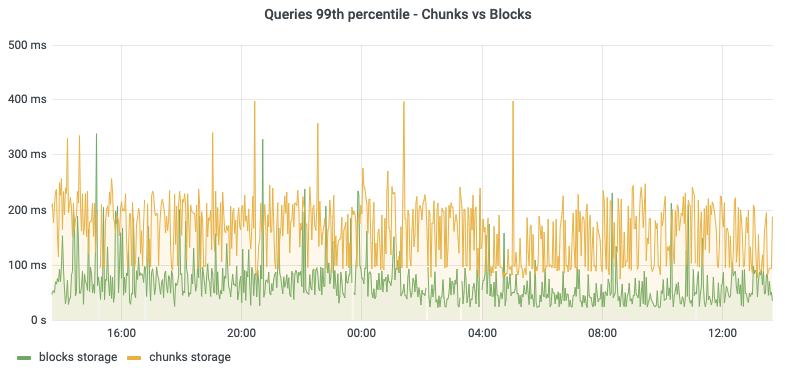
Running a shadow cluster is an expensive testing approach, but in my opinion, it’s the definitive solution to raise the trust level. After running the shadow cluster for several weeks, we reached the turning point and had enough confidence to begin the production migration.
The live migration
Cortex receives incoming series – pushed by Prometheus or the Grafana Agent – into a service called the distributor, which shards and replicates the series across a pool of ingesters.
An ingester keeps the series in memory and periodically flushes these series to long-term storage. At query time, the querier fetches most recent series samples from ingesters and older data from the storage.
To live-migrate a Cortex cluster from chunks to blocks, we had to switch ingesters to write blocks instead of chunks and queriers to read series from both chunks and blocks (either they’re coming from ingesters or the long-term storage), and merge and deduplicate samples at query time.
And that’s what we did! We introduced in Cortex a feature to configure a secondary storage engine to query, we configured queriers to query both chunks and blocks, and then we progressively rolled out a configuration change in the ingesters to switch from chunks to blocks. During the rolling update, an ingester was flushing all chunks to the storage on shutdown and restarted with a new configuration to store newly received series using blocks.
We tested the procedure countless times. We injected failures during testing. We prepared an emergency rollback procedure, and we tested it multiple times too.
It was a long but controlled process. It took days for each cluster. It was exhausting, but definitely rewarding!
The massive long-term storage migration
At this point you may ask: What about the historical data in the long-term storage?
We had two options: keep it stored as chunks and let it fade away once the retention period expired, or convert all chunks to blocks. Unfortunately, the first one was not really an option.
The chunks storage is significantly more expensive than the blocks one, and we have some features (like queries without a metric name) that are only supported by the blocks storage. We didn’t really want to keep legacy chunks around, preventing us from continuing to innovate on the blocks storage.
The only real option was to rewrite all the historical data from chunks to blocks. That’s a massive operation. We’re talking about huge amounts of data and… guess what? We’ve built a distributed system to migrate data in a distributed system. Inception!
That’s how the blocksconvert tool was born. It’s basically a horizontally scalable system in which a scanner produces a plan of the work that needs to be done, and then a scheduler distributes the work to a pool of builders.
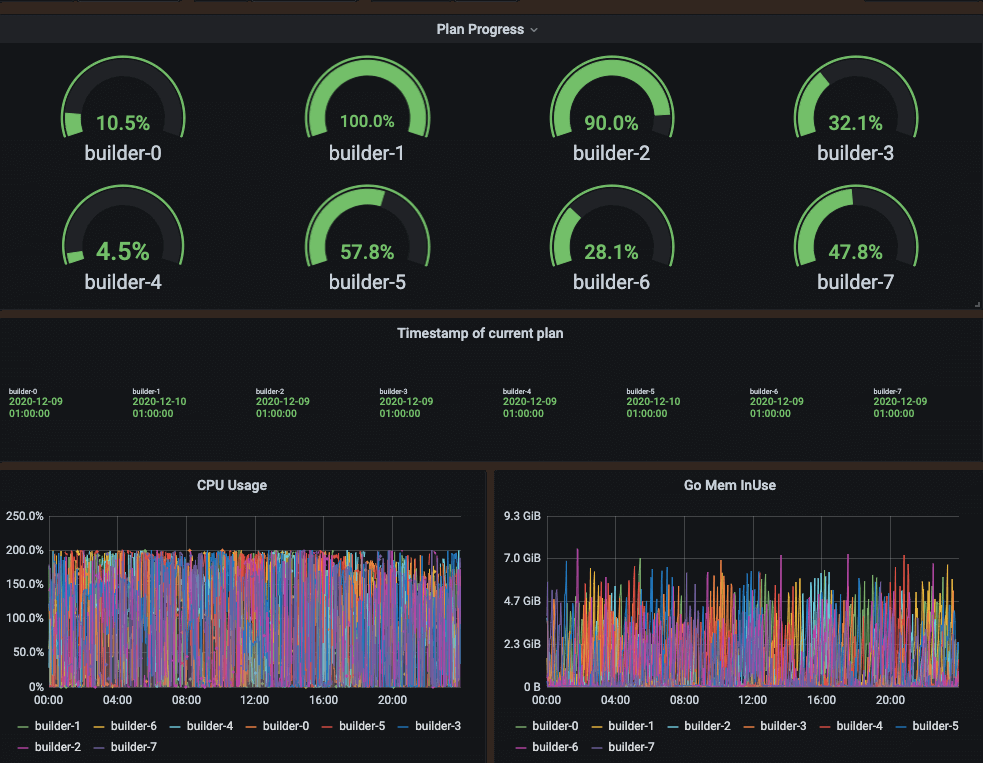
We ran the conversion for months. We started small, we tested the correctness, we fixed bugs and bottlenecks, and then we progressively scaled up. And last week, along with the last cluster migration, we finished converting the whole long-term storage to blocks!
Execution is everything
The Cortex blocks storage development started back in late 2019. That’s almost a year and a half ago. It was a huge effort both from Grafana Labs and the community.
We built it iteratively. We started with a proof of concept, we validated our ideas, and we found and fixed countless bugs, scalability, and performance issues. Along the way, we had to build a bucket index on top of the object storage to overcome rate limits, and we introduced shuffle sharding to scale out a Cortex cluster to a large number of tenants, isolating their workloads.
In retrospect, the migration to blocks was meticulously planned and patiently executed. I’m very proud of the work done by the community and Grafana Labs, and I’m very excited about the future work we’re currently brainstorming on.
Stay tuned! The blocks storage was just the beginning of a shiny future for storing and querying Prometheus metrics at scale! (And if this work sounds exciting to you, we’re hiring.)
We’ve just announced new free and paid Grafana Cloud plans to suit every use case — sign up for free now.


